Flink 集群搭建(基于flink on YARN模式)
YARN调度与资源管理知识点:yarn生产详解(资源管理+调度器)
https://blog.csdn.net/shell33168/article/details/87928001 参考该博客
基于Flink on YARN的flink集群规划(flink1.9.0与Hadoop2.8.5整合)
| 主机名 |
IP |
说明 |
| centoshadoop1 |
192.168.227.140 |
StandaloneSessionClusterEntrypoint(主节点进程名称) |
| centoshadoop2 |
192.168.227.141 |
TaskManagerRunner(从节点进程名称) |
| centoshadoop3 |
192.168.227.142 |
TaskManagerRunner(从节点进程名称) |
| centoshadoop4 |
192.168.227.143 |
TaskManagerRunner(从节点进程名称) |
Vi ~/.bash_profile
export FLINK_HOME=/home/hadoop/flink/flink-1.9.0
export PATH=$PATH:$FLINK_HOME/bin
source ~/.bash_profile
创建flink在hadoop上的逻辑数据目录
hadoop fs -mkdir -p /flink/log/hadoop-flink
解压flink-1.9.0-bin-scala_2.11.tgz 到/home/hadoop/flink目录
tar -zxvf flink-1.9.0-bin-scala_2.11.tgz -C ~/flink
配置基本参数(结合机器情况调整)
cd /home/hadoop/flink/flink-1.9.0/conf
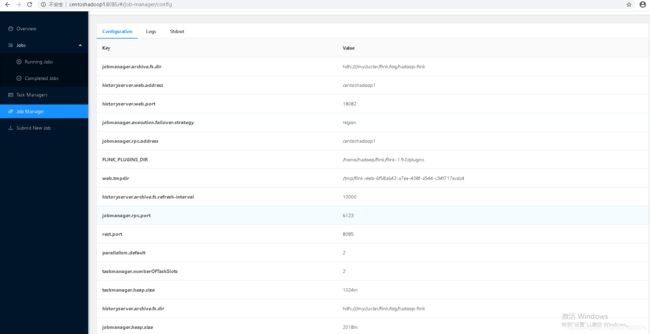
配置flink-conf.yaml,根据如下表格进行调整相应的参数
基础配置
| 参数 |
值 |
说明 |
| jobmanager.rpc.address |
centoshadoop1 |
jobmanager所在节点 |
| jobmanager.rpc.port |
6123 |
jobManager端口,默认为6123 |
| jobmanager.heap.size |
4048m |
jobmanager可用内存 |
| taskmanager.heap.size |
4096m |
每个TaskManager可用内存,根据集群情况指定 |
| taskmanager.numberOfTaskSlots |
3 |
每个taskmanager的并行度(5以内) |
| parallelism.default |
2 |
启动应用的默认并行度(该应用所使用总的CPU数) |
| rest.port |
8085 |
Flink web UI默认端口与spark的端口8081冲突,更改为8085 |
history server配置
| jobmanager.archive.fs.dir |
hdfs://mycluster/flink/log/hadoop-flink |
因为配置了hadoop的HA,所以hdfs nameservices 指定为mycluster |
| historyserver.web.address |
Centoshadoop1 |
historyserver web UI地址(需要在本地hosts文件中指定该映射关系) |
| historyserver.web.port |
18082 |
historyserver web UI端口 |
| historyserver.archive.fs.dir |
hdfs://mycluster/flink/log/hadoop-flink |
值与 jobmanager.archive.fs.dir 保持一致 |
| historyserver.archive.fs.refresh-interval |
10000 |
history server页面默认刷新时长 |
| 参数 |
值 |
说明 |
Flink配置文件——slaves
vi slaves
centoshadoop2
centoshadoop3
centoshadoop4
分发到其他节点
cd ~
scp -r flink/ hadoop@centoshadoop2:~/
scp -r flink/ hadoop@centoshadoop3:~/
scp -r flink/ hadoop@centoshadoop4:~/
cd /home/hadoop/flink/flink-1.9.0
bin/start-cluster.sh -- 启动集
执行下面的命令
[hadoop@centoshadoop1 flink-1.9.0]$
cd /home/hadoop/flink/flink-1.9.0/
bin/bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
记得监控日志: tail -f flink-hadoop-client-centoshadoop1.log
------------------------------------------------------------
The program finished with the following exception:
java.lang.RuntimeException: Could not identify hostname and port in 'yarn-cluster'.
原因:Flink1.8以后,FIX了FLINK-11266,将flink的包中对hadoop版本进行了剔除,导致flink中直接缺少hadoop的client相关类,无法解析yarn-cluster参数。
cd /home/hadoop/flink/flink-1.9.0/bin
在config.sh配置文件 中添加HADOOP_CLASSPATH
export HADOOP_HOME=/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5
export HADOOP_CLASSPATH=$HADOOP_HOME/bin/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
下载flink依赖的hadoop相关flink-shaded-hadoop-2-uber-2.8.3-10.0.jar包,添加到${FLINK_HOME}/lib下
https://repo.maven.apache.org/maven2/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
再次执行如下命令:
./bin/flink run -m yarn-cluster ./examples/batch/WordCount.jar
报错信息: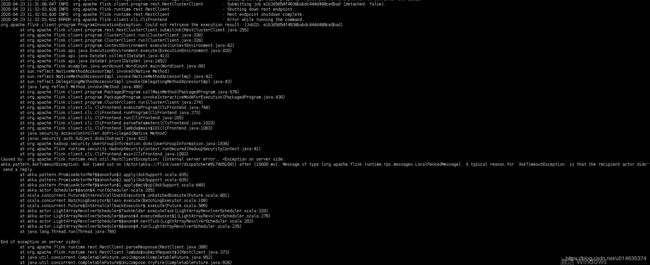
修改hadoop安装目录下的yarn-site.xml文件
分发该配置文件到hadoop的各个节点
cd ~/hadoop-ha/hadoop/hadoop-2.8.5/
scp -r yarn-site.xml hadoop@centoshadoop2:/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5/etc/hadoop
scp -r yarn-site.xml hadoop@centoshadoop3:/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5/etc/hadoop
scp -r yarn-site.xml hadoop@centoshadoop4:/home/hadoop/hadoop-ha/hadoop/hadoop-2.8.5/etc/hadoop
重启flink集群
bin/start-cluster.sh
再次执行如下命令:
bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
输出日志如下:
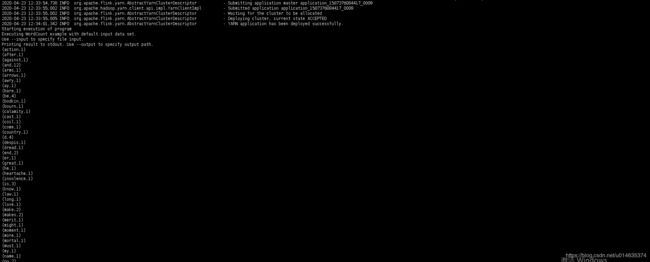
启动 historyServer
$ ./historyserver.sh start 启动历史资源
http://centoshadoop1:18082/
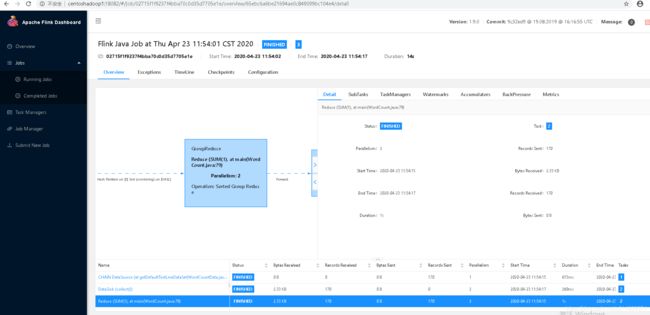
至此基于YARN的flink集群搭建完毕