Ignite(二): 持久化存储架构
文章目录
- 1、PageMemory
- 2、FullPageId
- 2.1、PageId 和 EffectivePageId
- 3、Page State(页状态)
- 3.1、Page Modification(页修改)
- 4、Internal Data Structures(内部数据结构)
- 4.1、Data partitions(数据分区)
- 4.2、Index partition(索引分区)
- 5、Page ID Rotation(页面ID轮换)
- 6、Checkpointing(检查点)
- 7、Page Store
- 7.1、allocatePage() 页分配
- 7.2、pages() 已分配总页数
- 7.3、read() 读取指定页到页缓冲区
- 7.4、write()
- 7.5、pageOffset() 获取存储文件中的页偏移量。
- 7.6、sync() 同步方法
- 7.7、Write-Ahead-Log(WAL)
- 7.7.1、log()
- 7.7.2、flush()
- 7.7.3、replay()
- 8、Rebalancing(再平衡)
- 9、参考资料
1、PageMemory
PageMemory 是用于处理内存中页面的抽象。 它在内部与文件存储交互,该文件存储负责分配页面ID,写入和读取页面。 应该区分页面和页面缓冲区的概念。 页是固定长度的数据块,具有唯一的标识符,称为FullPageId。 页面缓冲区是内存中与某个页面关联的区域。 PageMemory完全处理将页面加载到相应页面缓冲区以及从内存中清除未使用的页面缓冲区的过程。 在任何时候页面存储器都可以保留页面缓冲区的任何子集(适合分配的RAM)。
2、FullPageId
FullPageId 由高速缓存ID(32位)和Page ID(64位)组成。 Page ID 实际上是一个虚拟页面标识符,可以在页面生命周期内更改(请参见下面的PageRotation)。EffectivePageId 是 Page ID (partition ID, page index)的一部分,在页面生命周期中不会更改。
2.1、PageId 和 EffectivePageId
PageId 的结构:
+---------+-----------+------------+--------------------------+
| 8 bits | 8 bits | 16 bits | 32 bits |
+---------+-----------+------------+--------------------------+
| OFFSET | FLAGS |PARTITION ID| PAGE INDEX |
+---------+-----------+------------+--------------------------+
| EFFECTIVE PAGE ID |
+---------------------------------------+
偏移量(OFFSET)是保留字段,用于 PAGE ID 旋转或引用数据页中的记录
标志(FLAGS)是用于 PAGE ID 旋转的保留字段
分区ID(PARTITION ID)可以是[0,65500]中的分区标识符,也可以是用于索引分区的保留值0xFFFF。 其他值保留供将来使用。
页面索引(PAGE INDEX)是每个分区中单调增长的数字
3、Page State(页状态)
页面随时可能处于以下状态:
(1)Unloaded(未加载页): 内存中没有加载相应的页面缓存。
(2)Clean(干净页): 页面缓冲区已加载,并且页面缓冲区的内容等于写入磁盘的数据
(3)Dirty(脏页): 页面缓冲区已被修改,并且页面缓冲区的内容不等于写入磁盘的数据
(4)Dirty in checkpoint(检查点脏页): 在第一次修改被写入磁盘之前,页面缓冲区已被修改,检查点已启动,并且页面缓冲区已被再次修改。 在这种状态下,PageMemory 为每个页面保留两个页面缓冲区-第一个用于当前检查点(进行中),第二个用于下一个检查点。
PageMemory会跟踪脏页ID,并能够将此列表提供给检查指针线程。 当检查点启动时,脏页的集合会自动重置为新的空集合。
3.1、Page Modification(页修改)
每个页面缓冲区都有一个关联的读写锁和一个标签。 页面标签是页面ID的一部分,用于页面旋转。
为了读取或写入页面缓冲区内容,必须获得读写锁。 页面缓冲区读写锁要求传递正确的标记,以便获取该锁。
如果传入的标记与实际的页面标记不同,则表示该页面已被重用,并且指向该页面的链接不再有效(请参见下面的页面ID旋转)。
4、Internal Data Structures(内部数据结构)
根据页面类型和页面中的可用空间量,可以选择在FreeList或ReuseList中对其进行跟踪。 FreeList是一种数据结构,用于跟踪部分空闲的页面(适用于数据页面)。 ReuseList跟踪完全空闲的页面,这些页面可以由数据库中的任何其他数据结构使用。
每个分区都有一个特殊的专用页面(元页面),该页面保存分区的状态,页面ID用作与该分区关联的所有数据结构的根。
4.1、Data partitions(数据分区)
对于数据分区,使用以下数据结构:
(1)FreeList(同时用作重用列表)以跟踪空闲页面和空白页面。
(2)分区哈希索引用作缓存的主要存储。
(3)RowStore保留键值对
4.2、Index partition(索引分区)
对于索引分区,使用以下数据结构:
(1)ReuseList(因为BTrees完全获取页面并且不需要跟踪可用空间)
(2)元数据存储,该数据结构跟踪所有分配的索引,并包含【索引名称(index name),根页面ID( root page ID)】的键值对。
5、Page ID Rotation(页面ID轮换)
B+Tree 的结构与 ReuseList(重用列表) 相结合意味着,当 B+Tree 上的页引用通过并发删除返回到 ReuseList 列表中时,可以观察到一种状态,并且此页已在同一 B+Tree 中的另一个位置(ABA问题)。
在这种情况下,可能会发生死锁,因为可能会违反页面锁定的顺序。 为了避免这种情况,每次将页面返回到重用列表时,我们都会更新页面标签。 在这种情况下,如果读者发现由于页面标签不匹配而无法获取锁,它将从头开始重新操作,并读取更新的链接。
6、Checkpointing(检查点)
检查点是将脏页从内存写入持久性存储的过程。
检查点包含以下关键组件:
(1)Checkpoint read-write lock(检查点读写锁): 当数据结构被更新时,此锁可保护PageMemory避免捕获中间状态。 执行数据结构更新(缓存更新,分区迁移等)的线程必须获取读取锁,更新数据结构后释放锁。 Checkpointer 必须获取写锁,捕获脏页面的ID,将页面持久保存到磁盘并释放写锁。
(2)WAL checkpoint record(WAL 检查点记录): 当检查点保持检查点写入锁定时,此记录将插入WAL。如果将WAL从之前的检查点记录变更为当前检查点记录,则数据结构将处于一致状态。
(3)Database checkpoint markers(数据库检查点标记) 当检查点开始或完成时,每个标记都是写入本地FS的文件。这些标记包含WAL检查点记录在WAL中的位置。
检查点开始后,PageMemory 将转变为“写时复制(copy-on-write)”模式。这意味着,如果修改了脏页缓冲区,则该页将在检查点状态下移动到脏页,而 PageMemory 将创建一个对 PageMemory 用户可见的页缓冲区临时副本(页的当前内容)。同时,检查点页面缓冲区仅对检查点程序可见,检查点程序最终会将其刷新到磁盘。当检查点程序完成写入时,它会将所有复制的页刷新到主内存中。
每次修改页面缓冲区时(在释放页面写锁之前),必须将相应的更改记录到WAL中。更具体地说,如果要修改的页面是干净的,则必须记录整个已修改的页面缓冲区。如果要修改的页是脏的,则只应修改二进制页增量,以减少WAL消耗并提高性能。
启动时,节点可以观察检查点标记的以下状态:
最后一个检查点开始标记具有相应的检查点结束标记。
这意味着当没有检查点进行时,进程停止或崩溃,因此页面存储(磁盘)包含一致的数据结构状态。 我们只需要重播自上一个检查点标记之后的记录到WAL的逻辑更新。
最后一个检查点开始标记没有相应的检查点结束标记。这意味着进程在检查点期间崩溃或停止,并且页面存储包含半写页面状态。在这种情况下,恢复包括两个步骤。首先,我们必须从最后完成的检查点标记开始到以开始检查点标记结束的所有WAL记录。这将使数据结构处于一致状态。在此之后,我们必须将WAL逻辑更新从记录B重放到日志的末尾(同上)。
7、Page Store
页面存储的所有方法都必须是线程安全的。
页存储是一个接口,负责页缓冲区分配、读取和写入物理持久性存储。页存储是按分区分配的。相关API可参考,org.apache.ignite.internal.pagemem.store.PageStore。
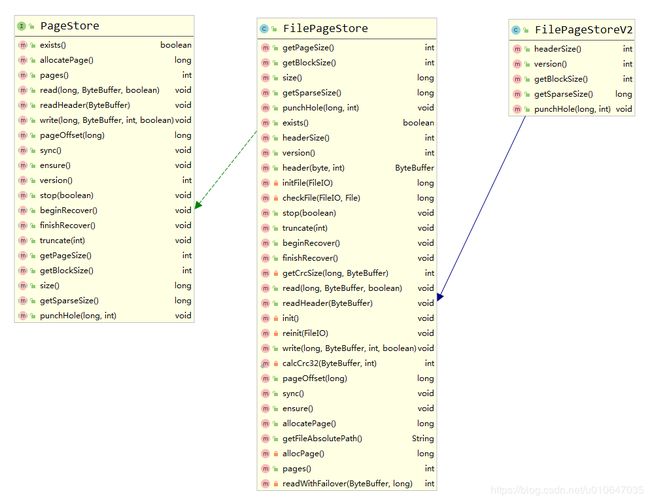
7.1、allocatePage() 页分配
此方法应返回下一个未使用的页索引(新页的地址)。当存储开始时,相应的计数器必须恢复到上次写入页的索引。换句话说,分配的页索引的持久性由检查点执行。
FilePageStore.java
public long allocatePage() throws IgniteCheckedException {
//初始化页
init();
//返回分配页的索引
return allocPage() / pageSize;
}
FilePageStore.java >> init()
/**
* @throws 如果存储文件初始化失败,将抛出异常StorageException
*/
private void init() throws StorageException {
//判断是否初始化
if (!inited) {
//获取写锁
lock.writeLock().lock();
try {
//二次判断是否初始化
if (!inited) {
FileIO fileIO = null;
StorageException err = null;
long newSize;
try {
boolean interrupted = false;
while (true) {
try {
File cfgFile = pathProvider.apply().toFile();
this.fileIO = fileIO = ioFactory.create(cfgFile, CREATE, READ, WRITE);
fileExists = true;
//初始化文件或校验文件,文件大小减去文件头大小=文件可用大小
newSize = (cfgFile.length() == 0 ? initFile(fileIO) : checkFile(fileIO, cfgFile)) - headerSize();
//如果线程抛出interrupted异常,则中断当前线程
if (interrupted)
Thread.currentThread().interrupt();
break;
}
catch (ClosedByInterruptException e) {
interrupted = true;
Thread.interrupted();
}
}
assert allocated.get() == 0;
//分配页大小
allocated.set(newSize);
inited = true;
//顺序很重要,在分配更新并将inited设置为true之后,必须更新总页数,因为它会影响pages()返回值。
allocatedTracker.add(pages());
}
catch (IOException e) {
err = new StorageException(
"Failed to initialize partition file: " + getFileAbsolutePath(), e);
throw err;
}
finally {
if (err != null && fileIO != null)
try {
fileIO.close();
}
catch (IOException e) {
err.addSuppressed(e);
}
}
}
}
finally {
//释放写锁
lock.writeLock().unlock();
}
}
}
FilePageStore.java >> allocPage()
private long allocPage() {
long off;
do {
//截止上次分配总大小
off = allocated.get();
//截止上次分配总大小 + 本次分配页大小
if (allocated.compareAndSet(off, off + pageSize)) {
allocatedTracker.increment();
break;
}
}
while (true);
return off;
}
7.2、pages() 已分配总页数
public int pages() {
//如果没有初始化,返回0
if (!inited)
return 0;
//已分配总页数=已分配大小 / 单页大小
return (int)(allocated.get() / pageSize);
}
7.3、read() 读取指定页到页缓冲区
/**
* 读取指定 pageId 页数据到指定的页缓冲区
*
* @param pageId 页id
* @param pageBuf 页缓冲区
* @param keepCrc 默认情况下,读取文件中的CRC,可以将其保存在pageBuf中
* @throws IgniteCheckedException If reading failed (IO error occurred).
*/
public void read(long pageId, ByteBuffer pageBuf, boolean keepCrc) throws IgniteCheckedException {
//页初始化
init();
try {
//计算当前页数据偏移量
long off = pageOffset(pageId);
assert pageBuf.capacity() == pageSize;
assert pageBuf.remaining() == pageSize;
assert pageBuf.position() == 0;
assert pageBuf.order() == ByteOrder.nativeOrder();
assert off <= allocated.get() : "calculatedOffset=" + off +
", allocated=" + allocated.get() + ", headerSize=" + headerSize() + ", cfgFile=" +
pathProvider.apply().toAbsolutePath();
//根据数据偏移量,读取指定页数据到缓冲区
int n = readWithFailover(pageBuf, off);
// 如果尚未写入页面,则没有任何内容可读取
if (n < 0) {
pageBuf.put(new byte[pageBuf.remaining()]);
return;
}
int savedCrc32 = PageIO.getCrc(pageBuf);
PageIO.setCrc(pageBuf, 0);
pageBuf.position(0);
if (!skipCrc) {
int curCrc32 = FastCrc.calcCrc(pageBuf, getCrcSize(pageId, pageBuf));
if ((savedCrc32 ^ curCrc32) != 0)
throw new IgniteDataIntegrityViolationException("Failed to read page (CRC validation failed) " +
"[id=" + U.hexLong(pageId) + ", off=" + (off - pageSize) +
", file=" + getFileAbsolutePath() + ", fileSize=" + fileIO.size() +
", savedCrc=" + U.hexInt(savedCrc32) + ", curCrc=" + U.hexInt(curCrc32) +
", page=" + U.toHexString(pageBuf) +
"]");
}
assert PageIO.getCrc(pageBuf) == 0;
if (keepCrc)
PageIO.setCrc(pageBuf, savedCrc32);
}
catch (IOException e) {
throw new StorageException("Failed to read page [file=" + getFileAbsolutePath() + ", pageId=" + pageId + "]", e);
}
}
7.4、write()
/**
* 将指定页缓存区的数据写入指定索引页
*
* @param pageId 页id
* @param pageBuf 页缓冲区
* @param tag 分区文件版本,基于1的递增计数器。对于过时的页面{@code tag}的值较低,write不执行任何操作。
* @param calculateCrc 如果{@code False}将强制跳过crc计算。
* @throws IgniteCheckedException If page writing failed (IO error occurred).
*/
public void write(long pageId, ByteBuffer pageBuf, int tag, boolean calculateCrc) throws IgniteCheckedException {
//初始化
init();
boolean interrupted = false;
while (true) {
FileIO fileIO = this.fileIO;
try {
//获取读锁
lock.readLock().lock();
try {
//根据分区文件版本判断是否是过期页
if (tag < this.tag)
return;
//计算偏移量
long off = pageOffset(pageId);
assert (off >= 0 && off <= allocated.get()) || recover :
"off=" + U.hexLong(off) + ", allocated=" + U.hexLong(allocated.get()) +
", pageId=" + U.hexLong(pageId) + ", file=" + getFileAbsolutePath();
assert pageBuf.position() == 0;
assert pageBuf.order() == ByteOrder.nativeOrder() : "Page buffer order " + pageBuf.order()
+ " should be same with " + ByteOrder.nativeOrder();
assert PageIO.getType(pageBuf) != 0 : "Invalid state. Type is 0! pageId = " + U.hexLong(pageId);
assert PageIO.getVersion(pageBuf) != 0 : "Invalid state. Version is 0! pageId = " + U.hexLong(pageId);
if (calculateCrc && !skipCrc) {
assert PageIO.getCrc(pageBuf) == 0 : U.hexLong(pageId);
PageIO.setCrc(pageBuf, calcCrc32(pageBuf, getCrcSize(pageId, pageBuf)));
}
// 如果被强制跳过,请检查是否在堆栈上某处计算了crc。
assert skipCrc || PageIO.getCrc(pageBuf) != 0 || calcCrc32(pageBuf, pageSize) == 0 :
"CRC hasn't been calculated, crc=0";
assert pageBuf.position() == 0 : pageBuf.position();
fileIO.writeFully(pageBuf, off);
PageIO.setCrc(pageBuf, 0);
if (interrupted)
Thread.currentThread().interrupt();
return;
}
finally {
lock.readLock().unlock();
}
}
catch (IOException e) {
if (e instanceof ClosedChannelException) {
try {
if (e instanceof ClosedByInterruptException) {
interrupted = true;
Thread.interrupted();
}
reinit(fileIO);
pageBuf.position(0);
PageIO.setCrc(pageBuf, 0);
continue;
}
catch (IOException e0) {
e0.addSuppressed(e);
e = e0;
}
}
throw new StorageException("Failed to write page [file=" + getFileAbsolutePath()
+ ", pageId=" + pageId + ", tag=" + tag + "]", e);
}
}
}
7.5、pageOffset() 获取存储文件中的页偏移量。
/**
* 获取存储文件中的页偏移量。
*
* @param pageId 页id
* @return 页偏移量.
*/
public long pageOffset(long pageId) {
//页偏移量=pageId 的索引 * 页大小 + 页头大小
return (long) PageIdUtils.pageIndex(pageId) * pageSize + headerSize();
}
7.6、sync() 同步方法
/**
* Sync方法,用于确保给定页被写入存储区。
*
* @throws IgniteCheckedException If sync failed (IO error occurred).
*/
public void sync() throws StorageException {
//获取写锁
lock.writeLock().lock();
try {
//初始化
init();
FileIO fileIO = this.fileIO;
if (fileIO != null)
fileIO.force();
}
catch (IOException e) {
throw new StorageException("Failed to fsync partition file [file=" + getFileAbsolutePath() + ']', e);
}
finally {
lock.writeLock().unlock();
}
}
7.7、Write-Ahead-Log(WAL)
WAL 是仅附加数据结构,用于记录逻辑数据库修改和页面更改。 有关API,请参考org.apache.ignite.internal.pagemem.wal.IgniteWriteAheadLogManager。
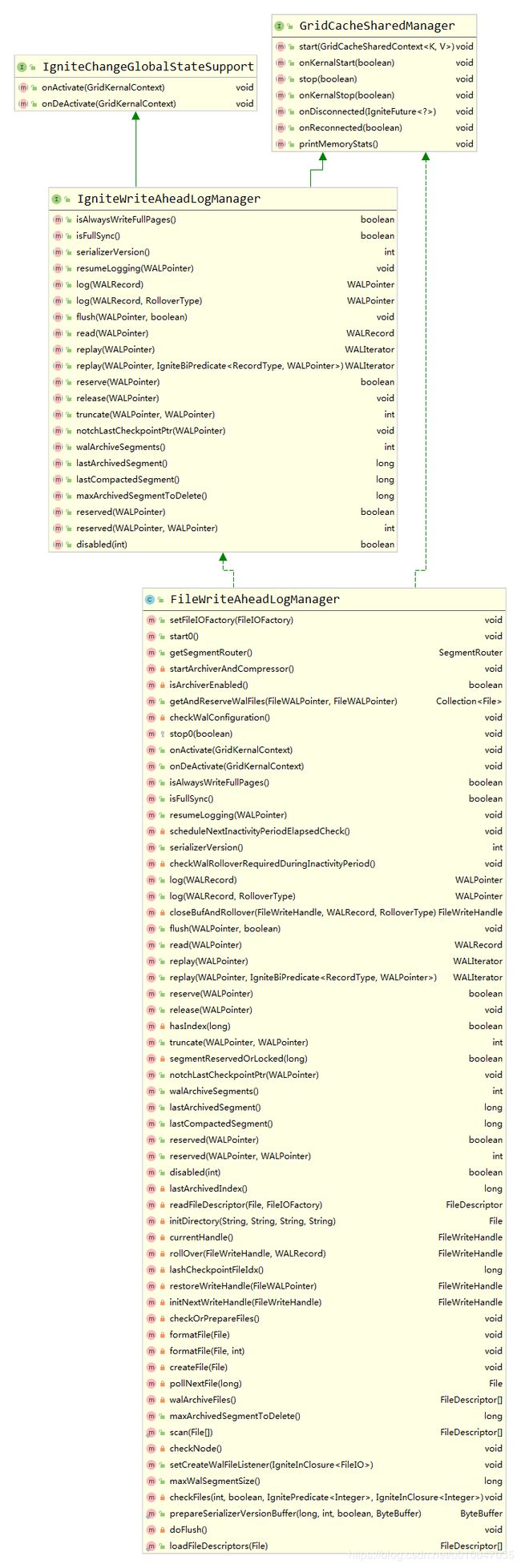
7.7.1、log()
将WAL记录追加到日志,并在日志文件中返回指向该记录的指针。 在此方法完成后,记录无需立即写入到磁盘。
public WALPointer log(WALRecord rec) throws IgniteCheckedException {
return log(rec, RolloverType.NONE);
}
public WALPointer log(WALRecord rec, RolloverType rolloverType) throws IgniteCheckedException {
if (serializer == null || mode == WALMode.NONE)
return null;
// 只允许增量记录,页面快照和内存恢复以恢复模式写入。
if (cctx.kernalContext().recoveryMode() &&
!(rec instanceof PageDeltaRecord || rec instanceof PageSnapshot || rec instanceof MemoryRecoveryRecord))
return null;
//当前日志段句柄。
FileWriteHandle currWrHandle = currentHandle();
//缓存管理器的便捷适配器。
WALDisableContext isDisable = walDisableContext;
//日志记录尚未恢复。
if (currWrHandle == null || (isDisable != null && isDisable.check()))
return null;
// 如果已配置,执行页面快照压缩。
if (pageCompression != DiskPageCompression.DISABLED && rec instanceof PageSnapshot) {
PageSnapshot pageSnapshot = (PageSnapshot)rec;
int pageSize = pageSnapshot.realPageSize();
ByteBuffer pageData = pageSnapshot.pageDataBuffer();
ByteBuffer compressedPage = cctx.kernalContext().compress().compressPage(pageData, pageSize, 1,
pageCompression, pageCompressionLevel);
if (compressedPage != pageData) {
assert compressedPage.isDirect() : "Is direct buffer: " + compressedPage.isDirect();
rec = new PageSnapshot(pageSnapshot.fullPageId(), GridUnsafe.bufferAddress(compressedPage),
compressedPage.limit(), pageSize);
}
}
// 首先需要计算记录大小。
rec.size(serializer.size(rec));
while (true) {
WALPointer ptr;
// WAL日志记录类型。正在记录的记录不是过渡记录。
if (rolloverType == RolloverType.NONE)
ptr = currWrHandle.addRecord(rec);
else {
//当前线程是否持有检查点锁
assert cctx.database().checkpointLockIsHeldByThread();
//被记录的记录是一个滚动记录,它应该成为下一个段中的第一个记录。
if (rolloverType == RolloverType.NEXT_SEGMENT) {
//在文件中的位置
WALPointer pos = rec.position();
do {
//除非同时发生滚动,否则这将更改rec.position()。
currWrHandle = closeBufAndRollover(currWrHandle, rec, rolloverType);
}
while (Objects.equals(pos, rec.position()));
ptr = rec.position();
}
//记录的记录是一个滚动记录,它应该尽可能存入当前段。如果当前段已满,则记录将存入下一个段。
else if (rolloverType == RolloverType.CURRENT_SEGMENT) {
if ((ptr = currWrHandle.addRecord(rec)) != null)
currWrHandle = closeBufAndRollover(currWrHandle, rec, rolloverType);
}
else
throw new IgniteCheckedException("Unknown rollover type: " + rolloverType);
}
if (ptr != null) {
metrics.onWalRecordLogged();
lastWALPtr.set(ptr);
if (walAutoArchiveAfterInactivity > 0)
lastRecordLoggedMs.set(U.currentTimeMillis());
return ptr;
}
else
currWrHandle = rollOver(currWrHandle, null);
checkNode();
if (isStopping())
throw new IgniteCheckedException("Stopping.");
}
}
7.7.2、flush()
FileWriteAheadLogManager.java
/**
* 确保所有记录都已刷新到磁盘。
*
* @param ptr 指针, 如果为null,将同步最新记录。
* @param explicitFsync 如果为true,则数据将在硬件级别同步到存储设备。
*/
public void flush(WALPointer ptr, boolean explicitFsync) throws IgniteCheckedException, StorageException {
//flush方法有两个实现,见下文
fileHandleManager.flush(ptr, explicitFsync);
}
FileHandleManagerImpl.java
public void flush(WALPointer ptr, boolean explicitFsync) throws IgniteCheckedException, StorageException {
if (serializer == null || mode == WALMode.NONE)
return;
//当前文件写句柄
FileWriteHandleImpl cur = currentHandle();
// WAL管理器未启动(客户端节点)。
if (cur == null)
return;
//如果给定的WAL文件指针为null,则获取最新记录的指针
FileWALPointer filePtr = (FileWALPointer)(ptr == null ? lastWALPtr.get() : ptr);
//日志模式
if (mode == LOG_ONLY)
//刷新或等待并发刷新完成。
cur.flushOrWait(filePtr);
// 除非需要显式fsync,否则无需在LOG_ONLY或Background中进行同步。
if (!explicitFsync && mode != WALMode.FSYNC)
return;
// 如果已翻转,则无需同步。
if (filePtr != null && !cur.needFsync(filePtr))
return;
//写磁盘
cur.fsync(filePtr);
}
FsyncFileHandleManagerImpl.java
public void flush(WALPointer ptr, boolean explicitFsync) throws IgniteCheckedException, StorageException {
if (serializer == null || mode == WALMode.NONE)
return;
FsyncFileWriteHandle cur = currentHandle();
// WAL管理器未启动(客户端节点)
if (cur == null)
return;
// 如果给定的WAL文件指针为null,则获取最新记录的指针
FileWALPointer filePtr = (FileWALPointer)(ptr == null ? lastWALPtr.get() : ptr);
// 如果已翻转,则无需同步。
if (filePtr != null && !cur.needFsync(filePtr))
return;
//写磁盘
cur.fsync(filePtr, false);
}
7.7.3、replay()
FileWriteAheadLogManager.java
/**
* 调用此方法以遍历写入的日志条目。
*
* @param start 开始迭代的可选WAL指针。
* @return 记录迭代器
* @throws IgniteException If failed to start iteration.
* @throws StorageException If IO error occurred while reading WAL entries.
*/
public WALIterator replay(WALPointer start) throws IgniteCheckedException, StorageException {
return replay(start, null);
}
/**
* 调用此方法以遍历写入的日志条目。
*
* @param start 开始迭代的可选WAL指针。
* @param recordDeserializeFilter 指定筛选器以跳过WAL记录。这些记录不会显式反序列化。
* @return 记录迭代器
* @throws IgniteException If failed to start iteration.
* @throws StorageException If IO error occurred while reading WAL entries.
*/
public WALIterator replay(
WALPointer start,
@Nullable IgniteBiPredicate recordDeserializeFilter
) throws IgniteCheckedException, StorageException {
assert start == null || start instanceof FileWALPointer : "Invalid start pointer: " + start;
//文件写句柄
FileWriteHandle hnd = currentHandle();
//文件末尾指针
FileWALPointer end = null;
if (hnd != null)
end = hnd.position();
//构造迭代器
RecordsIterator iter = new RecordsIterator(
cctx,
walArchiveDir,
walWorkDir,
(FileWALPointer)start,
end,
dsCfg,
new RecordSerializerFactoryImpl(cctx).recordDeserializeFilter(recordDeserializeFilter),
ioFactory,
archiver,
decompressor,
log,
segmentAware,
segmentRouter,
lockedSegmentFileInputFactory);
try {
//迭代器初始化
iter.init();
}
catch (Throwable t) {
iter.close();
throw t;
}
return iter;
}
WAL的当前实现基于基于段的WAL结构。 WAL被写入固定长度的文件,称为segments,每个segments都有一个单调增长的绝对索引。
该段首先被写入WAL工作目录下的一个预分配的文件中。 文件的索引是该段的绝对索引,它等于预分配的段数。
在每个时刻,仅打开一个文件进行写入。 写入文件后,后台WAL归档程序将其复制到WAL归档目录,然后清除该文件(填充零)并交还给WAL以进行进一步写入。
AL archiver和WAL是同步的,因此WAL不会覆盖未归档的文件
8、Rebalancing(再平衡)
重新平衡逻辑基于每个分区的更新计数器。在重新平衡期间,每个节点都将其每个分区的更新计数器发送给协调器。然后,协调器根据更新计数器分配分区状态:将具有最高分区值的节点视为其所有者。
需要获取分区最新数据的节点将在GridDhtPartitionDemandMessage中包含其当前更新计数器。可能会返回完整分区或从WAL提取的计数器之后的更改。
9、参考资料
https://cwiki.apache.org/confluence/display/IGNITE/Persistent+Store+Architecture#PersistentStoreArchitecture-Checkpointing