C++性能之战(2)--double VS float
0. 写在最前面
本文持续更新地址:https://haoqchen.site/2019/12/28/double-vs-float/
首先说明,如果只是一两次的浮点运算,无脑使用double即可。下面主要针对需要大量浮点运算的情况做分析,比较float和double的优缺点。如无特殊说明,我的环境如下:
- 系统:Ubuntu1604(64bit)
- 编译器:
g++ 5.4.0 - CPU:i7-4771
文中所有的时间计算函数使用我的另一篇博文:Linux时间相关函数总结中讲到的clock_gettime的CLOCK_THREAD_CPUTIME_ID。
为了避免计算时间的随机性,每个计算运行3次。
另外吐槽个事情,最近博客阅读量到10万了,然后想申请CSDN的博客专家,然后CSDN给出的回复是“都是基础,没有深度”:

嗯,基础不重要。
如果觉得写得还不错,可以找我其他文章来看看哦~~~可以的话帮我github点个赞呗。
你的Star是作者坚持下去的最大动力哦~~~
1. 数据类型的基本情况
从《C++ Primer Plus(第6版)》了解到,C++定义了3种浮点类型:float、double、long double,并且要求:
- float至少32位(一般为32位)
- double至少48位,且不少于float(一般为64位)
- long double至少和double一样多
关于浮点数在内存中如何存储,这里有一篇讲得非常详细的博客:浮点数在计算机内存中是如何存储的?,这里不再细述。
很明显,float相对于double的优点有:
- 占用内存少。这个做过单片机的同学应该深有体会,能用float的坚决不用double,用double一不小心程序就满了。现代电脑如果不是大数据,问题都不大。
- 位数少,硬件读取快。要从硬件读取大量数据,或者要将大量参数保存到本地硬盘的时候需要考虑。
- 精度低,运算收敛快。要算个
cos、sin、log,float只需要运算7次即可收敛,而double需要迭代8~18次。
相对的,double的优点有:
- 精度高。《C++ Primer Plus(第6版)》中举了一个例子,10.0/3.0*1.0e6,float只有3333333.25,而double能精确到3333333.333333。。。对于精度要求非常高的运算,float的误差是不能容忍的。
下面是我从普通加减乘除对比、硬盘读写对比、复杂函数三个方面做的一个实验对比,如果有兴趣也可以在你自己的电脑上做个对比。
2. 普通加减乘除对比
测试代码:
#include 使用以下指令进行编译,其中-O0让编译器不做任何优化:
g++ cpp_test.cpp -std=c++11 -o cpp_test -O0
测试结果:
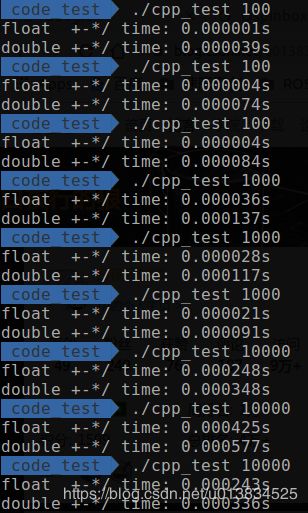
| 1百~1万 | 10万到1亿 |
|---|---|
 |
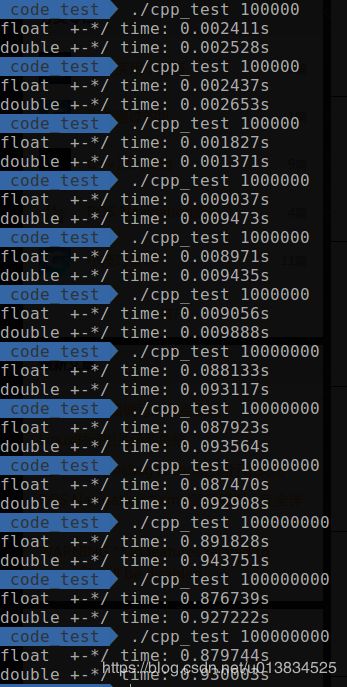 |
从1百到1亿,每个数量级都运算了3次以避免偶然因素。可以发现,在1百次到1万次之间,double类型会比float耗时要多得多,而到了10万次以上,两者的时间就相差不大了。
实验到这里,表示非常的疑惑,数量级非常小的时候,差距反而扩大了?仔细检查后发现,竟然是std::cout惹的祸,将float后面的输出注释掉,再运行,double的时间就跟float相差不大了。
总结: 对于普通的加减乘除而言,如果数据量少于10万,两者的运算效率几乎没有差距,而数据量大于10万以后,float要略微优于double7~8个百分点。
注意:
-
这里千万记得赋值给float时要在数字后面加上
f,不要写成下面这样。因为对于系统而言,默认的浮点型是double,如果你不带后面的f,只写数字,那么这个数字就是double类型的,要赋值给float需要经过一次类型转换。我将上面的代码中的f去掉后进行了一次测试,结果显示,float的耗时甚至会反超double6~7个百分点。在优化等级为O2的情况下耗时增加更加明显,float的耗时甚至超过了double20个百分点。for (; i < loop_count; ++i){ vfloat[i] += 2.3; vfloat[i] -= 3.4; vfloat[i] *= 4.5; vfloat[i] /= 5.6; } -
对于普通的加减乘除,两者的运算时间不会有太大的区别。因为目前CPU中的加法器位数远不止64位,运算一个32位和运算一个64位的数据对他们来说没有太大区别。但对于一些优化指令集就不一样了,比如SSE(仅支持单精度的浮点运算)、SSE2、SSE3等。这些指令集有专门对整形和浮点型做运算优化,尤其是一些向量运算和矩阵运算。比如SSE2使用了128位的运算单元,可以同时运算4个32位的浮点数或者2个64位的浮点数。根据g++官方文档的说法,g++是默认开启
SSE×指令集的,但上面其实并没有并行运算,所以效果并不明显。具体可对比本文第4章。
2. 硬盘读写对比
测试代码:
int main(int argc, char **argv)
{
if (argc != 2){
std::cerr << "Please run as: cpp_test 1000" << std::endl \
<< "with 1000 means loop count" << std::endl;
return -1;
}
std::size_t loop_count = stoul(std::string(argv[1]));
volatile std::size_t i = 0; // 要求编译器每次都直接读取原始内存地址,防止编译器对循环做优化
float data_float = 0.1018f;
double data_double = 0.1018;
struct timespec time_1;
struct timespec time_2;
struct timespec time_3;
struct timespec time_4;
struct timespec time_start;
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_start);
// float 循环写入硬盘
i = 0;
std::ofstream float_out;
float_out.open("./float_out.txt", std::ios::out | std::ios::trunc); // 如果存在则先删除
float_out.setf(std::ios::fixed);
float_out.precision(7);
for (; i < loop_count; ++i){
float_out << data_float;
}
float_out.close();
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_1);
// float 循环读取硬盘
i = 0;
std::ifstream float_in;
float_in.open("./float_out.txt", std::ios::in);
float_in.setf(std::ios::fixed);
float_in.precision(7);
for (; i < loop_count; ++i){
float_in >> data_float;
// std::cout << data_float << ",";
}
// std::cout << std::endl;
float_in.close();
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_2);
// double 循环写入硬盘
i = 0;
std::ofstream double_out;
double_out.open("./double_out.txt", std::ios::out | std::ios::trunc); // 如果存在则先删除
double_out.setf(std::ios::fixed);
double_out.precision(14);
for (; i < loop_count; ++i){
double_out << data_double;
}
double_out.close();
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_3);
// double 循环读取硬盘
i = 0;
std::ifstream double_in;
double_in.open("./double_out.txt", std::ios::in);
double_in.setf(std::ios::fixed);
double_in.precision(14);
for (; i < loop_count; ++i){
double_in >> data_double;
// std::cout << data_double << ",";
}
// std::cout << std::endl;
double_in.close();
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_4);
std::cout << "float write time: " << time2String(time_start, time_1) << "s" << std::endl;
std::cout << "double write time: " << time2String(time_2, time_3) << "s" << std::endl;
std::cout << "float read time: " << time2String(time_1, time_2) << "s" << std::endl;
std::cout << "double read time: " << time2String(time_3, time_4) << "s" << std::endl;
}
测试结果:
测试的是否发现,先读写float还是读写double对时间的影响非常大,尤其是次数比较少时,第一个读写的类型消耗的时间会增加很多。为了公平起见,分别将float和double都放到了前面进行测试。如下图所示,其中左边的是double放在前面的测试时间,右边的是float放在前面的测试时间。
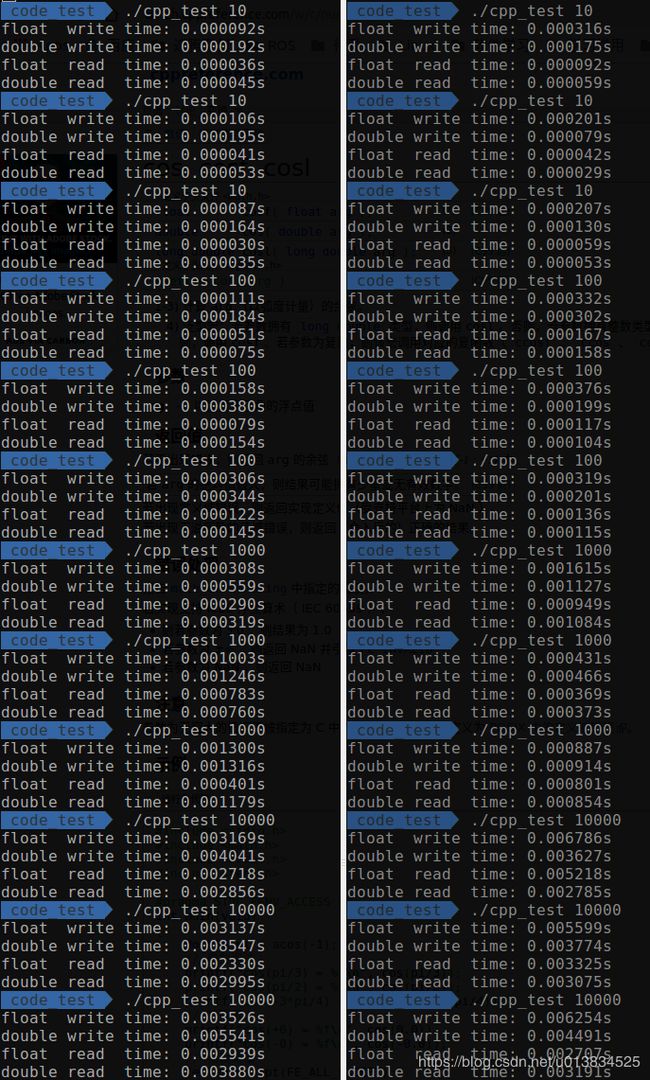
| 10~1万 | 10万到1亿 |
|---|---|
 |
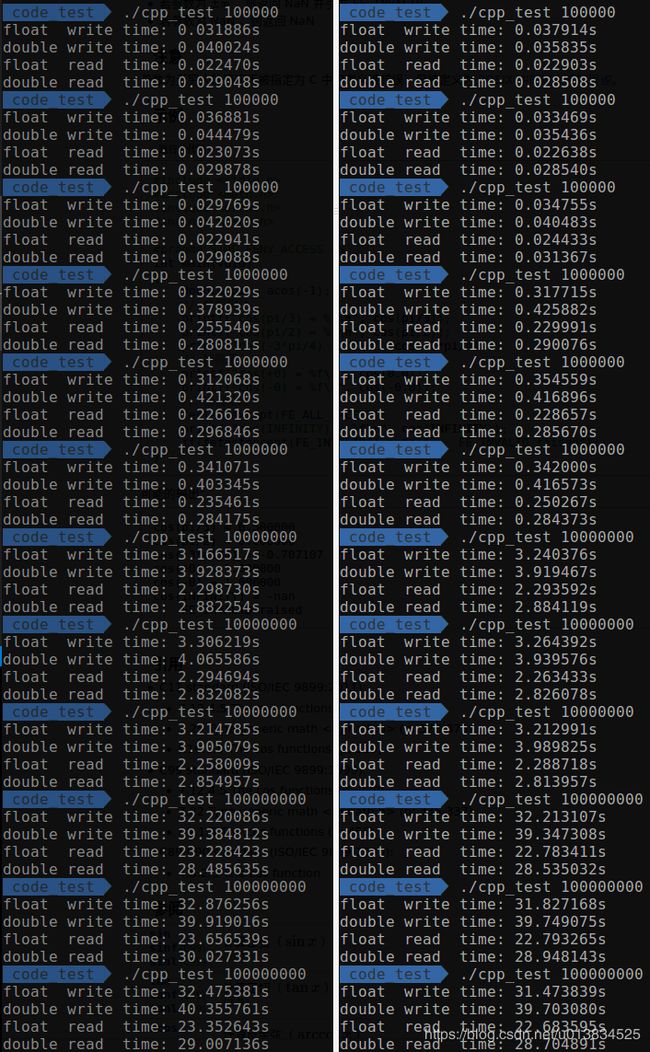 |
总结:
- 首先对于10~1万的数据,初步猜测哪个放前面,哪个消耗的时间就比较多的原因是,程序获取硬盘的系统资源需要一定的时间,这个时间几乎都消耗在第一次获取的时间上,后面该程序会一直持有,时间不再消耗在获取上。
- 对于10~1万的数据,综合两个顺序的时间来看,double仍然要比float慢一点。
- 写入的时间大学比读取的时间慢40%。
- 对于10万~1亿的数据,无论哪种顺序,double都要比float慢,写入的速度float:double最后差不多稳定在32:39,读取速度差不多稳定在23:29。
- 当写入量达到1亿的时候,生成的文件大小对比:

3. 复杂函数
测试代码:
int main(int argc, char **argv)
{
if (argc != 2){
std::cerr << "Please run as: cpp_test 1000" << std::endl \
<< "with 1000 means loop count" << std::endl;
return -1;
}
std::size_t loop_count = stoul(std::string(argv[1]));
volatile std::size_t i = 0; // 要求编译器每次都直接读取原始内存地址,防止编译器对循环做优化
std::vector<float> vfloat(loop_count, 0.0f);
std::vector<double> vdouble(loop_count, 0.0);
for (i = 0; i < loop_count; ++i){
vfloat[i] = (float)loop_count + 0.1234567f;
vdouble[i] = (double)loop_count + 0.1234567;
}
struct timespec time_1;
struct timespec time_2;
struct timespec time_start;
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_start);
// float 循环做cos
i = 0;
for (; i < loop_count; ++i){
vfloat[i] = cosf(vfloat[i]);
vfloat[i] = sinf(vfloat[i]);
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_1);
// double 循环做cos
i = 0;
for (; i < loop_count; ++i){
vdouble[i] = cos(vdouble[i]);
vdouble[i] = sin(vdouble[i]);
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_2);
std::cout << "float cos and sin time: " << time2String(time_start, time_1) << "s" << std::endl;
std::cout << "double cos and sin time: " << time2String(time_1, time_2) << "s" << std::endl;
}
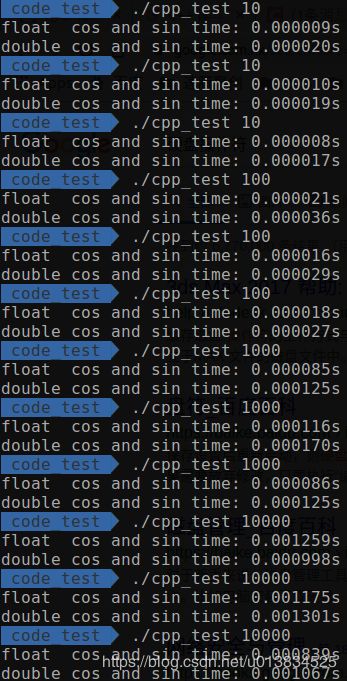
测试结果:
| 10~1万 | 10万到1亿 |
|---|---|
 |
 |
总结:
- double比float快,而且快不止一点点
- 在10万和1000万这两个点,有点迷,搞不懂,我重复测了几次,结果也是相差不多,很奇怪,暂时没有解释。换了一个固定的
cos值,在1000万时时间比变成0.26:0.38,但10万测试多次仍有很大随机性。 - 在查找
cos的头文件发现,math.h中的函数都是用了SIMD来实现的,SIMD是Single Instruction,Multiple Data的缩写——意为单指令多数据。具体细节还没时间研究,可以肯定的是,这里面利用了SSE等指令集进行了并行优化。 - 另外也测试了
log和logf的区别,两者的时间差会更加明显,最终稳定的时间比约1.6:2.5
4. Eigen矩阵运算
测试代码:
int main(int argc, char **argv)
{
if (argc != 2){
std::cerr << "Please run as: cpp_test 1000" << std::endl \
<< "with 1000 means loop count" << std::endl;
return -1;
}
std::size_t loop_count = stoul(std::string(argv[1]));
volatile std::size_t i = 0; // 要求编译器每次都直接读取原始内存地址,防止编译器对循环做优化
MatrixXf float_m1 = MatrixXf::Random(loop_count, loop_count);
MatrixXf float_m2 = MatrixXf::Random(loop_count, loop_count);
MatrixXd double_m1 = MatrixXd::Random(loop_count, loop_count);
MatrixXd double_m2 = MatrixXd::Random(loop_count, loop_count);
struct timespec time_1;
struct timespec time_2;
struct timespec time_start;
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_start);
// float 循环做加减乘除
MatrixXf float_p = float_m1 * float_m2;
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_1);
// double eigen矩阵相乘
MatrixXd double_p = double_m1 * double_m2;
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time_2);
std::cout << "float Eigen * time O0: " << time2String(time_start, time_1) << "s" << std::endl;
std::cout << "double Eigen * time O0: " << time2String(time_1, time_2) << "s" << std::endl;
}
使用以下命令进行编译:
g++ cpp_test.cpp -std=c++11 -o cpp_test -I /usr/include/eigen3 -O0
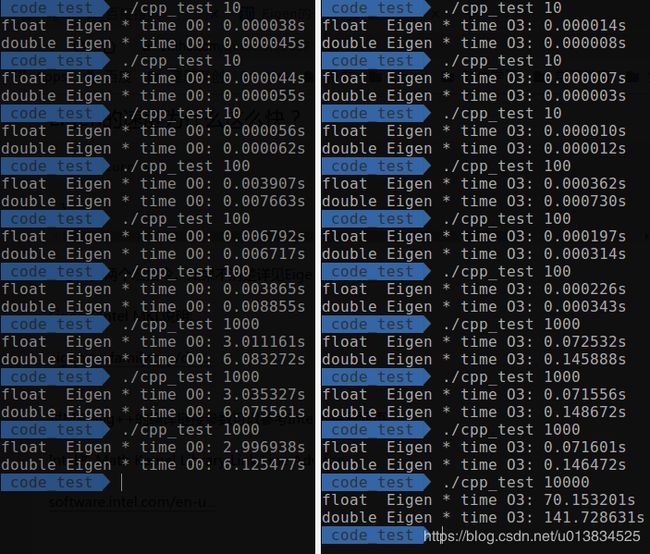
测试结果:
| 乘法 | 加法 |
|---|---|
 |
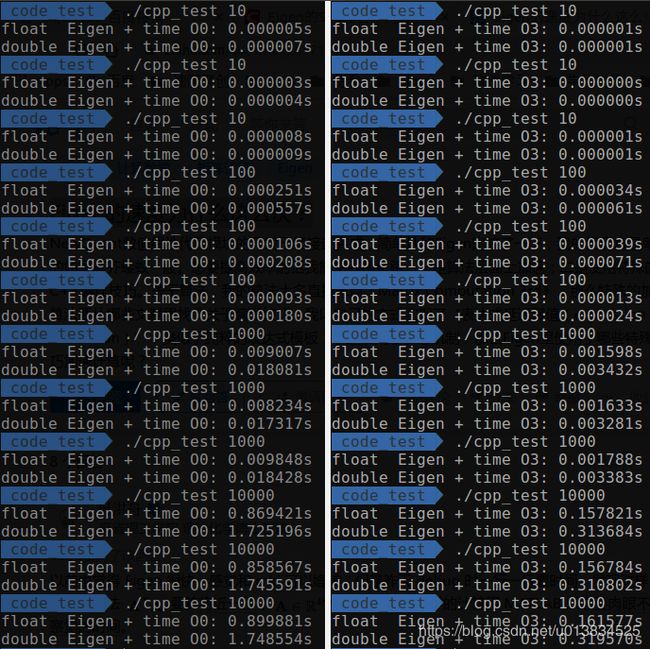 |
总结:
Eigen内部是利用SSE指令集进行优化的,当数据量非常大的时候,double所用的时间就接近于float的两倍了,这是非常明显的提升。
参考
- C++ Primer Plus(第6版)
- Eigen的速度为什么这么快?
喜欢我的文章的话Star一下呗Star
版权声明:本文为白夜行的狼原创文章,未经允许不得以任何形式转载