mapreduce的执行流程以及shuffle过程
1、mapreduce概述
a.mapreduce是一种分布式的计算模型,由google提出,主要用于搜索领域,解决海量数据的计算问题。
b.mapreduce由两个阶段组成,map和reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算。
c.这两个函数的key,value对,表示函数的输入信息。
2.mapreducer的作业执行流程:
图解:
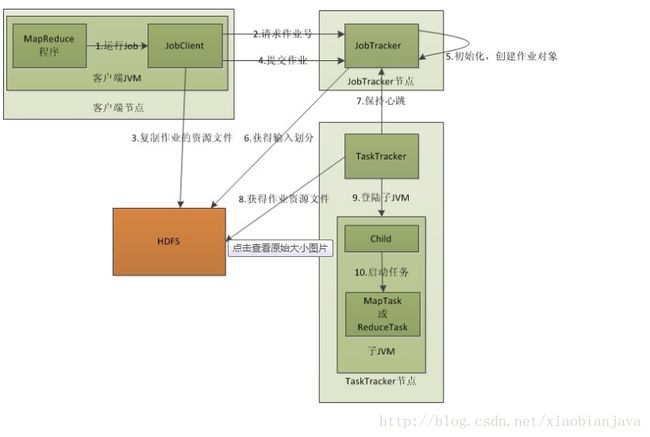
3.MR过程中各个角色的作用:
1)
JobTracker
:
负责接收用户提交的作业,负责启动,跟踪任务,
:初始化作业,分配作业协调监控整个作业
JobSubmissionProtocol是JobClient和JobTracker通信的接口
InterTrackerProtocol是TaskTracker与JobTracker通信的接口
2)JobClient::用户作业与JobTracker交互的主要接口,负责提交作业,负责启动,跟踪任务的执行,访问任务状态和日志
3)TaskTracker:定期与JobTracker通信,执行Map和Reduce任务
4)HDFS:保存作业的数据,配置,jar包,结果
4.MR执行流程细节:
1)作业提交:
a.提交作业之前,需要对作业进行配置:编写自己的MR程序;配置作业,包括输入输出路径等
b.提交作业,配置完成后,通过JobClient提交
c.具体功能:
JobClient与JobTracker通信得到一个jar包的存储路径和jobid;
输入输出路径检查是否存在
将job的jar包拷贝到HDFS
计算输入切片,将分片信息写到job.split中,切片的数量决定要启动几个mao任务
写job.xml
真正提交作业
2)作业初始化:
a.客户端提交作业后,JobTracker会将作业加入到作业调度器中,是一个队列的结构,然后进行作业的调度,默认是FIFO.
b.具体功能:
作业初始化主要是指JobInprocess中完成
读取分片信息
创建task包括map和reduce任务
创建TaskInProcess执行task,包括map任务和reduce任务
3)任务分配:
a.TaskTracker与JobTracker之间的通信和任务分配时通过心跳机制来完成的
b.TaskTracker会主动的定期向JobTraker发送心跳消息,询问是否有任务要做,如果有就会申请到任务。
4)任务执行:
a.如果TaskTracker拿到任务,会将所有的信息拷贝到本地,包括任务的jar包(程序代码),配置,分片信息(数据的描述信
息)等。
b.TaskTacker中的localizeJob()方法会被调用进行本地化,拷贝job.jar,jobconf,job.xm到本地
c.TaskTracker调用launchTaskTrackerForJob()方法加载启动任务
d.MapTaskRunner和ReducerTaskRunner分别启动child进程来执行相应的任务
5)状态的更新:
a.Task会定期的向TaskTracker汇报执行情况
b.TaskTracker会定期的手机所在集群上的所有task的信息,并向JobTracker汇报
c.JobTracker会根据所有的TaskTracker汇报上来的信息进行汇总
6)任务完成:
a.JobTracker实在接收到最后一个任务后,才将任务标记为成功
b.将数据写入到HDFS中
7)错误处理:
a.JobTracker失败,hadoop1.x中的NameNode存在单点登录的问题,hadoop2.x解决了这个问题
b.TaskTracker失败
TaskTracker崩溃了会停止向JobTracker发送心跳信息
JobTracker会将TaskTracker从等待的任务池中移除,并将任务转移到其他的地方执行
JobTracker将TaskTracker加入到黑名单中
c.Task失败
任务失败,会向TaskTracker抛出异常
任务挂起
5.mapreduce的分组,排序,combiner
1)分区(partioner):
分区是将具有相同属性的数据写到同一个分区中,目的是为统计计算提高效率。
分区组件的输入键值对是map输出的键值对,根据分区的映射逻辑,将数据分区。
实现分区的步骤:
a.先分析一下具体的业务逻辑,确定大概有多少个分区b.首先书写一个类,它要继承org.apache.hadoop.mapreduce.Partitioner这个类c.重写public int getPartition这个方法,根据具体逻辑,读数据库或者配置返回相同的数字d.在main方法中设置Partioner的类,job.setPartitionerClass(DataPartitioner.class);e.设置Reducer的数量,job.setNumReduceTasks(6);reduce的数量一定要大于或者等于分区的数量,
hadoop默认的分区方式是:HashPartioner
,即有几个reduer就有几个partitioner,这样数据均衡的分不到reduce中
一个reduce对应一个输出文件
2)排序(sort)
默认情况下,按照map的输出key进行自然顺序的排序,不过也可以自定义排序方式
即业务bean要实现WritableComparable接口,并根据具体的业务逻辑重写compareTo()方法,
然后将这个业务bean作为map的key进行排序
3)规约(Combiner)
a.每一个map可能会产生大量的输出,combiner的作用就是在map端输出先做一次的合并,
以减少传输到reducer的数量
b.combiner最基本是实现本地key的归并,combiner具有类似本地的reducer的功能,是一种特殊的reduce
c.如果不用combiner,那么,所有的结果都是reduce完成,效率会很低下。使用combiner,先完成的map会在本地聚合,
提生速度,也可以用来过滤数据,因为他是在map之后执行,以map的输出作为输入。
注意:
Combiner的输出是Reducer的输入,如果Combiner是可插拔的,添加Combiner绝不能改变最终的计算结果。
所以Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
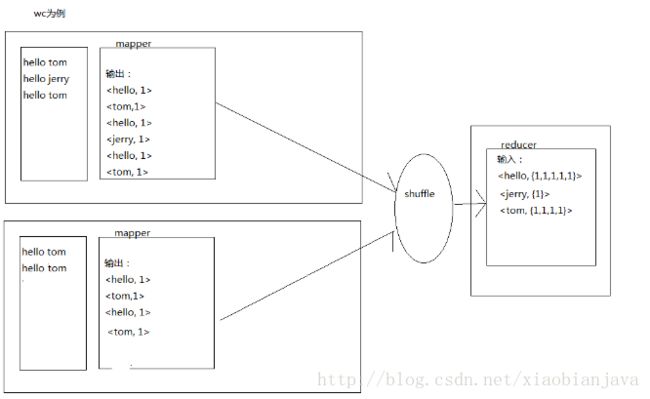

6.mapreduce的shuffle:
1)mapreduce的原理图:
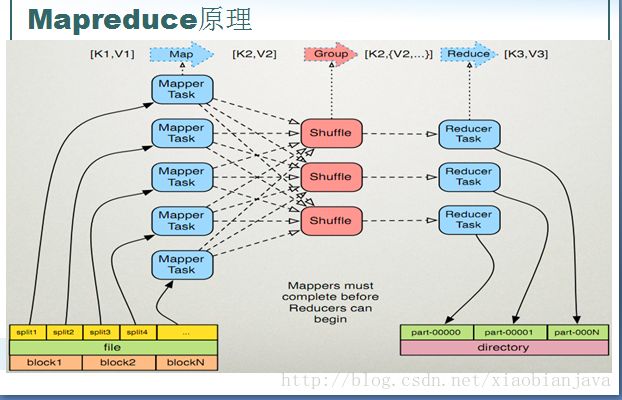
2)shuffle的过程:

3)shuffle过程解读
简略分析:
1.map阶段:
a.每个map有一个环形缓冲区,用于存储任务的输出,。默认大小为100MB(io.sort.mb属性),一旦达到阈值
0.8(io.sort.spill.percent),一个后台程序把内容写到(spill)磁盘的指定目录(mapred.local.dir)下创建的一个溢
出写文件
b.写磁盘前,要partition,sort。如果有combiner,combiner排序后数据
c.等最后记录写完,合并全部溢出写文件作为一个分区排序的文件
2.reduce阶段
a.reducer通过http方式得到输出文件的分区
b.tasktracker为分区文件运行reduce任务,复制阶段把map输出复制到reduce的内存或磁盘、一个map任务的完成,
reduce就开始付诸输出
c.排序阶段合并map输出,然后reduce阶段
详细分析
1.map端:
a.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(64M)为一个分片,当然我们也
可以设置。map的输出结果会暂且保存在一个环形的缓冲区内,当该缓冲区达到阈值时,会在本地文件系统中产生一个
溢出文件,将该缓冲区的数据写入到这个文件中。
b.在写磁盘之前,线程首先根据reducer的数量将数据划分为相同数目的分区,也就是一个reducer任务对应一个分区的数据,
这样做是为了
避免有些reducer任务分配到大量的任务,而有些则分到很少的数据。其实分区就是对数据进行hash的过程。然后对每个分区中的数 据进行排序
,
如果此时设置了combiner,将排序的结果在进行combiner操作,这样做的目的是让尽可能少的数据写入到磁盘中。同时,combiner操 作与map在同一端,数据传输在本地。
c.当map任务输出最后一个记录时,可能会有很多的溢出文件,这是就需要将这些文件合并。合并的过程中不断进行排序和combiner 的操作,
目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减下一复制阶段网络传出的数据量。最后合并成了已分区且排好序的文件。 为了减少网络传输的数据量,
这里可以将数据进行压缩,只要将mapred.compress.map.out设置为true就可以了。
d
.将分区的数据拷贝给相应的reduce任务。因为map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持 心跳。
所以JobTracker中保存了整个集群的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就可以了;。
2.reducer端
a.reduce会收到不同的map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数量相当小,则直接存储在内 存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,堆空间的百分比),如果数量超过了该缓冲区 大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并溢写到磁盘中。
b.随着溢写文件的增多,后台线程会将他们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。
其实不管在reduce端还是map端,都是不停的sort,merge
c.合并的过程中会产生许多的中间文件,但mapreduce会让写入到磁盘的数据尽可能大的少,并且最后一次
合并的结果并没有写到磁盘,而是直接输入到reduce函数