Cuda学习笔记
- CUDA C简介
- 基本操作
- 读取GPU的信息
- CUDA C并行编程
- 向量和
- Julia集
- 线程协作
- 点积的计算
- 申请共享内存
- 每个线程单独工作
- 多个线程协同工作
- 保存归约结果
- 总的代码
- 点积的计算
- 常量内存与事件
- 常量内存
- 事件
- 原子性
- 简介
- 直方图的计算
- 在CPU上计算直方图
- 在GPU上计算直方图
- 全局内存原子操作
- 共享内存原子操作
- 总结
- 散列表的实现
- 散列表
- CPU实现
- GPU多线程下的散列表
CUDA C简介
基本操作
以下是调用GPU的基本操作代码。代码作用是将两个数相加。
其中要注意的是:
1. cudaMemcpy() 函数前两个参数传递的是地址。
2. cudaMalloc() 函数原型为:
cudaError_t cudaMalloc (void **devPtr, size_t size ); 所以调用时首先将第一个参数强制转换为 (void **) 类型,再取地址 & 得到之前定义的那个一维指针地址。
代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 读取GPU的信息
用如下方式读取GPU信息:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include CUDA C并行编程
向量和
使用CUDA C并行编程来计算向量与向量的和:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include >> 第一个参数a表示设备在执行核函数时使用的并行线程块的数量
// 以下代码创建N个线程块在GPU上运行
add<<1>>>(dev_a, dev_b, dev_c);
// 将结果dev_c复制到CPU
cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost);
for (int i = 0; i < N; ++i)
{
printf("%d + %d = %d\n", a[i], b[i], c[i]);
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
} Julia集
首先要在VS和系统路径中加入glut,之后头文件导入就行了。
CPU版本:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
//#include "cuda_gl_interop.h"
#include 改写为GPU版本:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
//#include "cuda_gl_interop.h"
#include 1>>>(dev_bitmap);
//clock_t finish = clock();
//printf( "%f seconds\n", (double)(finish - start) / CLOCKS_PER_SEC );
cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost);
bitmap.display_and_exit();
cudaFree(dev_bitmap);
return 0;
} 线程协作
点积的计算
申请共享内存
首先我们需要申请共享内存,在这个例子中声明的是数组cache:
__shared__ float cache[threadsPerBlock];这里我们需要明白的是,一旦这样声明数组,就会创建与线程块的数量相同的数组cahce,即每个线程块都会对应一个这样的数组cache。我们都知道,共享内存是用于同一个线程块内的线程之间交流的,不同线程块之间是无法通过共享内存进行交流的。另外,数组cache的大小是每个线程块中线程的个数,即线程块的大小。
每个线程单独工作
现在来看每个线程完成的是什么工作!
如果向量长度不是特别长(假设大小等于总线程个数)的话,每个线程只需要工作一次,即计算两个元素的积并保存在中间变量 temp 里。但是实际计算过程中由于向量长度过长,一次计算可能会计算不完,每个线程需要多次计算才能完成所有工作,因此 temp 保存的值可能为多个元素乘积之和,如下图所示:
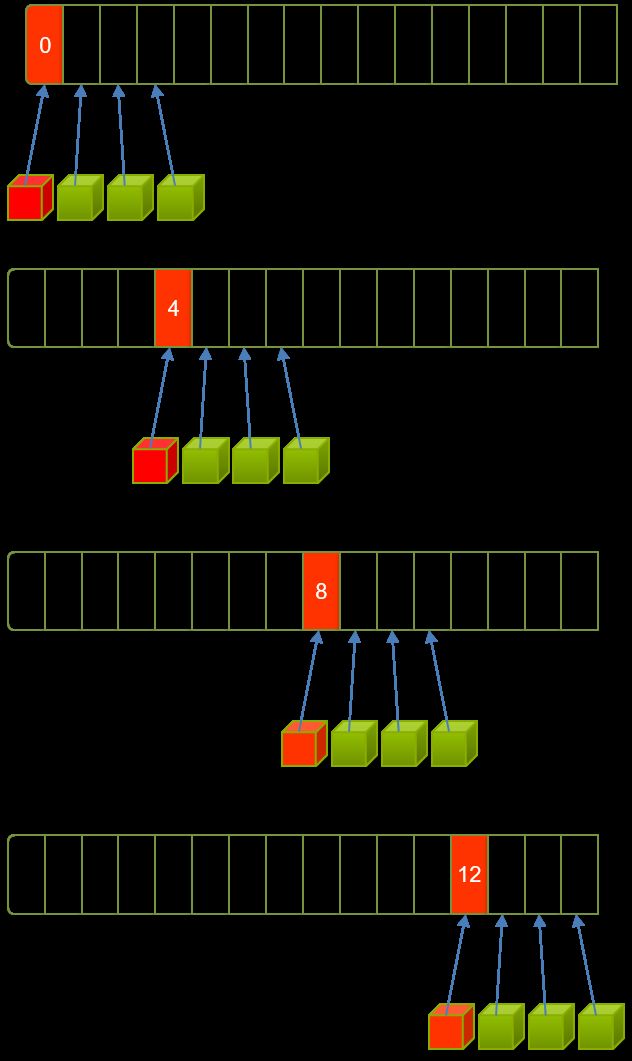
假设数组大小为16,线程总数为4。此时一次并行是无法完成工作的,所以需要多次并行,即每个线程需要做四次工作才可完成计算。
相应的代码如下:
int tid = threadIdx.x + blockIdx.x * blockDim.x;
double tmp = 0;
while (tid < N)
{
tmp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}多个线程协同工作
线程之间通过共享内存进行协作。每个线程将temp的值保存到每个线程块的共享内存(shared memory)中,即数组cache中,相应的代码如下:
cache[cacheIndex] = temp;
__syncthreads();这样每个线程块中对应的数组cache保存的就是每个线程的计算结果。为了节省带宽,这里又采用了并行计算中常用的归约算法,来计算数组中所有值之和,并保存在第一个元素(cache[0])内。这样每个线程就通过共享内存(shared memory)进行数据交流了。具体代码如下所示:
//归约算法将每个线程块上的cache数组归约为一个值cache[0],最终保存在数组c里
int i = blockDim.x /2;
while (i != 0)
{
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads(); //确保每个线程已经执行完前面的语句
i /= 2;
}保存归约结果
现在每个线程块的计算结果已经保存到每个共享数组cache的第一个元素cache[0]中,这样可以大大节省带宽。下面就需要将这些归约结果保存到全局内存(global memory)中。
观察核函数你会发现有一个传入参数——数组c。这个数组是位于全局内存中,每次使用线程块中线程ID为0的线程来将每个线程块的归约结果保存到该数组中,注意这里每个线程块中的结果保存到数组c中与之相对应的位置,即c[blockIdx.x]。
总的代码
#include
const int N = 33 * 1024;
// 线程块里的线程256个,线程格一共有32个线程,这就意味着,每个线程将会计算4次,因为数组元素很大
const int threadsPerBlock = 256;
//
const int blocksPerGrid = Min( 32, (N + threadsPerBlock - 1) / threadsPerBlock );
__global__ void dot(float *a, float *b, float *c)
{
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float tmp = 0;
while (tid < N)
{
tmp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
// 设置cache中对应位置上的值
cache[cacheIndex] = tmp;
// 对线程块中的线程进行同步
__syncthreads();
// 归约,以下代码要求threadPerBlock是2的指数
int i = blockDim.x /2;
while (i != 0)
{
if (cacheIndex < i)
{
cache[cacheIndex] += cache[cacheIndex + i];
}
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
{
c[blockIdx.x] = cache[0];
}
}
int main()
{
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
// 在CPU上分配内存
a = (float*)malloc(N * sizeof(float));
b = (float*)malloc(N * sizeof(float));
partial_c = (float*)malloc(blocksPerGrid * sizeof(float));
// 在GPU上分配内存
cudaMalloc((void**)&dev_a, N * sizeof(float));
cudaMalloc((void**)&dev_b, N * sizeof(float));
cudaMalloc((void**)&dev_partial_c, blocksPerGrid * sizeof(float));
// 初始化
for (int i = 0; i < N; ++i)
{
a[i] = i;
b[i] = i << 1;
}
// 将数组a, b从CPU上复制到GPU
cudaMemcpy(dev_a, a, N * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N * sizeof(float), cudaMemcpyHostToDevice);
// 计算点积
dot<<>>(dev_a, dev_b, dev_partial_c);
// 将partial_c从GPU上复制到CPU
cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid * sizeof(float), cudaMemcpyDeviceToHost);
// 在CPU上完成最终计算
c = 0;
for (int i = 0; i < blocksPerGrid; ++i)
{
c += partial_c[i];
}
#define sum_squares(x) (x*(x+1)*(x*2+1)/6)
printf( "Does GPU value %.6g == %.6g?\n", c, 2 * sum_squares( (N - 1.0) ) );
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
free(a);
free(b);
free(partial_c);
return 0;
}
常量内存与事件
常量内存
常量内存用
__constant__来声明,将把变量的访问限制为只读。与全局内存中读取数据相比,从常量内存中读取相同的数据可以节约内存带宽。
但使用常量内存是否可以使性能变好,可以由事件来计算运行时间判断。
事件
CUDA中事件的本质上是一个GPU时间戳,这个时间戳是在用户制定的时间点上记录的。由于GPU本身支持记录时间戳,因此避免了当使用CPU定时器来统计GPU执行的时间时可能遇到的诸多问题。
其使用过程如下:
首先创建一个起始事件,结束事件,然后记录一个事件,最后告诉CPU在某个事件上需要同步。
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// 在GPU上执行一些工作
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
printf("Time: %.3lf ms\n", elapsedTime);
cudaEventDestroy(start);
cudaEventDestroy(stop);
其中cudaEventRecord函数的第二个参数,书中会在讨论流(stream)的时候再介绍。
原子性
简介
从C/C++的递增运算符入手:
x++;这条语句的操作包括:
- 读取x中的值。
- 将步骤1中读到的值增加1。
- 将递增后的结果写回到x。
现在考虑:如果有两个线程需要对x的值进行递增。会有非常多的调度方式,如果调度方式不正确,将会得到错误的结果。因此我们需要通过某种方式一次性执行完读取-修改-写入三个操作,并且在执行过程中不能被其他线程中断,除非已经完成了这三个操作,否则其他的线程都不能读取或写入x的值。
由于这些操作的执行过程不能分解为更小的部分,因此我们将满足这种条件限制的操作称为原子操作。
CUDA C支持多种原子操作,当有数千个线程在内存访问上发生竞争时,这些操作能够确保在内存上实现安全的操作。
直方图的计算
在CPU上计算直方图
这是一个在CPU上计算直方图的程序,非常简单。
#include
#define SIZE (100*1024*1024)
// 生成随机数据
void* big_random_block( int size )
{
unsigned char *data = (unsigned char*)malloc( size );
for (int i=0; ireturn data;
}
int main()
{
unsigned char *buffer = (unsigned char*)big_random_block( SIZE );
// capture the start time
clock_t start, stop;
start = clock();
unsigned int histo[256];
for (int i = 0; i < 256; i++)
histo[i] = 0;
for (int i = 0; i < SIZE; i++)
histo[buffer[i]]++;
stop = clock();
float elapsedTime = (1.0 * stop - start) / CLOCKS_PER_SEC * 1000.0f;
printf( "Time to generate: %3.1f ms\n", elapsedTime );
long histoCount = 0;
for (int i = 0; i < 256; i++)
{
histoCount += histo[i];
}
printf( "Histogram Sum: %ld\n", histoCount );
free( buffer );
return 0;
}在GPU上计算直方图
如果输入数组足够大,通过多个线程处理缓冲区的不同部分,将会节约大量的计算时间。
不同的线程来读取不同部分的输入数据非常容易。但在计算输入数据的直方图时,多个线程可能同时对输出直方图的同一个元素进行递增。在这种情况下,需要通过原子递增操作来避免问题。
main函数与CPU版本的基本差不多。思路是先分配内存,然后调用GPU计算,然后检验结果是否正确,最后释放内存:
int main()
{
unsigned char *buffer = (unsigned char*)big_random_block( SIZE );
// 初始化计时事件
cudaEvent_t start, stop;
cudaEventCreate( &start );
cudaEventCreate( &stop );
cudaEventRecord( start, 0 );
// 在GPU上为数据分配内存
unsigned char *dev_buffer;
unsigned int *dev_histo;
cudaMalloc( (void**)&dev_buffer, SIZE );
cudaMalloc( (void**)&dev_histo, 256 * sizeof(int) );
cudaMemcpy( dev_buffer, buffer, SIZE, cudaMemcpyHostToDevice );
cudaMemset( dev_histo, 0, 256 * sizeof(int) );
// 计算直方图
/// .......................
/// .......................
// 将GPU上运行后的数据复制到CPU
unsigned int histo[256];
cudaMemcpy( histo, dev_histo, 256 * sizeof(int), cudaMemcpyDeviceToHost );
// 计时结束
cudaEventRecord( stop, 0 );
cudaEventSynchronize( stop );
float elapsedTime;
cudaEventElapsedTime( &elapsedTime, start, stop );
printf( "Time to generate: %3.lf ms\n", elapsedTime );
// 在CPU上检验计算结果是否正确
for (int i = 0; i < SIZE; ++i)
{
histo[buffer[i]]--;
}
for (int i = 0; i < 256; ++i)
{
if (histo[i] != 0)
{
printf( "Failure at %d!\n", i);
}
}
// 释放内存
cudaEventDestroy( start );
cudaEventDestroy( stop );
cudaFree( dev_histo );
cudaFree( dev_buffer );
free( buffer );
return 0;
}出于性能的考虑,这个示例中的核函数调用比通常的核函数调用复杂一点。由于直方图包含256个元素,因此可以在每个线程块中包含256个线程,这种方式不仅方便而且高效。
但是在线程块的数量上还可以有更多选择。比如在100MB数据中共有104 857 600个字节。我们可以启动一个线程块,让每个线程处理409 600个数据元素。同样,还可以启动409 600个线程块,让每个线程处理一个数据元素。
通过一些实验,当线程块的数量为GPU处理器数量的2倍时,具有最优性能。
通过以下代码来实现这个操作。
cudaDeviceProp prop;
cudaGetDeviceProperties( &prop, 0 );
int blocks = prop.multiProcessorCount << 1;
histo_kernel<<256>>>( dev_buffer, SIZE, dev_histo ); 因此完整的main函数如下:
int main()
{
unsigned char *buffer = (unsigned char*)big_random_block( SIZE );
// 初始化计时事件
cudaEvent_t start, stop;
cudaEventCreate( &start );
cudaEventCreate( &stop );
cudaEventRecord( start, 0 );
// 在GPU上为数据分配内存
unsigned char *dev_buffer;
unsigned int *dev_histo;
cudaMalloc( (void**)&dev_buffer, SIZE );
cudaMalloc( (void**)&dev_histo, 256 * sizeof(int) );
cudaMemcpy( dev_buffer, buffer, SIZE, cudaMemcpyHostToDevice );
cudaMemset( dev_histo, 0, 256 * sizeof(int) );
// GPU计算直方图
cudaDeviceProp prop;
cudaGetDeviceProperties( &prop, 0 );
int blocks = prop.multiProcessorCount << 1;
histo_kernel<<256>>>( dev_buffer, SIZE, dev_histo );
// 将GPU上运行后的数据复制到CPU
unsigned int histo[256];
cudaMemcpy( histo, dev_histo, 256 * sizeof(int), cudaMemcpyDeviceToHost );
// 计时结束
cudaEventRecord( stop, 0 );
cudaEventSynchronize( stop );
float elapsedTime;
cudaEventElapsedTime( &elapsedTime, start, stop );
printf( "Time to generate: %3.lf ms\n", elapsedTime );
// 在CPU上检验计算结果是否正确
for (int i = 0; i < SIZE; ++i)
{
histo[buffer[i]]--;
}
for (int i = 0; i < 256; ++i)
{
if (histo[i] != 0)
{
printf( "Failure at %d!\n", i);
}
}
// 释放内存
cudaEventDestroy( start );
cudaEventDestroy( stop );
cudaFree( dev_histo );
cudaFree( dev_buffer );
free( buffer );
return 0;
} 全局内存原子操作
在GPU上计算直方图的代码,首先先采用全局内存的原子操作。
代码如下:
__global__ void histo_kernel( unsigned char *buffer, long size, unsigned int *histo )
{
int i = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
// 每个线程知道它的起始偏移i以及递增数量
// 遍历输入数组,递增直方图中的元素
while ( i < size )
{
// 原子操作
atomicAdd( &(histo[buffer[i]]), 1 );
i += stride;
}
}然而,发现在运行这个代码比原来CPU版本运行的还慢大概4倍。
设置基性能标准很重要。
由于在核函数里面只包含了非常少的计算工作,所以可能是全局内存上的原子操作导致性能降低。当数千个线程尝试访问少量的内存位置时,将会发生大量的竞争。为了确保递增操作的原子性,对相同内存位置的操作都将被硬件串行化。这可能导致保存未完成操作的队列非常长,会抵消通过并行运行的线程获得的性能提升。
因此考虑共享内存的操作。
共享内存原子操作
虽然原子操作是导致上面性能降低的原因,但是解决这个问题的方法确实使用更多的原子操作。因为问题出在有数千个线程在少量的内存地址上发生竞争。解决这个问题分两步。
首先,对每个并行线程块计算它所处理数据的直方图。由于每个线程块在执行这个操作时是相互独立的,所以可以在共享内存中计算这些直方图。但这种方式依然需要原子操作,因为在线程块中的多个线程之间还是会处理相同值的数据元素。但现在只有256个线程在256个地址上发生竞争,将大大减少在使用全局内存时数千个线程之间发生竞争的情况。
然后,在上个阶段中分配一个共享内存缓冲区进行初始化,用来保存每个线程块的临时直方图。
代码如下:
__global__ void histo_kernel( unsigned char *buffer, long size, unsigned int *histo )
{
__shared__ unsigned int tmp[256];
tmp[threadIdx.x] = 0;
__syncthreads();
int i = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
while ( i < size )
{
atomicAdd( &(tmp[buffer[i]]), 1 );
i += stride;
}
__syncthreads();
atomicAdd( &(histo[threadIdx.x]), tmp[threadIdx.x] );
}因为使用256个线程,且直方图中刚好包含256个元素,因此每个线程将自动把它计算得到的元素只增加到最终直方图的元素上。如果线程数量不等于元素数量,那么这个阶段将更为复杂。
总结
在一些情况中,比如成千上万个线程同时修改一个地址的元素,在这些情况中,大规模并行机器反而会带来负担。而硬件中支持的原子操作可以帮助减轻这种痛苦。
然而,在上面例子中可以看到,有时候依赖原子操作会带来性能问题,并且这些问题只能通过对算法的某些部分重构来解决。在上面例子中用了一种两阶段的算法,降低了在全集内存访问上竞争的程度。
通常,这种降低内存竞争程度的策略总能带来不错的效果。因此如果遇到在程序中使用原子操作的时候,要记住这种策略。
散列表的实现
散列表
散列表实际上就是一个hash table,但我目前没搞懂hash table和inverted list的关系,感觉是同一个东西。
散列表是一种保存 键-值 二元组的数据结构。散列表根据与值相应的键,把值放入 桶(bucket) 中。这种将键值映射到值的方法叫做散列函数。好的散列函数可以把键均匀地分布到所有桶中。这种情况下,有可能发生哈希冲突,哈希冲突的解决方法是表头键后面跟上一个链表,来保存被散列函数映射到同一个键值的桶中。
CPU实现
散列表主要包含两个部分:一个散列函数,一个表示桶的数据结构。
桶的实现用分配一个长度为N的数组来表示,数组中每个元素都表示一个 键-值 的二元组链表。
以下为这个数据结构:
struct Entry
{
// 键
unsigned int key;
// 值,任意数据类型
void* value;
// 冲突时指向下一结点的指针
Entry* next;
}
struct Table
{
// 哈希表的长度
size_t cnt;
// 哈希表,第一维指针连接表头,第二维指针指向entry
Entry **entries;
// 每添加一个Entry结点时需要重新分配新的内存,对程序性能产生影响
// 用pool来维持一个可用Entry节点的数组,避免这种情况
Entry *pool;
// 指向下一个可用的Entry节点
// 需要将一个结点添加到哈希表中时,只需使用firstFree指向的Entry
Entry *firstFree;
}初始化代码:
void initialize(Table &table, int entries, int elements)
{
table.cnt = entries;
// calloc分配空间并初始化为0,malloc分配空间不初始化
table.entries = (Entry**)calloc( entries, sizeof(Entry*) );
table.pool = (Entry*)malloc( elements * sizeof(Entry) );
table.firstFree = table.pool;
}在初始化过程中,主要操作有为哈希表entries分配内存,为结点的池分配内存,将指针firstFree初始化为指向结点池中的第一个结点。
程序结束之后,需要释放内存:
void free_table(Table &table)
{
free( table.entries );
free( table.pool );
}直接使用键值作为索引,也就是说,将结点e保存在table.entries[e.key]中。因此散列表函数如下,下面这个函数并不能保证生成数据的均匀的,这里假设生成的键是随机并且均匀的。
size_t hash(unsigned int key, size_t cnt)
{
return key % cnt;
}接下来是插入操作:
1. 首先将键放入散列表函数中计算出新的结点所属于的桶。
2. 从结点池中取出一个预先分配的Entry结点,赋值。
3. 将这个结点插入到得到的桶的首部。
代码如下:
void add_to_table(Table &table, unsigned int key, void* value)
{
// 计算要插入的新结点的表头
size_t hashValue = hash(key, table.cnt);
// 从结点池中取出一个预先分配Entry结点
Entry* location = table.firstFree++;
location -> key = key;
location -> value = value;
// 插入当前表的链表首部
location -> next = table.entries[hashValue];
table.entries[hashValue] = location;
}用如下代码来检验上面代码能否工作。首先遍历这张哈希表,然后查看每个结点,将结点放入散列表函数计算,确认这个结点被保存到了正确的桶中,检查完每个结点之后,验证散列表中的结点数量确实等于添加到散列表的元素数量。如果这些数值不相等,不是无意中将一个结点添加到了多个桶,就是没有正确的插入结点。
void verigy_table(const Table &table)
{
int cnt = 0;
for (size_t i = 0; i < table.cnt; ++i)
{
Entry *current = table.entries[i];
while (current != NULL)
{
cnt++;
if (hash( current->key, table.cnt) != i)
{
printf("%d hashed to %ld, but was located at %ld\n", current->key, hash(current->key, table.cnt), i);
}
current = current -> next;
}
}
if (cnt != ELEMENTS)
printf("%d elements found in hash table. Should be %ld\n", cnt, ELEMENTS);
else
printf("All %d elements found in hash table.\n", cnt);
}
#define HASH_ENTRIES 1024
int main()
{
unsigned int *buffer = (unsigned int*)big_random_block( SIZE );
clock_t start, stop;
start = clock();
Table table;
initialize( table, HASH_ENTRIES, ELEMENTS );
for (int i = 0; i < ELEMENTS; i++)
{
add_to_table( table, buffer[i], (void*)NULL);
}
stop = clock();
double elaspsedTime = (stop - start) / CLOCKS_PER_SEC * 1000.0;
printf("Time to hash: %3.lf ms\n", elaspsedTime);
verigy_table(table);
free_table(table);
free(buffer);
return 0;
}GPU多线程下的散列表
当两个线程,同时对同一个表头插入结点的时候,就会出现两个指针同时指向原表头的情况。因此,每次只有一个线程可以安全地对表头进行插入结点。如果每个表头都有一个相应的原子锁,那么我们可以确保每次只有一个线程对指定的桶进行修改。
首先,我们先需要一个原子锁结构,其定义如下:
struct Lock
{
int *mutex;
Lock( void )
{
cudaMalloc( (void**)&mutex, sizeof(int) );
cudaMemset( mutex, 0, sizeof(int) );
}
~Lock( void )
{
cudaFree( mutex );
}
__device__ void lock( void )
{
while( atomicCAS( mutex, 0, 1 ) != 0 );
}
__device__ void unlock( void )
{
atomicExch( mutex, 0 );
}
};其他数据结构的定义相同,只需要把散列表函数的声明改为 _ _ device _ _ , _ _ host _ _,当这两个关键字一起使用时,会告诉NVIDIA编译器,同时生成函数在设备上和主机上的版本。设备版本将在设备上运行,并且只能从设备代码中调用。同样,主机版本的函数将在主机上运行,并且只能从主机代码中调用。
struct Entry
{
// 键
unsigned int key;
// 值,任意数据类型
void* value;
// 冲突时指向下一结点的指针
Entry* next;
};
struct Table
{
// 哈希表的长度
size_t cnt;
// 哈希表,第一维指针连接表头,第二维指针指向entry
Entry **entries;
// 每添加一个Entry结点时需要重新分配新的内存,对程序性能产生影响
// 用pool来维持一个可用Entry节点的数组,避免这种情况
Entry *pool;
// 指向下一个可用的Entry节点
// 需要将一个结点添加到哈希表中时,只需使用firstFree指向的Entry
Entry *firstFree;
};
__device__ __host__ size_t hash(unsigned int key, size_t cnt)
{
return key % cnt;
}初始化和释放内存的函数大多与CPU版本中相同,但使用的是CUDA开辟内存的函数:
void initialize(Table &table, int cnt, int elements)
{
table.cnt = cnt;
cudaMalloc( (void**)&table.entries, cnt * sizeof(Entry*) );
cudaMemset( table.entries, 0, cnt * sizeof(Entry*) );
cudaMalloc( (void**)&table.pool, elements * sizeof(Entry) );
}
void free_table(Table &table)
{
cudaFree( table.entries );
cudaFree( table.pool );
}检查散列表的函数,可以编写一个在GPU上运行的函数,也可以使用原来CPU上的检查函数。第二种方法比较好,可以函数复用,节约开发时间。
这里的verify_table()函数与CPU中的完全相同。由于选择了重用CPU版本的函数,因此需要把散列表从GPU内存复制到主机内存。这个函数将包括三个步骤。首先为散列表数据分配主机内存,通过cudaMemcpy()函数将GPU上的数据复制到这块内存里,这部分代码并不困难。
复杂的地方在于,有一部分的数据是指针。不能简单地将这些指针复制到主机上,因为这些指针指向的地址存在与GPU上,他们在主机上并不是有效的指针。但这些指针的相对偏移还是有效的,每个指向Entry结点的GPU指针都指向数据table.pool[]中的某个位置,但是为了在主机上使用散列表,需要他们指向数组hostTable.pool[]中相同的Entry。因此给定一个GPU指针X,需要给目前的CPU指针加上偏移:
hostTable.pool + (X - table.pool)对每个被复制的Entry指针,都要执行这个更新操作:包括hostTable.entries中的Entry指针,以及散列表的结点池中每个Entry的next指针。
void copy_table_to_host(const Table &table, Table &hostTable)
{
// 创建CPU的空间,并将GPU上的数据复制到CPU上
hostTable.cnt = table.cnt;
hostTable.entries = (Entry**)calloc( table.cnt, sizeof(Entry*) );
hostTable.pool = (Entry*)malloc( ELEMENTS * sizeof(Entry) );
cudaMemcpy( hostTable.entries, table.entries, table.cnt * sizeof(Entry*), cudaMemcpyDeviceToHost );
cudaMemcpy( hostTable.pool, table.pool, ELEMENTS * sizeof(Entry), cudaMemcpyDeviceToHost );
// 原来复制到CPU上的指针,所指向的地址仍旧是GPU上的地址,但其偏移是不变的
// 因此,计算复制到CPU上的GPU指针的偏移,用来重新定位在GPU当前这个内存上的元素
// 重新定位在GPU上元素的表头
for (int i = 0; i < table.cnt; ++i)
{
if (hostTable.entries[i] != NULL)
{
// hostTable.entries[i]在GPU中指向table.pool[X],减去GPU中的位置首元素table.pool,得到偏移
// 用GPU地址的hostTable.pool + 偏移,就得到GPU上的指针指向的元素了
hostTable.entries[i] =(Entry*)( (size_t)hostTable.pool + ((size_t)hostTable.entries[i] - (size_t)table.pool) );
}
}
// 重新定位每个元素的next指针
for (int i = 0; i < ELEMENTS; ++i)
{
if (hostTable.pool[i].next != NULL)
{
// 与上面类似
hostTable.pool[i].next = (Entry*)( (size_t)hostTable.pool + ((size_t)hostTable.pool[i].next - (size_t)table.pool) );
}
}
}接下来就是CUDA C原子锁语句的使用了。核函数add_to_table()的参数包括一个键的数组,一个值的数组,一个散列表和原子锁数组。原子锁数组用于锁定散列表中的每个桶。
由于输入的数据是两个数组,并且在线程中需要对这两个数组进行索引,因此还需要将索引线性化。
之后遍历输入数组。对于数据key[]中的每个键,线程将通过散列表函数计算出这个 键-值 二元组属于哪个桶。计算出目标桶之后,线程会锁定这个桶,添加它的 键-值 二元组,然后解锁这个桶:
__global__ void add_to_table(unsigned int *keys, void **values, Table table, Lock *lock)
{
// 计算当前所在线程索引
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
//遍历输入数组
while (tid < ELEMENTS)
{
unsigned int key = keys[tid];
size_t hashValue = hash( key, table.cnt );
for (int i = 0; i < 32; i++)
{
if ( (tid % 32) == i )
{
Entry* location = &(table.pool[tid]);
location->key = key;
location->value = values[tid];
// 原子锁,锁定哈希表头的内存,这块内存只能当前线程操作
lock[hashValue].lock();
location->next = table.entries[hashValue];
table.entries[hashValue] = location;
// 解锁原子锁
lock[hashValue].unlock();
}
}
tid += stride;
}
}然而这段代码中有一个非常特别的地方,for()循环和后面的if()语句似乎没必要。在之前有引入线程束的概念,线程束是一个包含32个线程的集合,并且这些线程以不掉已知的方式执行。这本书中并没有讨论如何在GPU上实现这种步调一致的执行方式,但每次在线程束中只有一个线程可以获得这个锁,如果让线程束中所有的32个线程都同时竞争这个锁,将会发生严重的问题。在这种情况下,最好的方式是在软件中执行一部分的工作,遍历线程束中的线程,并给每个线程依此机会来获取数据结构的锁,执行工作,然后解锁。
main函数与CPU版本大致相同。首先分配一大块随机数据作为散列表的键。然后用CUDA事件来计时。接下来为随机数组分配GPU内存,将数组幅值到GPU上,并初始化散列表。
之后的步骤就是为散列表的桶准备好原子锁,为散列表中每一个桶都分配一个锁。
总的代码如下:
#include
#define SIZE (100*1024*1024)
#define ELEMENTS (SIZE / sizeof(unsigned int))
struct Lock
{
int *mutex;
Lock( void )
{
cudaMalloc( (void**)&mutex, sizeof(int) );
cudaMemset( mutex, 0, sizeof(int) );
}
~Lock( void )
{
cudaFree( mutex );
}
__device__ void lock( void )
{
while( atomicCAS( mutex, 0, 1 ) != 0 );
}
__device__ void unlock( void )
{
atomicExch( mutex, 0 );
}
};
// 生成随机数据
void* big_random_block( int size )
{
unsigned char *data = (unsigned char*)malloc( size );
for (int i=0; ireturn data;
}
struct Entry
{
// 键
unsigned int key;
// 值,任意数据类型
void* value;
// 冲突时指向下一结点的指针
Entry* next;
};
struct Table
{
// 哈希表的长度
size_t cnt;
// 哈希表,第一维指针连接表头,第二维指针指向entry
Entry **entries;
// 每添加一个Entry结点时需要重新分配新的内存,对程序性能产生影响
// 用pool来维持一个可用Entry节点的数组,避免这种情况
Entry *pool;
// 指向下一个可用的Entry节点
// 需要将一个结点添加到哈希表中时,只需使用firstFree指向的Entry
Entry *firstFree;
};
void initialize(Table &table, int cnt, int elements)
{
table.cnt = cnt;
cudaMalloc( (void**)&table.entries, cnt * sizeof(Entry*) );
cudaMemset( table.entries, 0, cnt * sizeof(Entry*) );
cudaMalloc( (void**)&table.pool, elements * sizeof(Entry) );
}
void free_table(Table &table)
{
cudaFree( table.entries );
cudaFree( table.pool );
}
__device__ __host__ size_t hash(unsigned int key, size_t cnt)
{
return key % cnt;
}
void copy_table_to_host(const Table &table, Table &hostTable)
{
// 创建CPU的空间,并将GPU上的数据复制到CPU上
hostTable.cnt = table.cnt;
hostTable.entries = (Entry**)calloc( table.cnt, sizeof(Entry*) );
hostTable.pool = (Entry*)malloc( ELEMENTS * sizeof(Entry) );
cudaMemcpy( hostTable.entries, table.entries, table.cnt * sizeof(Entry*), cudaMemcpyDeviceToHost );
cudaMemcpy( hostTable.pool, table.pool, ELEMENTS * sizeof(Entry), cudaMemcpyDeviceToHost );
// 原来复制到CPU上的指针,所指向的地址仍旧是GPU上的地址,但其偏移是不变的
// 因此,计算复制到CPU上的GPU指针的偏移,用来重新定位在GPU当前这个内存上的元素
// 重新定位在GPU上元素的表头
for (int i = 0; i < table.cnt; ++i)
{
if (hostTable.entries[i] != NULL)
{
// hostTable.entries[i]在GPU中指向table.pool[X],减去GPU中的位置首元素table.pool,得到偏移
// 用GPU地址的hostTable.pool + 偏移,就得到GPU上的指针指向的元素了
hostTable.entries[i] =(Entry*)( (size_t)hostTable.pool + ((size_t)hostTable.entries[i] - (size_t)table.pool) );
}
}
// 重新定位每个元素的next指针
for (int i = 0; i < ELEMENTS; ++i)
{
if (hostTable.pool[i].next != NULL)
{
// 与上面类似
hostTable.pool[i].next = (Entry*)( (size_t)hostTable.pool + ((size_t)hostTable.pool[i].next - (size_t)table.pool) );
}
}
}
void verify_table(const Table &dev_table)
{
int cnt = 0;
Table table;
copy_table_to_host(dev_table, table);
for (size_t i = 0; i < table.cnt; ++i)
{
Entry *current = table.entries[i];
while (current != NULL)
{
cnt++;
if (hash( current->key, table.cnt) != i)
{
printf("%d hashed to %ld, but was located at %ld\n", current->key, hash(current->key, table.cnt), i);
}
current = current -> next;
}
}
if (cnt != ELEMENTS)
printf("%d elements found in hash table. Should be %ld\n", cnt, ELEMENTS);
else
printf("All %d elements found in hash table.\n", cnt);
}
/// CPU version
//void add_to_table(Table &table, unsigned int key, void* value)
//{
// // 计算要插入的新结点的表头
// size_t hashValue = hash(key, table.cnt);
//
// // 从结点池中取出一个预先分配Entry结点
// Entry* location = table.firstFree++;
// location -> key = key;
// location -> value = value;
//
// // 插入当前表的链表首部
// location -> next = table.entries[hashValue];
// table.entries[hashValue] = location;
//}
/// GPU version
__global__ void add_to_table(unsigned int *keys, void **values, Table table, Lock *lock)
{
// 计算当前所在线程索引
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
//遍历输入数组
while (tid < ELEMENTS)
{
unsigned int key = keys[tid];
size_t hashValue = hash( key, table.cnt );
for (int i = 0; i < 32; i++)
{
if ( (tid % 32) == i )
{
Entry* location = &(table.pool[tid]);
location->key = key;
location->value = values[tid];
// 原子锁,锁定哈希表头的内存,这块内存只能当前线程操作
lock[hashValue].lock();
location->next = table.entries[hashValue];
table.entries[hashValue] = location;
// 解锁原子锁
lock[hashValue].unlock();
}
}
tid += stride;
}
}
#define HASH_ENTRIES 1024
int main()
{
unsigned int *buffer = (unsigned int*)big_random_block( SIZE );
cudaEvent_t start, stop;
cudaEventCreate( &start );
cudaEventCreate( &stop );
cudaEventRecord( start, 0 );
unsigned int *dev_keys;
void **dev_values;
cudaMalloc( (void**)&dev_keys, SIZE );
cudaMalloc( (void**)&dev_values, SIZE );
cudaMemcpy( dev_keys, buffer, SIZE, cudaMemcpyHostToDevice );
// 分配锁
Table table;
initialize( table, HASH_ENTRIES, ELEMENTS );
Lock lock[HASH_ENTRIES];
Lock* dev_lock;
cudaMalloc( (void**)&dev_lock, HASH_ENTRIES * sizeof(Lock) );
cudaMemcpy( dev_lock, lock, HASH_ENTRIES * sizeof(Lock), cudaMemcpyHostToDevice );
// kernel
add_to_table<<<60, 256>>>(dev_keys, dev_values, table, dev_lock);
cudaEventRecord( stop, 0 );
cudaEventSynchronize( stop );
float elapsedTime;
cudaEventElapsedTime( &elapsedTime, start, stop );
printf("Time to hash: %3.lf ms\n", elapsedTime);
verify_table(table);
cudaEventDestroy( start );
cudaEventDestroy( stop );
free_table( table );
cudaFree( dev_lock );
cudaFree( dev_keys );
cudaFree( dev_values );
free( buffer );
return 0;
}