人脸检测实现——复现MTCNN系列
项目GitHub地址(博客代码请选择ultramodern分支)
Part1:人脸边框提出网络数据预处理
Part2:人脸边框提出网络模型构建
Part3:人脸边框提出网络的训练
Part4:为精炼网络准备训练数据
Part5:精炼网络的训练
Part6:为输出网络准备训练数据并进行训练
持续更新中
前言
在上一篇文章中,我们已经完成了对P-Net的训练,目前大约完成了1/3的进度。接下来要做的就是通过训练好的P-Net,生成P-Net的预测结果,首先经过一次人工标注,喂给R-Net进行训练,这样R-Net就学会了如何精炼预测结果。
这里可能会问为什么要P-Net的预测结果,而不能像训练P-Net一样,直接从原素材中直接生成训练样本,这是因为R-Net就是为了精简P-Net预测结果的神经网络,因此用P-Net的预测结果做训练样本更准确。
开始
检测器
我们要用P-Net检测人脸,就要初始化一个P-Net并将其权重参数恢复到我们储存的最好的一个状态。检测器就是用来做这个的,负责初始化还原网络并执行检测任务的一个类。
class FCNDetector(object):
"""
Dectector for Fully Convolution Network.
用于全卷积网络的检测器
"""
def __init__(self, net_factory, model_path):
self.model = net_factory()
root = tf.train.Checkpoint(model=self.model)
root.restore(tf.train.latest_checkpoint(model_path)).assert_existing_objects_matched()
def predict(self, databatch):
databatch = np.expand_dims(databatch, axis=0)
databatch = tf.cast(databatch, tf.float32)
pred = self.model(databatch)
cls_prob, bbox_pred, _ = pred
cls_prob = np.array(cls_prob)
bbox_pred = np.array(bbox_pred)
assert(cls_prob.shape[3]==2 and bbox_pred.shape[3]==4)
cls_prob = np.squeeze(cls_prob, axis=0)
bbox_pred = np.squeeze(bbox_pred, axis=0)
return cls_prob, bbox_pred
经过这样的封装,我们就可以很简单的获得对应网络的输出。
PNet = FCNDetector(P_Net, model_path[0])
results = PNet.predict(databatch)
除了用来封装模型的类,我们还需要一个用来检测人脸的类,它集合了所有检测器,包括R-Net和O-Net,后面O-Net预测时,是同时需要P-Net的预测结果和R-Net的预测结果的。
我们且叫它MtcnnDetector
class MtcnnDetector(object):
def __init__(self,
detectors,
min_face_size=20,
stride=2,
threshold=[0.6, 0.7, 0.7],
scale_factor=0.79,
slide_window=False):
self.pnet_detector = detectors[0]
self.rnet_detector = detectors[1]
self.onet_detector = detectors[2]
self.min_face_size = min_face_size
self.stride = stride
self.thresh = threshold
self.scale_factor = scale_factor
self.slide_window = slide_window
def convert_to_square(self, bbox):
"""
把输入边框变成正方形状,以最长的边为基准,不改变中心点。
"""
def calibrate_box(self, bbox, reg):
"""
calibrate bboxes
"""
def generate_bbox(self, cls_map, reg, scale, threshold):
"""
generate bbox from feature cls_map according to the threshold.
"""
def processed_image(self, image, scale):
'''
rescale/resize the image according to the scale by multiply width and height with scale
'''
def pad(self, bboxes, w, h):
"""
pad the the bboxes, also restrict the size of it
"""
def detect_pnet(self, im):
"""
Get face candidates through pnet
"""
def detect_rnet(self, im, dets):
"""
Get face candidates using rnet
"""
def detect_onet(self, im, dets):
"""
Get face candidates using onet
"""
def detect(self, img):
"""
Detect face over image
"""
def detect_face(self, imgs_path, pnet_detections=None, rnet_detections=None):
def detect_single_image(self, im):
在这个类中,我们会汇集很多相关方法,其中目前最重要的就是用P-Net检测输入,也是我接下来要讲的方法。
运用训练好的P-Net进行人脸检测
我们已知P-Net是一个全卷机网络(FCN),它可以接受任意大小的输入,而通过对P-Net结构分析。我们可以得出,在规定最小脸的大小情况下,在检测前对图像进行12/最小脸大小倍缩放操作就可以保证网络输出的每一个像素最小至少也是一张脸的卷积结果,而不会出现脸中的某个区域。可以减少时间开销。
current_scale = float(net_size) / self.min_face_size
获得了scale就可以对图像进行处理了,切记对rgb值的处理要和喂给网络训练时的操作一致。
im_resized = self.processed_image(im, current_scale)
接下来就可以循环缩放图片进行人脸检测,这是因为P-Net的感受野只有12个像素,对于超过12个像素的脸,必须对其进行缩放才能被网络检测出来,否则输入的只是脸的一部分区域。道理如下图所示,当然我们不是通过这种滑动窗口的方式进行检测的。
current_height, current_width, _ = im_resized.shape
all_boxes = list()
while min(current_height.value, current_width.value) > net_size:
在缩放检测循环中:
cls_cls_map, reg = self.pnet_detector.predict(im_resized)
# scale_factor is 0.79 in default
current_scale *= self.scale_factor
im_resized = self.processed_image(im, current_scale)
current_height, current_width, _ = im_resized.shape
在循环中,我们还需要根据网络输出的特征图进行反采样从而得到人脸边框。
boxes = self.generate_bbox(cls_cls_map[:, :, 1], reg, current_scale, self.thresh[0])
最终保留与gt nms的结果大于0.5的边框
keep = py_nms(boxes[:, :5], 0.5, 'Union')
boxes = boxes[keep]
all_boxes.append(boxes)
接下来我们看看boxes = self.generate_bbox(cls_cls_map[:, :, 1], reg, current_scale, self.thresh[0])中发生了什么
def generate_bbox(self, cls_map, reg, scale, threshold):
"""
generate bbox from feature cls_map according to the threshold.
Parameters:
----------
cls_map: numpy array , n x m
detect score for each position
reg: numpy array , n x m x 4
bbox
scale: float number
scale of this detection
threshold: float number
detect threshold
Returns:
-------
bbox array:[x1, y1, x2, y2, score, x1_offset, y1_offset, x2_offset, y2_offset]
x and y are the coordinate of base anchor which unsampled from feature map.
x和y都是根据特征图反采样得来的坐标,表示特征图这个点表达了原图哪个地方的特征
x1_offset and y1_offset are the prediction of PNet.
x1_offset和y1_offset都是PNet的预测结果。
"""
# 因为只有一个最大池化层,所以反采样只用乘以二就行了
stride = 2
# stride = 4
cellsize = 12
# cellsize = 25
# index of class_prob larger than threshold
t_index = np.where(cls_map > threshold)
# find nothing
if t_index[0].size == 0:
return np.array([])
# offset
dx1, dy1, dx2, dy2 = [reg[t_index[0], t_index[1], i] for i in range(4)]
reg = np.array([dx1, dy1, dx2, dy2])
score = cls_map[t_index[0], t_index[1]]
boundingbox = np.vstack([np.round((stride * t_index[1]) / scale),
np.round((stride * t_index[0]) / scale),
np.round((stride * t_index[1] + cellsize) / scale),
np.round((stride * t_index[0] + cellsize) / scale),
score,
reg])
return boundingbox.T
简单的说就是进行了反采样。该方法接受一个人脸分类的特征图,根据网络结构进行反采样。
该方法中,最后输出是
boundingbox = np.vstack([np.round((stride * t_index[1]) / scale),
np.round((stride * t_index[0]) / scale),
np.round((stride * t_index[1] + cellsize) / scale),
np.round((stride * t_index[0] + cellsize) / scale),
score,
reg])
return boundingbox.T
而t_index = np.where(cls_map > threshold)是特征图中大于阈值的索引值,就是符合人脸的那个位置,但是这个位置是特征图上的位置,我们必须把它反映射到原图上,在原图上这代表一个区域。
boundingbox前4个值代表的就是原图中的区域,比如第一个值,(stride * t_index[1])计算出原图区域左上角的横坐标值(由于P-Net中只有一个最大池化层,因此在反采样时,步长只需要设置为2即可),/ scale是因为我们在预测时对图像进行过缩放。reg是人脸边框的回归值,用于修正预测出来的人脸边框。
这里解释一下这个修正存在的意义。
要知道,特征图的产生过程大致如下动图所示,图中绿色为经过卷积神经网络产生的特征图,下面白色的虚线表示的原图中的每个像素。
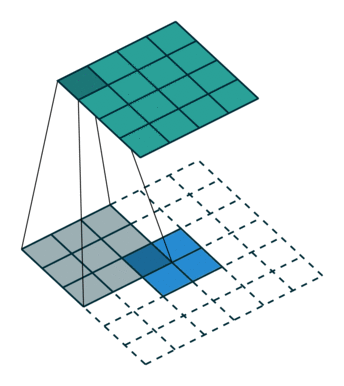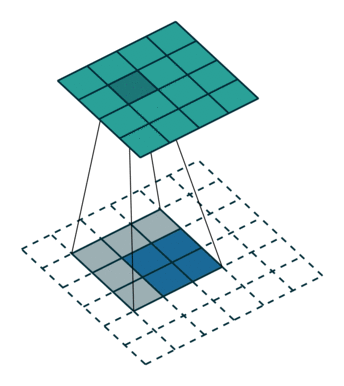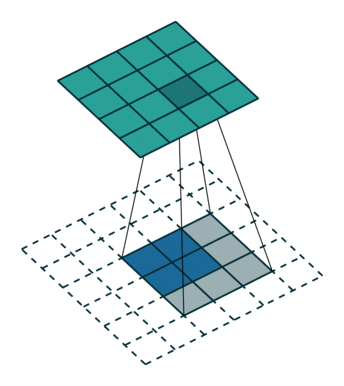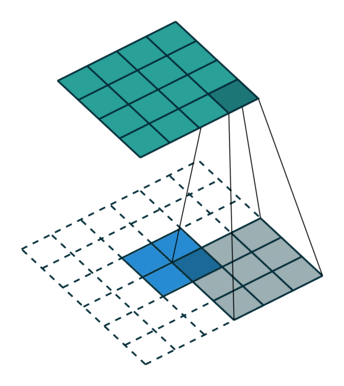
在我们的代码中,我们的特征图就是一个
mxnx2的数组。特征图上,每一个位置都有一个值,代表网络预测的分数,代表其为人脸的概率。而由于特征图上每一个像素的位置都代表了原图中特定区域,因此我们可以反推出原图中特定区域的位置。但是这个区域是固定的,并不一定与实际人脸边框吻合,因此需要经过微调、修正。
最后,将预测出来的人脸边框进行修正,最后一个值是得分score。
boxes_c = np.vstack([all_boxes[:, 0] + all_boxes[:, 5] * bbw,
all_boxes[:, 1] + all_boxes[:, 6] * bbh,
all_boxes[:, 2] + all_boxes[:, 7] * bbw,
all_boxes[:, 3] + all_boxes[:, 8] * bbh,
all_boxes[:, 4]])
将每一张图片都喂给P-Net进行预测
要为R-Net训练准备数据,就要把所有图片都喂给P-Net获取结果。
#这是为了方便理解的极度精简版本
def detect_face(self, imgs_path):
for i, img_path in enumerate(imgs_path):
im = tf.io.read_file(img_path)
im = tf.image.decode_jpeg(im, channels=3)
_, boxes_c, _ = self.detect_pnet(img)
all_boxes.append(boxes_c)
return all_boxes
由于这个过程相当耗时,为了方便,我们需要将这些检测出来的边框存储下来。这时便用到了pickle模块。
pickle是python语言的一个标准模块,安装python后已包含pickle库,不需要单独再安装。
pickle模块实现了基本的数据序列化和反序列化。通过pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,永久存储;通过pickle模块的反序列化操作,我们能够从文件中创建上一次程序保存的对象。
引自pickle库的使用详解
开始着手为精炼网络准备训练数据
在把上面的工作完成后,我们就可以开始为R-Net准备训练数据了。
首先就是初始化P-Net检测器。
PNet = FCNDetector(P_Net, model_path[0])
detectors[0] = PNet
再初始化一个MtcnnDetector类
mtcnn_detector = MtcnnDetector(detectors=detectors, min_face_size=min_face_size,
stride=stride, threshold=thresh, slide_window=slide_window)
加载数据集数据并喂给P-Net进行检测。
data = load_wider_face_gt_boxes(filename, basedir)
detections, _ = mtcnn_detector.detect_face(data.keys, pnet_detections, rnet_detections) #调用训练好的pnet,返回的是candidate
将检测的结果写到文件中序列化
# 把所有candidate写到文件中序列化
save_file = os.path.join(save_path, "detections.pkl")
with open(save_file, 'wb') as f:
pickle.dump(detections, f,1)
print("save done.")
最后根据检测结果与ground true的IoU值分成pos, neg, part样本。
def save_hard_example(net, data,save_path):
"""
Parameter
--------------
data: gt_data
"""
# load ground truth from annotation file
# format of each line: image/path [x1,y1,x2,y2] for each gt_box in this image
im_idx_list = data['images']
gt_boxes_list = data['bboxes']
num_of_images = len(im_idx_list)
# 准备要写入的文件
neg_label_file = "DATA/%d/neg_%d.txt" % (image_size, image_size)
neg_file = open(neg_label_file, 'w')
pos_label_file = "DATA/%d/pos_%d.txt" % (image_size, image_size)
pos_file = open(pos_label_file, 'w')
part_label_file = "DATA/%d/part_%d.txt" % (image_size, image_size)
part_file = open(part_label_file, 'w')
#加载检测结果
det_boxes = pickle.load(open(os.path.join(save_path, 'detections.pkl'), 'rb'))
assert len(det_boxes) == num_of_images, "incorrect detections or ground truths"
# index of neg, pos and part face, used as their image names
n_idx = 0
p_idx = 0
d_idx = 0
image_done = 0
#im_idx_list image index(list)
#det_boxes detect result(list)
#gt_boxes_list gt(list)
for im_idx, dets, gts in zip(im_idx_list, det_boxes, gt_boxes_list):
gts = np.array(gts, dtype=np.float32).reshape(-1, 4)
if image_done % 100 == 0:
print("%d images done" % image_done)
image_done += 1
if dets.shape[0] == 0:
continue
img = cv2.imread(im_idx)
#change to square
dets = convert_to_square(dets)
dets[:, 0:4] = np.round(dets[:, 0:4])
neg_num = 0
for box in dets:
x_left, y_top, x_right, y_bottom, _ = box.astype(int)
width = x_right - x_left + 1
height = y_bottom - y_top + 1
# ignore box that is too small or beyond image border
if width < 20 or x_left < 0 or y_top < 0 or x_right > img.shape[1] - 1 or y_bottom > img.shape[0] - 1:
continue
# compute intersection over union(IoU) between current box and all gt boxes
Iou = IoU(box, gts)
cropped_im = img[y_top:y_bottom + 1, x_left:x_right + 1, :]
resized_im = cv2.resize(cropped_im, (image_size, image_size),
interpolation=cv2.INTER_LINEAR)
# save negative images and write label
# Iou with all gts must below 0.3
if np.max(Iou) < 0.3 and neg_num < 60:
#save the examples
save_file = get_path(neg_dir, "%s.jpg" % n_idx)
# print(save_file)
neg_file.write(save_file + ' 0\n')
cv2.imwrite(save_file, resized_im)
n_idx += 1
neg_num += 1
else:
# find gt_box with the highest iou
idx = np.argmax(Iou)
assigned_gt = gts[idx]
x1, y1, x2, y2 = assigned_gt
# compute bbox reg label
offset_x1 = (x1 - x_left) / float(width)
offset_y1 = (y1 - y_top) / float(height)
offset_x2 = (x2 - x_right) / float(width)
offset_y2 = (y2 - y_bottom) / float(height)
# save positive and part-face images and write labels
if np.max(Iou) >= 0.65:
save_file = get_path(pos_dir, "%s.jpg" % p_idx)
pos_file.write(save_file + ' 1 %.2f %.2f %.2f %.2f\n' % (
offset_x1, offset_y1, offset_x2, offset_y2))
cv2.imwrite(save_file, resized_im)
p_idx += 1
elif np.max(Iou) >= 0.4:
save_file = os.path.join(part_dir, "%s.jpg" % d_idx)
part_file.write(save_file + ' -1 %.2f %.2f %.2f %.2f\n' % (
offset_x1, offset_y1, offset_x2, offset_y2))
cv2.imwrite(save_file, resized_im)
d_idx += 1
neg_file.close()
part_file.close()
pos_file.close()