DRBD(一) DRBD详解 及 DRBD配置
DRBD(一) DRBD详解 及 DRBD配置
在前面《高可用集群》认识高可用集群的一些基本概念,在《heartbeat v2 crm 及 NFS共享存储的mysql高可用集群》等文章全面认识了用heartbeat v2 配置高可用集群,以及在《corosync pacemaker 配置高可用集群》识别了corosy+pacemaker配置高可用集群,下面将会全面认识DRBD, 并进行DRBD基本配置,下篇会用到DRBD配置mysql高可用集群。
1、认识DRBD
DRBD(Distributed Replicated Block Device,分布式复制块设备)是一个用软件实现的、无共享的、服务器之间镜像块设备内容的存储复制解决方案。DRBD是镜像块设备,是按数据位镜像成一样的数据块。
简单说DRBD是实现活动节点存储数据更动后自动复制到备用节点相应存储位置的软件。
1-1、DRBD工作原理
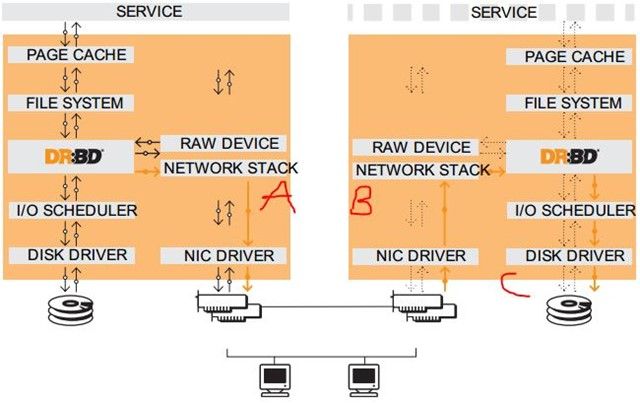
上图是官方文档里给出的DRBD工作栈模型,可以看到DRBD需要运行在各个节点上,且是运行在节点主机的内核中,所以DRBD是内核模块,在Linux2.6.33版本起开始整合进内核。
上图假设左节点为活动节点(实箭头),右节点为备用节点。左节点接收到数据发往内核的数据通路,DRBD在数据通路中注册钩子检查数据(类似ipvs),当发现接收到的数据是发往到自己管理的存储位置,就复制另一份,一份存储到本机的DRBD存储设备,另一份就发给TCP/IP协议栈,通过网卡网络传输到另一节点主机的网上TCP/IP协议栈;而另一节点运行的DRBD模块同样在数据通路上检查数据,当发现传输过来的数据时,就存储到DRBD存储设备对应的位置。
如果左节点宕机,右节点可以在高可用集群中成为活动节点,当接收到数据先存储到本地,当左节点恢复上线时,再把宕机后右节点变动的数据镜像到左节点。
镜像过程完成后还需要返回成功/失败的回应消息,这个回应消息可以在传输过程中的不同位置返回,如图上的A/B/C标识位置,可以分为三种复制模式:
A:Async, 异步,本地写成功后立即返回,数据放在发送buffer中,可能丢失,但传输性能好;
B:semi sync, 半同步;
C:sync, 同步,本地和对方写成功确认后返回,数据可靠性高,一般都用这种;
1-2、DRBD 支持的底层设备
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一块物理的磁盘,可以在DRBD设备内创建文件系统。
DRBD所支持的底层设备有这些类别:磁盘,或者是磁盘的某一个分区;soft raid 设备;LVM的逻辑卷;EVMS(Enterprise Volume Management System,企业卷管理系统)的卷;或其他任何的块设备。
1-3,DRBD资源
DRBD资源为DRBD管理的存储空间及相关信息,主要配置四个选项:
资源名称:可以是除了空白字符外的任意ACSII码字符;
DRBD设备:在双方节点上,此DRBD设备的设备文件;一般为/dev/drbdN,其主设备号147
磁盘:在双方节点上,各自提供的存储设备;
网络配置:双方数据同步时所使用的网络属性;
1-4,DRBD 配置工具
drbdadm:高级管理工具,管理/etc/drbd.conf,向drbdsetup和drbdmeta发送指令。
drbdsetup:配置装载进kernel的DRBD模块,平时很少直接用。
drbdmeta:管理META数据结构,平时很少直接用。
1-5,DRBD与RAID1区别
RAID1也是实现不同存储设备间的数据镜像备份的,不同的是RAID1各存储设备是连接一个RAID控制器接入到一台主机上的,而DRBD是通过网络实现不同节点主机存储设备数据的镜像备份。
1-6、DRBD与集群共享存储
在《高可用集群》讲到了共享存储:如果各节点访问同一个数据文件都是在同一个存储空间内的,就是说数据共享的就一份,而这个存储空间就共享存储。
而DRBD定义上就指出了"无共享"--不同节点存储设备空间是镜像,DRBD可以直接应用在主备模型的集群中,也可通过高可用软件如corosycn应用在双主模型集群中,不过这就需要DML/OCFS2/GFS2分布式集群文件系统为双主读写的时候分配锁;还有就是DRBD为NFS共享存储提供高可用镜像备份,等等…
2、相关准备配置
本文是在前面《heartbeat v2 haresource 配置可用集群》和《corosync pacemaker 配置高可用集群》的一些配置基础上进行的,注意这里不是配置高可用集群,所以corosync等并不需要。
2-1、具体使用资源
1、节点主机系统:RHEL 5.8 64bit
2、两台节点主机node1,node2:
Node1: IP:192.168.18.241 host name:node1.tjiyu,com;
Node2: IP:192.168.18.242 host name:node2.tjiyu.com;
3、DRBD:
Disk:/dev/sda5 1G
DRBD device:/dev/drbd0
DRBD resource:mydrbd
mountdirectory:/drbd
2-2、配置前所需要的准备
1、配置IP、关闭防火墙;
2、配置各节点名称;
前面说到的高可用集群已有详细介绍,这里就不再给出了。
2-3、创建磁盘分区
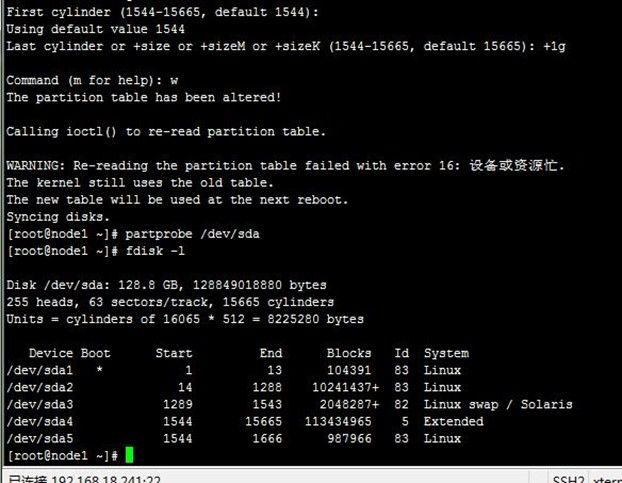
但这需要分别在两节点主机上创建/dev/sda5的磁盘分区,注意这并不需要格式化,下面配置好DRBD并启动后,再格式化,因为文件系统的挂载只能在Primary节点进行,因此,也只有在设置了主节点后才能对drbd设备进行格式化,这样就会连格式化后的全部信息都镜像到另一个节点,创建过程如下:
[root@node1 ~]# fdisk /dev/sda
[root@node1 ~]# partprobe /dev/sda
[root@node1 ~]# fdisk –l
下面先将DRBD下载安装。
3、DRBD下载安装
由于这里用到的是RHEL 5.8 64bit系统,使用的内核为2.6.18-308.el5,上面说到2.6.33版本起才开始整合进内核,所以系统中没有DRBD,但可以通过RPM包安装整合到内核中,注意内核版本与DRBD版本的兼容,可以到网址:http://vault.centos.org/5.8/extras/x86_64/RPMS/,下载能完全兼容centos5的比较新rpm包,下载drbd83-8.3.15-2.el5.centos.x86_64.rpm和kmod-drbd83-8.3.15-3.el5.centos.x86_64.rpm,前者是用户空间的管理配置工具,后者是DRBD内核核心模块(类似ipvsadm与ipvs),分别放到两节点主机上执行安装,过程如下:
[root@node1 ~]# yum --nogpgcheck localinstall *drbd*.rpm
![]()
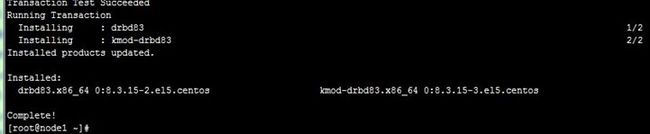
两节点主机如上安装好,下面开始配置。
4、配置DRBD
执行rpm -ql drbd83可以看DRBD安装的文件信息,其中/etc/drbd.conf是主配置文件,主要用来把全局配置文件和各资源配置文件(所有以.res结尾的文件)包含进来的;而其它模块配置文件在/etc/drbd.d/下,包括/etc/drbd.d/global_common.conf全局配置文件,下面将会配置的资源配置文件也会放到这里。
4-1、配置/etc/drbd.conf文件
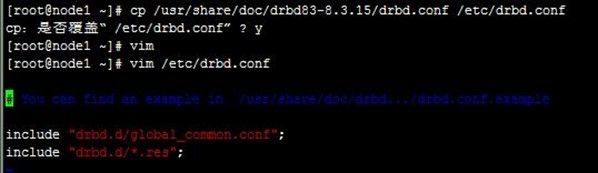
/etc/drbd.conf是主配置文件,主要用来把全局配置文件和各资源配置文件包含进来的,但安装后文件中没有配置任何东西,不过提示了一样例文件,直接复制样例文件使用,即可,里面配置了包含关系,如下:
[root@node1 ~]# cp /usr/share/doc/drbd83-8.3.15/drbd.conf /etc/drbd.conf

4-2、配置global_common.conf配置文件
/etc/drbd.d/global_common.conf全局配置文件,下面在原来的配置上主要改动了信息处理策略、磁盘出错处理和加密,vim /etc/drbd.d/global_common.conf进行配置后如下:
global { usage-count no;#不让linbit公司收集目前drbd的使用情况 # minor-count dialog-refresh disable-ip-verification } common { protocol C;#上面说到的A/B/C复制模式,默认C,数据可靠性高 handlers {#信息处理的一些策略 pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f"; local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f"; # fence-peer "/usr/lib/drbd/crm-fence-peer.sh"; # split-brain "/usr/lib/drbd/notify-split-brain.sh root"; # out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root"; # before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k"; # after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh; } startup { # wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb } disk { # on-io-error fencing use-bmbv no-disk-barrier no-disk-flushes # no-disk-drain no-md-flushes max-bio-bvecs on-io-error detach;#同步IO错误的做法:分离该磁盘 } net { # sndbuf-size rcvbuf-size timeout connect-int ping-int ping-timeout max-buffers # max-epoch-size ko-count allow-two-primaries cram-hmac-alg shared-secret # after-sb-0pri after-sb-1pri after-sb-2pri data-integrity-alg no-tcp-cork cram-hmac-alg "sha1";#设置加密算法sha1 shared-secret "mydrbdtjiyu";#设置加密随机key }
4-3、配置DRBD资源
每个资源通常定义在一个单独的位于/etc/drbd.d目录中的以.res结尾的文件中。资源在定义时必须为其命名,名字可以由非空白的ASCII字符组成。每一个资源段的定义中至少要包含两个host子段,以定义此资源关联至的节点,其它参数均可以从common段或drbd的默认中进行继承而无须定义,这样就构成前面据说的四个配置选项。
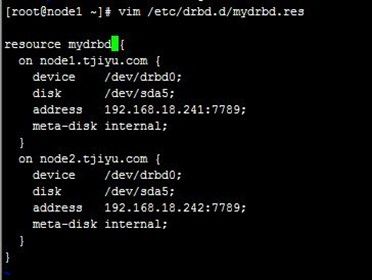
下面配置添加上面创建的两节点主机/dev/sda5分区为DRBD设备资源mydrbd,mydrbd.res文件配置如下 :
resource mydrbd { on node1.tjiyu.com { device /dev/drbd0; disk /dev/sda5; address 192.168.18.241:7789; meta-disk internal; } on node2.tjiyu.com { device /dev/drbd0; disk /dev/sda5; address 192.168.18.242:7789; meta-disk internal; } }
4-4、两个文件远程复制到node2
上面在node1上配置好了这三个文件,可以直接远程复制到node2上:
[root@node1 ~]# scp /etc/drbd.conf node2:/etc/
[root@node1 ~]# scp /etc/drbd.d/{global_common.conf,mydrbd.res} node2:/etc/drbd.d

4-5、创建初始化DRBD设备元数据
分别在两节点上创建DRBD设备元数据,但由于上面创建分区数据没有初始为0,所以创建失败(Command 'drbdmeta 0 v08 /dev/sda5 internal create-md' terminated with exit code 40),得先执行:
[root@node1 ~]# dd if=/dev/zero of=/dev/sda5 bs=1M count=100
然后再创建,它会根据刚才的配置进行创建初始化:
[root@node1 ~]# drbdadm create-md mydrbd

4-6、启动DRBD服务
分别在两节点上同时启动DRBD服务,注意只在一个节点是启动,另一个节点不启动,不会成功,需要在一个节点是启动后,立即启动另一个节点的服务,如下:
![]()
4-7、查看启动状态
使用cat /proc/drbd或 drbd-overview可以查看DRBD的启动状态,可以看到启动,两节点都处理备用状态,没有上线:
[root@node1 ~]# drbd-overview

4-8、配置node1节点为Primary,并同步数据
在要设置为Primary的节点上执行如下命令:
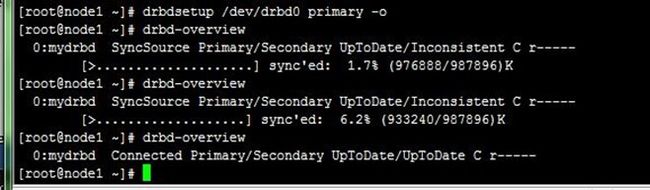
# drbdsetup /dev/drbd0 primary –o
也可以在要设置为Primary的节点上使用如下命令来设置主节点:
# drbdadm -- --overwrite-data-of-peer primary web
而后再次查看状态,可以发现数据同步过程已经开始:
# drbd-overview
0:mydrbd SyncSource Primary/Secondary UpToDate/Inconsistent C r-----
[>....................] sync'ed: 1.7% (976888/987896)K
等数据同步完成以后再次查看状态,可以发现节点已经牌实时状态,且节点已经有了主次:
# drbd-overview
0:web Connected Primary/Secondary UpToDate/UpToDate C r----
整个过程如下:
4-9、创建文件系统
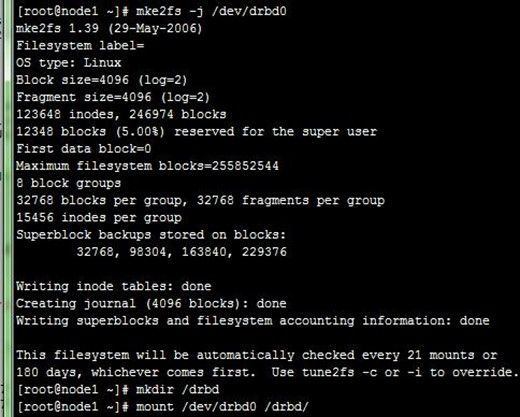
前面创建磁盘分区时也说过:文件系统的挂载只能在Primary节点进行,因此,也只有在设置了主节点后才能对drbd设备进行格式化。现在可以在ndoe1上进行了,格式化后把它挂载到/drbd目录上,过程如下:
[root@node1 ~]# mke2fs -j /dev/drbd0
[root@node1 ~]# mkdir /drbd
[root@node1 ~]# mount /dev/drbd0 /drbd/
[root@node1 ~]# cp /etc/drbd.conf /drbd
[root@node1 ~]# ll /drbd
5、测试文件镜像复制
5-1、复制文件
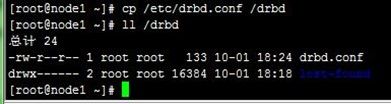
在ndoe1上把格式化后的DRBD设备挂载到/drbd目录上,然后复制drbd.conf文件进去测试,这时候DRBD自动镜像到node2上,过程如下
5-2、切换Primary和Secondary节点,查看镜像文件
对主Primary/Secondary模型的drbd服务来讲,在某个时刻只能有一个节点为Primary,因此,要切换两个节点的角色,只能在先将原有的Primary节点设置为Secondary后,才能原来的Secondary节点设置为Primary。
所以,在node1上先卸载DRBD目录,再设置为从节点:

然后到node2上设置为主节点,再把目录挂载到/drbd,可以查看该目录下有前面复制进去的drbd.conf文件,说明前面在node1上复制文件进去的时候,DRBD自动镜像到node2上,过程如下:
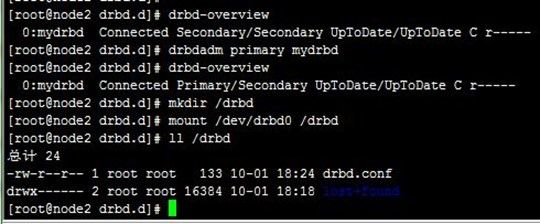
6、DRBD脑裂
如果配置过程中发生,DRBD脑裂问题,如下:
blockdrbd0: Split-Brain detected but unresolved, dropping connection! blockdrbd0: meta connection shut down by peer. blockdrbd0: error receiving ReportState, l: 4! blockdrbd0: Discarding network configuration.
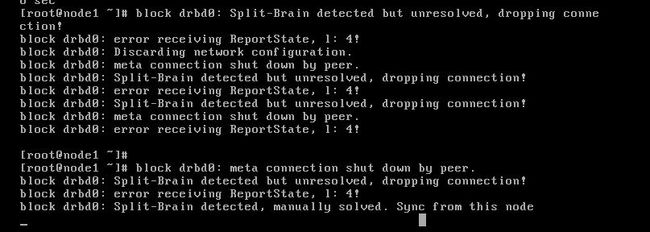
解决方法如下:
将Node1设置为主节点并挂载测试:
[root@node1 ~]#drbdadm primary mydrbd
[root@node1 ~]#mount /dev/drbd0 /mydata
[root@node1 ~]#ll /mydata/
将Node2设置为从节点并丢弃资源数据:
[root@node2 ~]#drbdadm secondary mydrbd
[root@node2 ~]#drbdadm -- --discard-my-data connect mydrbd
在Node1主节点上手动连接资源:
[root@node1~]# drbdadm connect mydrbd
最后查看各个节点状态,连接已恢复正常,整个过程如下:

到这里,配置DRBD 可以正常运行了,下篇《DRBD + corosync + pacemaker 配置mysql高可用集群》将在本文的基础上,进行DRBD + corosync + pacemaker的mysql高可用集群的相关配置……
【参考资料】
1、DRBD官网:http://www.drbd.org/en/
2、heartbeat v2 haresource配置高可用集群:http://blog.csdn.net/tjiyu/article/details/52663927
3、Linux 高可用(HA)集群之DRBD详解:http://freeloda.blog.51cto.com/2033581/1275384
4、Web集群中文件存储系统的解决方案:http://www.drupal001.com/2015/06/multiple-servers-file-storage/?utm_source=tuicool&utm_medium=referral
5、DRBD编译安装中出现的问题及解决小结:http://wangzhijian.blog.51cto.com/6427016/1711284
6、DRBD脑裂故障处理:http://phenixikki.blog.51cto.com/7572938/1305253