C++ Primer 学习笔记(持续更新......)
本笔记主要是一个记录,整理和总结一下C++学习过程中的知识点。
- struct和class 区别:两个关键字都是进行类的定义。struct也可以定义类,和class定义的类唯一不同之处就在于默认的初始访问级别,struct在不声明public或者private的时候默认是public,class是private。
容器的迭代器:是一种检查容器内元素并遍历元素的数据类型 ,可以理解成指针。比如vector的迭代器:
vector::iterator iter = ivec.begin() //这就是定义了iter这个迭代器,指向ivec的第一个元素 *iter = 0//将ivec的第一个元素置零 for(vector ::iterator iter = ivec.begin(); iter!= ivec.end();++iter) *iter = 0; //将所有元素置零 如果关键字是const_iterator,那么就不允许进行赋值
- * 与 &: *是解引用操作符,用来获取指针所指向的对象,&是引用操作符,用来获取地址。
指针与引用: 指针保存的是另外一个对象的地址,一般初始化方法比如:int *p = &a; int *p = 0;(此时表示不指向任何对象),注意,不要使用未初始化的指针。一个有效的指针一定是如下三种状态之一:1. 保存一个特定对象的地址;2。指向某个对象后面的另一对象,如 node *a = n->next;3. 0值
对指针的操作:对指针进行解引用操作能够访问所指的对象,也可以直接修改指针本身的值,使其指向另外一个对象。
引用:实际是定义的一个别名,比如:int &ra = a; 之后对ra的操作就是直接改变a的值。
指针和引用的区别:引用总是指向某个对象,所以定义引用的时候没初始化是错误的;对引用进行赋值改变的是指向的对象的值,而不是让该引用指向另外的对象。
指针对数组的操作:int ia[] = {0,2,3,6,8}; int *ip = ia;// ip points to ia[0] ip = &ia[4]// ip points to ia[4] ip = ia; int *ip2 = ip + 4;// ip2 points to ia[4] *(ip+4); // 8 //多维数组 int ia[3][4] = {{0,1,2,3},{4,5,6,7},{8,9,10,11}}; int (*pia)[4] = ia; cout<<*(*pia+1)<箭头操作符与点操作符: 箭头操作符->实际上是一个点操作符和解引用操作符的同义词,比如:
classa *pa = &ca; (*pa).func(); //其实等同于: pa->func() //箭头操作符是指针专用函数参数传递: 分为值传递,指针形参,引用形参。其中值传递是形参复制实参,调用函数里面不影响实参;指针传递是形参复制实参指针,调用函数并不影响实参指针,但是会影响指针指向的对象;引用传递会影响到实参。
有些时候,需要用到指针传递,比如一个简单的swap函数,swap(int *a,int *b),在调用的时候就是swap(&x,&y),这样在书写的时候比较麻烦。我们还可以用引用传递来代替指针传递,效果是一样的,swap函数定义为:swap(int &a, int &b),调用的时候比较简单:swap(x,y)。调用的过程中,发生了两个引用类型的变量定义:int &a = x,int &b = y. 即a,b分别是x,y的别名。new函数返回的是一个指针
二叉树前序,中序,后序遍历的非递归实现:
#include#include #include using namespace std; struct TreeNode { int val; TreeNode *left; TreeNode *right; TreeNode(int x) : val(x), left(NULL), right(NULL) {} }; class Solution { public: vector midorderTraversal(TreeNode *root) { vector vec; if(root == NULL){return vec;} stack preorderTraversal(TreeNode *root) { vector vec; if(root == NULL){return vec;} stack postorderTraversal(TreeNode *root) { vector vec; if(root == NULL) return vec; stack res = s.midorderTraversal(p1); for(int i=0; i < res.size();i++){ cout< BFS 广度优先搜索:广度优先搜索是遍历图的一种常用方法,流程如下:
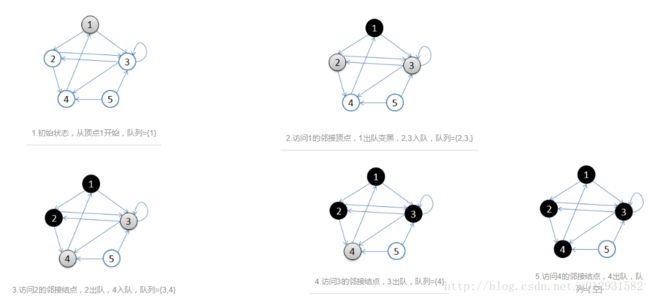
广度优先搜索在进一步遍历图中顶点之前,先访问当前顶点的所有邻接结点。
a .首先选择一个顶点作为起始结点,并将其染成灰色,其余结点为白色。
b. 将起始结点放入队列中。
c. 从队列首部选出一个顶点,并找出所有与之邻接的结点,将找到的邻接结点放入队列尾部,将已访问过结点涂成黑色,没访问过的结点是白色。如果顶点的颜色是灰色,表示已经发现并且放入了队列,如果顶点的颜色是白色,表示还没有发现
d. 按照同样的方法处理队列中的下一个结点。
基本就是出队的顶点变成黑色,在队列里的是灰色,还没入队的是白色。
用一幅图来表示:
#include#include #define N 5 using namespace std; int maze[N][N] = { { 0, 1, 1, 0, 0 }, { 0, 0, 1, 1, 0 }, { 0, 1, 1, 1, 0 }, { 1, 0, 0, 0, 0 }, { 0, 0, 1, 1, 0 } }; int visited[N + 1] = { 0, }; void BFS(int start) { queue Q;//这里只是简单一个例子,实际中Q常用一个邻接表来表示 Q.push(start); visited[start] = 1; while (!Q.empty()) { int front = Q.front(); cout << front << " "; Q.pop(); for (int i = 1; i <= N; i++) { if (!visited[i] && maze[front - 1][i - 1] == 1) { visited[i] = 1; Q.push(i); } } } } int main() { for (int i = 1; i <= N; i++) { if (visited[i] == 1) continue; BFS(i); } return 0; } 深度优先搜索在搜索过程中访问某个顶点后,需要递归地访问此顶点的所有未访问过的相邻顶点。
初始条件下所有节点为白色,选择一个作为起始顶点,按照如下步骤遍历:
a. 选择起始顶点涂成灰色,表示还未访问
b. 从该顶点的邻接顶点中选择一个,继续这个过程(即再寻找邻接结点的邻接结点),一直深入下去,直到一个顶点没有邻接结点了,涂黑它,表示访问过了
c. 回溯到这个涂黑顶点的上一层顶点,再找这个上一层顶点的其余邻接结点,继续如上操作,如果所有邻接结点往下都访问过了,就把自己涂黑,再回溯到更上一层。
d. 上一层继续做如上操作,知道所有顶点都访问过。
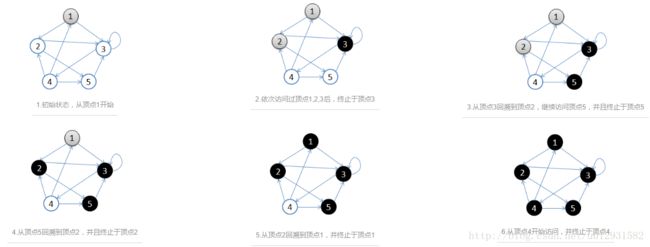
最简单的想法就是利用递归来实现:
#include#define N 5 using namespace std; int maze[N][N] = { { 0, 1, 1, 0, 0 }, { 0, 0, 1, 0, 1 }, { 0, 0, 1, 0, 0 }, { 1, 1, 0, 0, 1 }, { 0, 0, 1, 0, 0 } }; int visited[N + 1] = { 0, }; void DFS(int start) { visited[start] = 1; for (int i = 1; i <= N; i++) { if (!visited[i] && maze[start - 1][i - 1] == 1) DFS(i); } cout << start << " "; } int main() { for (int i = 1; i <= N; i++) { if (visited[i] == 1) continue; DFS(i); } return 0; } 非递归的实现如下:
#include#include #include #define N 5 using namespace std; int maze[N][N] = { { 0, 1, 1, 0, 0 }, { 0, 0, 1, 1, 0 }, { 0, 1, 1, 1, 0 }, { 1, 0, 0, 0, 0 }, { 0, 0, 1, 1, 0 } }; int visited[N + 1] = { 0, }; void DFS(int start) { stack s; s.push(start); while(!s.empty()){ int cur = s.top(); s.pop(); if(visited[cur] == 0){ cout< 可以看出来,BFS用到了队列,DFS用到了栈
extern 关键字的作用:只进行声明而不定义,表示是当前变量或者函数的定义不在当前模块(文件)内,在其他的模块中,告诉编译器在其它文件中找这个变量或者函数的定义。一般都把一些经常用到的枚举和变量之类的写在.h头文件中。这样要引用时直接include “头文件名”就可以了调用里面所有的枚举和变量了。在大型项目中,引用别的.c文件中的函数则只能用extern,因为.c文件是不能 include的。所以想引用别的.c文件中的函数和全局变量、枚举等等的就只能用extern。
static 关键字的作用:在C语言中,static主要定义全局静态变量,定义局部静态变量,定义静态函数:
一、 定义全局静态变量 :在全局变量前面加上关键字static,该全局变量变成了全局静态变量。全局静态变量有以下特点: (1) 在全局数据区内分配内存 (2) 如果没有初始化,其默认值为0 (3) 该变量在本文件内从定义开始到文件结束可见 二、 定义局部静态变量:在局部静态变量前面加上关键字static,该局部变量便成了静态局部变量。静态局部变量有以下特点: (1) 该变量在全局数据区(静态存储区包括全局变量和static变量)分配内存 (2) 如果不显示初始化,那么将被隐式初始化为0 (3) 它始终驻留在全局数据区,直到程序运行结束 (4) 其作用域为局部作用域,当定义它的函数或语句块结束时,其作用域随之结束。 三、 定义静态函数:在函数的返回类型加上static关键字,函数即被定义成静态函数。静态函数有以下特点: (1) 静态函数只能在本源文件中使用 (2) 在文件作用域中声明的inline函数默认为static 在C++语言中新增了两种作用:定义静态数据成员或静态函数成员 一, 定义静态数据成员。静态数据成员有如下特点: (1) 内存分配:在程序的全局数据区分配 (2) 初始化和定义:静态数据成员定义时要分配空间,所以不能在类声明中初始化(但是static const 可以在类的定义中初始化) 二, 静态成员函数。静态成员函数与类相联系,不与类的对象相联系。静态成员函数不能访问非静态数据成员。原因很简单,非静态数据成员属于特定的类实例,静态成员函数主要用于对静态数据成员的操作。静态成员函数不能被声明为const,和虚函数,静态成员函数是类 的组成部分,而不是类对象的组成部分。 (1) 静态成员函数没有this指针。 static变量在程序刚开始运行时就完成唯一一次初始化。比如在一个函数中 int fun(void){ static int count = 10; return count--; } 执行多次fun函数,count也只是定义一次。全局变量和局部变量:全局变量就是定义在函数体外的变量。
宏定义,#define 标识符 字符串
其中的标识符就是所谓的符号常量,也称为“宏名”。
预处理(预编译)工作也叫做宏展开:将宏名替换为字符串。
#define 标识符 字符串
其中的标识符就是所谓的符号常量,也称为“宏名”。
预处理(预编译)工作也叫做宏展开:将宏名替换为字符串。虚析构函数,基类的析构函数通常为虚函数,这样做是为了当用一个基类的指针删除一个派生类的对象时,派生类的析构函数会被调用。 http://blog.csdn.net/starlee/article/details/619827
c++多态性,是通过虚函数来实现的,简单地概括为一个接口,多种方法。程序在运行时才决定调用的函数,它是面向对象编程领域的核心概念。多态与非多态的实质区别就是函数地址是早绑定还是晚绑定。如果函数的调用,在编译器编译期间就可以确定函数的调用地址,并生产代码,是静态的,就是说地址是早绑定的。而如果函数调用的地址不能在编译器期间确定,需要在运行时才确定,这就属于晚绑定。声明基类的指针,利用该指针指向任意一个子类对象,调用相应的虚函数,可以根据指向的子类的不同而实现不同的方法。
纯虚函数:在基类中实现纯虚函数的方法是在函数原型后加“=0”
map 底层是用红黑树(二叉查找树,平衡树)来实现的,查找时间复杂度为o(logn)。
malloc 和 new 的区别:,malloc与free是C++/C语言的标准库函数,new/delete是C++的运算符。
由于malloc/free是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于malloc/free;
new 返回的是指定类型的指针,malloc返回的是void指针。const, 把对象转换为常量。定义的时候必须初始化。
- extern 可以使用其它文件的变量,如:file1中,int counter,file 2 中, extern int counter. 对于const常量,必须显式指定为extern,file1中,extern int counter = 0; file2 中,extern int counter。
- 虚函数是基类希望派生类重新定义的,可以被直接调用,基类中希望派生类继承的函数不能定义为虚函数。
- 纯虚函数定义如下:virtual int func() = 0; 不能够被直接调用,只能在派生类中重写。因为在很多情况下,基类本身生成对象是不合情理的。例如,动物作为一个基类可以派生出老虎、孔雀等子类,但动物本身生成对象明显不合常理。含有纯虚函数的类成为抽象类,不能生成对象。
- 虚析构函数。作用是基类指针删除一个派生类对象时,派生类的析构函数也会被调用。
- 动态绑定,多态。可以编写程序使用继承层次中任意类型的对象,无需关心对象的具体类型。通过基类的引用(或指针)调用虚函数时发生动态绑定。引用(或指针)既可以指向基类对象,也可以指向派生类对象,这是关键。被调用函数是由所指对象实际类型决定的。
- vector,相当于一个数组,内存中分配一块连续的内存空间进行存储。在末尾可以进行高效的插入删除,但是不能在头部进行插入删除。内部插入的效率很低,可以支持随机访问[],节省空间。
- list,是一个双向链表,内部插入删除很方便,可以在两端进行插入和删除的操作,不能进行内部的随机访问,内存不连续。
- deque,双端队列,类似vector,但是可以在开头高效地进行插入删除,可随机访问[],内部插入或者删除,但是占用内存多。
- 二叉树的前中后,层次遍历:
// Example program
#include <iostream>
#include <string>
#include <queue>
using namespace std;
struct TreeNode{
int v;
TreeNode* left;
TreeNode* right;
TreeNode(){
left = NULL;
right = NULL;
}
TreeNode(int x){
v = x;
left = NULL;
right = NULL;
}
};
void preOrder(TreeNode* proot){
if(!proot) return;
cout<<proot->v<<" ";
preOrder(proot->left);
preOrder(proot->right);
}
void midOrder(TreeNode* proot){
if(!proot) return;
midOrder(proot->left);
cout<<proot->v<<" ";
midOrder(proot->right);
}
void postOrder(TreeNode* proot){
if(!proot) return;
postOrder(proot->left);
postOrder(proot->right);
cout<<proot->v<<" ";
}
void levelOrder(TreeNode* proot){
queue<TreeNode*> arr;
arr.push(proot);
while(!arr.empty()){
TreeNode* tmp = arr.front();
cout<<tmp->v<<" ";
if(tmp->left) arr.push(tmp->left);
if(tmp->right) arr.push(tmp->right);
arr.pop();
}
}
int main()
{
TreeNode* p1 = new TreeNode(1);
TreeNode* p2 = new TreeNode(2);
TreeNode* p3 = new TreeNode(3);
TreeNode* p4 = new TreeNode(4);
TreeNode* p5 = new TreeNode(5);
TreeNode* p6 = new TreeNode(6);
TreeNode* p7 = new TreeNode(7);
TreeNode* p8 = new TreeNode(8);
p1->left = p2;
p2->left = p4;
p4->left = p7;
p1->right = p3;
p2->right = p5;
p3->right = p6;
p6->right = p8;
preOrder(p1);
cout<<endl;
midOrder(p1);
cout<<endl;
postOrder(p1);
cout<<endl;
levelOrder(p1);
return 0;
}