数据权限系统
在之前写过一篇关于菜单权限系统的设计,所以为了完善整个权限系统的模型,决定把数据权限也做一个总结。菜单权限管理系统
目标
实现对数据的权限控制。简单的来说,就是决定谁可以操作(增删改查)哪些数据。
该权限模型的适用范围
该模型目前在一些常用的管理平台得到的验证与实施,目前已应用在多个公司产品中,主要场景是CRM类项目。
核心难点
数据权限的主要难度在于查询的性能、授权、鉴权,字段级别的控制。
比如在百万级别规模时,mysql如何实现秒级别的查询?
场景介绍:在之前设计该权限模型时,我们的项目遇到了一个核心的难题,sql的查询速度非常的缓慢!!!一个sql可能高达10S+。这对于用户而言,是无法接受的。所以我们尝试去优化sql的表设计,索引的优化,但是最终结果都摆阵下来。主要的问题是我们并没有足够抽象数据,导致百万级别的数据下,sql非常缓慢。这里面占时不需要考虑分库分表(百万级别的规模不足以使用该手段)。
百万级别的数据权限怎么授予用户?
场景介绍:面对如此大的数据量,如何授权用户权限呢?总不能是逐个分配的!!!
如何快速高效的进行数据鉴权呢?
场景介绍:这么大的数据量,在程序中不容易处理,必须借助于数据库的高效查询方案,但是怎么实现呢?
如何实现字段级别的权限控制?
场景介绍:字段级别的权限怎么控制?控制sql的生成逻辑?还是怎么处理呢?
权限模型的抽象
有了那么多的问题,我们先从权限模型入手,我们必须高度抽象化我们的权限系统,才有机会做到。
下面我们直接贴出一个图,介绍该模型的一些核心概念
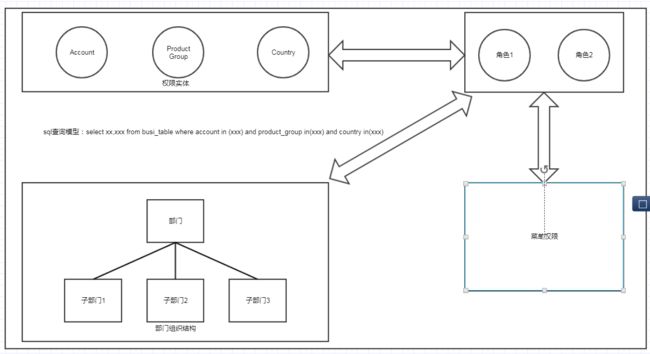
我们根据上图所示,可以观察到下面的几个元素,分别是:权限实体,部门,角色,菜单权限。
其中菜单权限参考上面的链接
权限实体:这个是该权限模型的核心元素,也就是我们需要系统控制的数据。比如客户,订单,渠道,区域等。
部门:这个简单,就是一般的部门组织结构
角色:抽象的实体,用于快速分配权限相同权限给一批用户,与菜单权限的角色概念一致。
权限的查询模型
在上面的图中,不知道大家是否看到了一条sql
select xxx from xx_table where account in (xxx) and product_group in (xxx) and country in (xxx)没错,这就是该模型的查询模型。其中account,product_group,country代表需要做权限控制的权限实体。
在这里面只是一个简单的模型,如果account或者country等数据量足够大时,我们会发现mysql in查询是会出现非常严重的查询性能的。比如account数据量规模为100W时...
引入部门组织结构,突破数据量的限制
还是看上图,我们有一个部门组织结构,我们可以想象下,比如总经理,自然是可以查看所有部门的数据。假设A部门经理,可以查看A部门以及子部门的数据。如果是普通的员工,只能查看自己账号下的数据。
下面我们给出一个部门组织结构图,并且给每个部分标志一个key,key的生成规则如下
1.根部门的key为数字10
2.根部门的直属部门的key为10 001,10 002,10 003...以此类推
3.其他的key生成逻辑和步骤2相同,唯一不同的就是key的长度变长了,比如:10 001 001,10 001 002
这里面我们给部门打上如下的key,为了方便介绍,我们还是贴图片
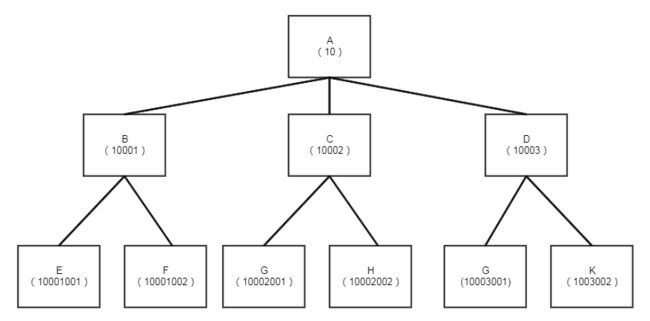
有了该模型,我们结合mysql的前置查询索引的特性(org like 'xxxx%')
where org like '10%'org like '10001%'org like '10002%'如何授权
解决了查询的性能,其实授权也就很简单了。
授权我们一般根据员工的岗位来设定,普通员工,部门经理
普通员工:不需要单独授权,直接绑定员工工号即可
部门经理:设置该员工可以查看的部门(支持多个)
如何鉴权
鉴权和授权一般是相互的一个过程
1.判断该员工是否为部门经理
2.如果是,取出部门的key
3.添加到sql中,使用mysql前置like查询数据
字段权限的控制
字段权限的控制,我们直接针对接口编程,不要针对sql编程。
比如获取员工列表:我们只需要控制输出的字段属性即可。
为啥不针对sql编程?因为sql需要考虑各种join,字段是否缺失,关联的内容存储在其他表等情况
数据库的实现
1.识别权限实体
2.给权限实体加上一个工号字段,一个部门字段,比如:emp_id,org_key
3.查询时,先获取员工的角色权限,如果是部门经理,那么获取对应的key列表
4.构建sql,加入部门或者工号的sql片段
- org_key lik '10 001%' or org_key like '10 002%',这是部门的sql
- emp_id = 'xxx',这是普通员工的sql
总结
设计好一个权限系统,说难不难,但是也不简单。
主要的难点在于
1.识别出你需要控制的数据(权限实体)
2.高效的查询效率与sql的索引相结合(这里面使用部门key与sql的前置查询)
应用于扩展
该模型设计简单,具备一定的普遍性,所以在设计时,我们可以根据不同的系统去进行演进与扩展。大家有兴趣的可以思考下