ICLR 2020 | ELECTRA:新型文本预训练模型
作者 | 叶聪敏
单位 | 厦门大学

儿童节快乐
今天介绍斯坦福大学和Google Brain团队在ICLR2020的论文,该研究提出ELECTRA语言模型,它是一种新型预训练方法,其关键点在于将预训练文本编码器作为标识符而非生成器,来处理现存语言模型的问题。
最近基于maskd langage modeling(MLM)的预训练模型,比如BERT,主要是使用[MASK]令牌替换输入序列中的部分令牌,然后训练一个模型来修复原来的令牌。虽然它们在下游的NLP任务中有良好的结果,但是模型往往需要大量的计算。作为一种替代方案,作者提出了一种更高效的预训练任务,称为replaced token detection(替换令牌检测)。这种方法不是屏蔽部分输入序列,而是通过小型的生成器生成样本来替换输入中的令牌,并且不是训练一个模型来预测损坏令牌的原来标识,而是训练一个判别模型来预测输入中每个标记是否被生成器所生成的样例所替换。经过实验表明,这种新的预训练任务比MLM更加有效,因为该任务是在所有输入标记上定义的,而不仅仅是被屏蔽掉的一部分子集。
1
研究背景
目前最先进的语言表征学习方法被认为是能学习去噪的自动编码器(Vincent et al., 2008),他们选择一小部分(通常为15%)未标记的输入序列,然后掩盖他们的令牌(e.g., BERT; Devlin et al., 2019)或者添加注意力机制(e.g., XLNet; Yang et al.,2019),然后训练神经网络来恢复原来的输入。由于学习了双向表示,使用MLM的模型会比传统的语言模型的预训练更加有效,但是由于模型只能从每个样本中15%的令牌进行学习,因此需要大量的计算资源。作为一种替代方案,本文提出了替换令牌检测,任务主要是学习如何区分真正的输入令牌和看似合理但是是生成而来的替换令牌。相比之下,MLM任务将模型训练为生成器,用于预测被破坏令牌的原本标识。而本文模型使用判别任务的一个关键优势是模型可以从所有输入的标记中学习,而不是直接从输入的子集中学习,从而节省更多的计算资源。模型称为ELECTRA,一种“准确分类令牌替换且能高效学习的编码器”。作者将其应用于Transformer文本编码器的预训练(Vaswanietal.,2017),并且对下游任务进行微调。通过一系列的实验,作者证明了从所有的输入位置中学习可以使ELECTRA比BERT训练地更快。并且实验还表明,如果充分训练,ELECTRA在下游的任务中可以获得更高的准确性。
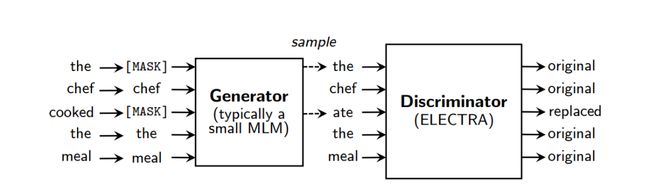
图2. 替换令牌检测概述
2
方法
图2详细描述了替换令牌检测预训练任务。模型主要训练两个神经网络,分别是一个生成器和一个判别器。每一个网络主要由一个编码器组成,能将输入序列映射成对应的向量表示。对于一个给定的位置 ,生成器输出生成的令牌对应的可能性:
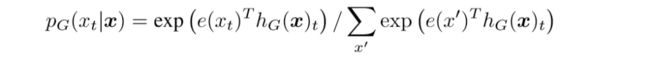
其中表示令牌向量。对于每一个,判别器会预测 是来自于真实数据还是生成器生成的数据:
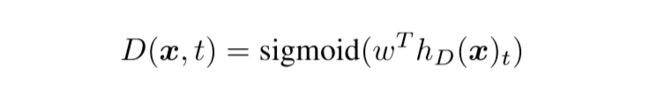
生成器是以MLM的方式进行训练。给定一个输入序列,MLM首先选择一组随机的位置(1到n之间的整数)来进行屏蔽,对应的位置会被替换为[MASK]令牌。然后通过训练生成器来预测[MASK]令牌的原始标识。判别器被训练来区分原始数据令牌和被生成器样本替换的令牌。更具体地说,我们通过生成器样本替换被屏蔽的令牌来创建一个损坏的样本 ,并训练判别器来预测 中的哪些令牌与原始令牌匹配:

损失函数为:
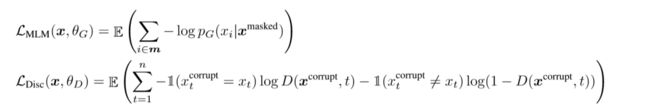
虽然与GAN的训练目标类似,但是有几个重要的区别。首先,如果生成器正好生成了正确的令牌,则认为该令牌是真实的而不是假的,我们发现这样可以适度改善下游任务的结果。更重要的是,生成器是尽可能得进行训练,而不是相反地训练来欺骗判别器。训练生成器是具有挑战性的,因为不可能通过从生成器的采样进行反向传播。虽然可以通过使用强化学习训练生成器来解决这个问题,但这比最大似然训练表现得更差。
3
实验
3.1 实验配置
我们在General Language Understanding Evaluation (GLUE)和Stanford Question Answering (SQuAD)数据集上进行评估。模型架构和大多数超参数都与BERT相同。为了进行微调,对于GLUE,模型在ELECTRA上添加了简单的线性分类器。对于SQuAD,模型在ELECTRA上添加了来自XLNet的问答模块。
3.2模型扩展
作者通过提出和评估模型的几个扩展来改进模型。
Weight Sharing
作者提出通过在生成器和判别器之间共享权重来提高预训练的效率。
Smaller Generators
如果生成器和判别器的大小相同,那么对ELECTRA进行训练所需的计算量将是仅使用MLM训练的两倍。所以作者建议使用更小的生成器来减少这个因素。
Training Algorithms
作者使用两个阶段的训练过程进行实验:
只训练生成器轮。
用生成器的权重初始化鉴别器的权重。
保持生成器权重不变,训练判别器 轮。
3.3 实验结果
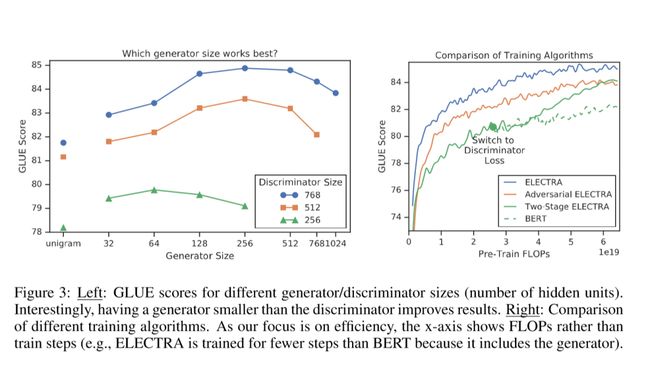
图3
实验结果如图3所示。在两个阶段的训练中,从生成器转换为判别器目标后,下游任务有了显著的提高。虽然比BERT更好,但我们发现对抗训练不如极大似然训练。进一步的分析表明,这种差距是由对抗训练的两个问题造成的。首先作者认为准确率较低的主要原因是因为强化学习的样本效率较低。其次,反向训练的生成器会产生一个低熵输出分布,其中大多数集中在一个令牌上,这导致生成器样本中不具备多样性。
4
总结
本文提出了一种新的自监督语言表示学习任务——替换令牌检测。其核心思想是训练一个文本编码器来区分输入令牌和由一个小型生成器产生样本。相比之下,我们的预训练目标是更加有效率的,并且在后续任务中取得更好的表现,甚至在使用相对少量的计算资源时也能很好地工作,作者希望这将使开发和应用预训练好的文本编码器能更容易被研究人员和实践人员使用,而不需要使用那么多的计算资源。
参考资料
原文链接:https://arxiv.org/abs/2003.10555
代码链接:https://github.com/google-research/electra
