学习资料:
- 《学习正则表达式》
4. 选择、分组、向后引用
分组通过对文本加一对()圆括号来帮助执行某种操作:
- 在两种或者更多的可选模式中选择一个
- 创建子模式
- 捕获一个分组以便之后进行后向引用
- 对组合的模式使用某项操作,如量词
- 使用非捕获分组
- 原子分组
- 选择操作

文本中含有the的thence,部分也会高亮
4.1 子模式
一般,提到正则表达式中的子模式subpattern,指的是分组中的一个或者多个分组。子模式就是模式中的模式
多数情况,子模式中的条件能得到匹配的的前提是前面的模式得到了匹配,但也有例外,例如:
- 子模式不依赖前面的模式:
上面的(the|The|THE),有3个子模式: the, The, THE
这种情况下,第2个子模式并不需要依赖于是否匹配第1个,尽管 最左边的模式会首先匹配
- 子模式依赖前面的模式:

整体含义:匹配到t或者T后,再匹配一个h,接下来是e或者eir
能够匹配到的4个单词: the, their, The, Their
第2个e|eir子模式,必须依赖于第1个t|T子模式
括号对于子模式不是必需的
- 字符组子模式:
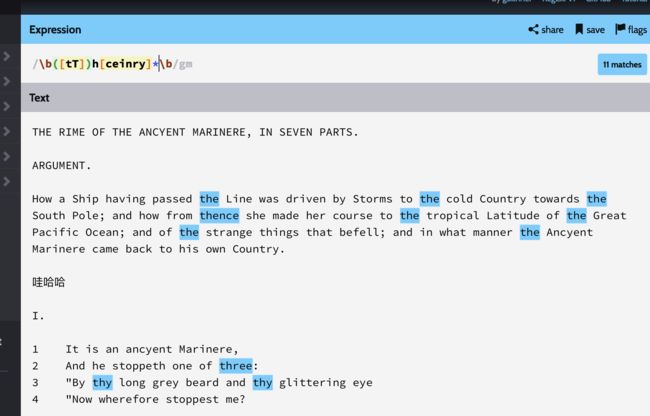
两个\b表示单词边界,表明该模式只匹配一个完整的单词,而不再是单词的一部分
-
[tT]:字符组,匹配t或者T,可以看作是第一个子模式 -
h:尝试匹配小写字母h -
[ceinry]:字符组,匹配组内的字母,*表示零个或者多个
4.3 捕获分组和后向引用
当一个模式的全部的或者部分内容由一对括号分组时,就对内容进行捕获并临时存储于内存中
注意:引用的是捕获的内容,形式为:
\1
//或者
$1
\1或者$1引用的是第1个捕获的分组,\2,$2引用的是第2个捕获的分组,依次类推
简单使用,重新排序一行:
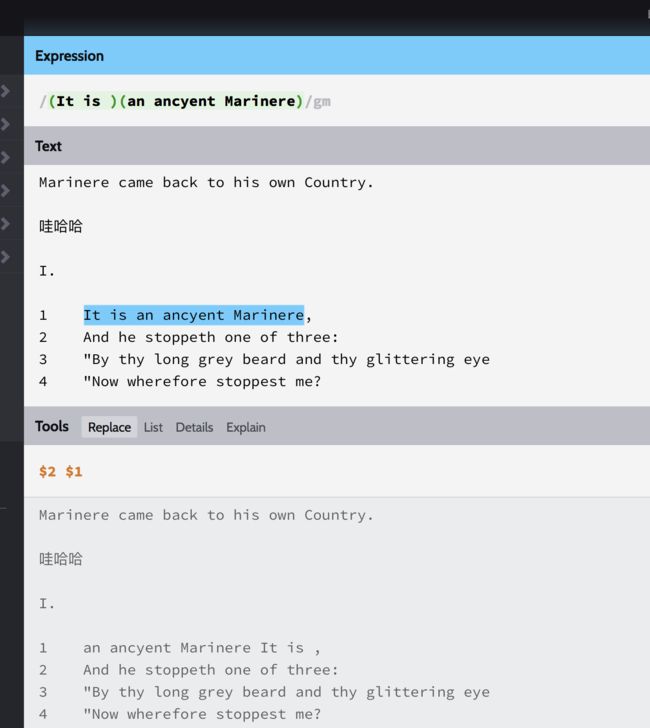
首先分别捕获目标分组,然后再Replace标签下的输入框中输入$2 $1,就可以看到高亮的文本,换了顺序
4.4 非捕获分组
非捕获分组Non-Capturing Group,不会将其内容存入内存中,由于不储存内容,能提高性能,在恰当复杂场景下,更适合使用
一开始的(the|The|THE),可以改写成非捕获分组形式:
(?:the|The|THE)
- 原子分组
原子分组atomic-group:另一种非捕获分组,可以将回溯操作关闭,只针对原子分组内的部分,而不针对整个正则表达式
正则表达式处理过程缓慢的一个因素就是回溯操作,原因在于回溯操作会尝试每一种可能性,会比较耗时和耗资源。如果一个回溯操作产生巨大的负面效应,就被称为 灾难性回溯
原子分组,回溯操作,百度了下,看了看,暂时先不考虑了,先知道有这么个玩意。。。
5. 字符组
字符组,也被称为 方括号表达式(backeted expression),有助于匹配特定的字符或者特定的字符序列
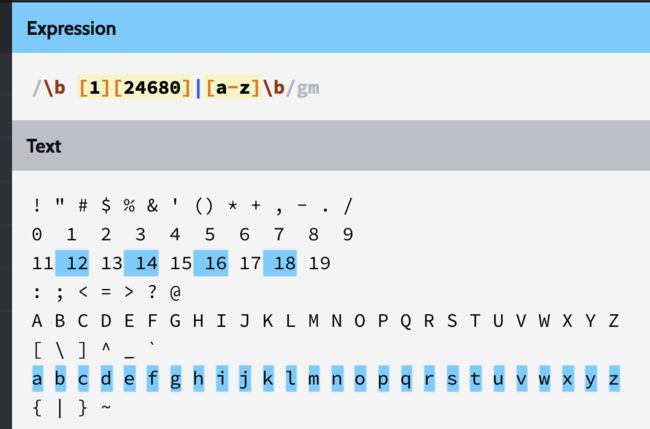
利用字符组,配11-20间的偶数,以及a到z
字符组内也可以使用简写式,例如:
- 匹配空格和单词字符
[\w\s]
//等价于
[_a-zA-Z \t\n\r]
5.1 字符组取反
- 字符组取反:
匹配与字符组内容不匹配,不符合条件的的字符
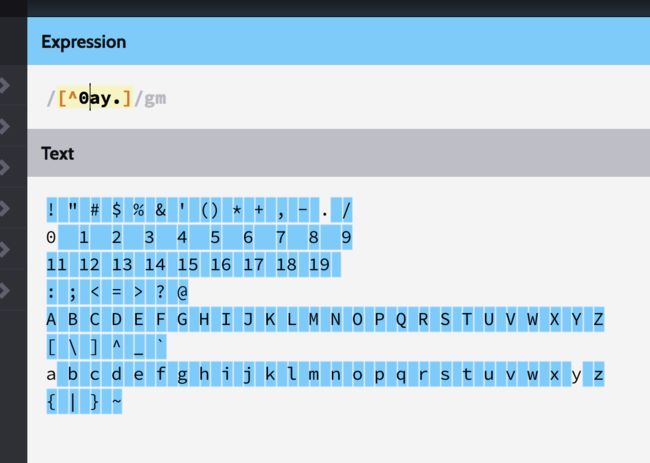
字符组内开始的脱字符^意义就是NO,我不想匹配这些字符,^必须位于字符组的最开始位置
6 匹配Unicode和其他字符
ASCII(American Standard Code for Inforation Interchange)美国信息交换标准码定义了英文字符集,A到Z大写和小字字母,以及控制字符,其他字符,一共含有128个
Unicode有10万个字符,它将ASCII码表加入了基本Basic Latin拉丁码表
- 配合章节练习的网站:Regex Pal
- 练习文本:伏尔泰先生的一段话
伏尔泰先生的话,大意:
- 什么是宽容?它是人性的产物。我们生来都有缺陷和错误,就让我们原谅彼此的蠢行吧!这才是大自然的第一法则
6.1 匹配Unicode字符
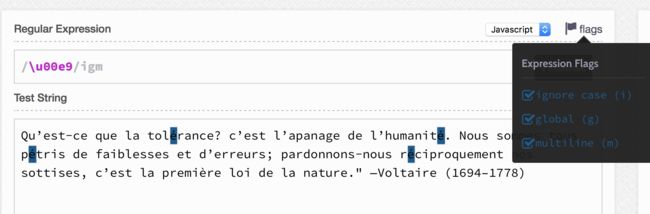
\u之后接的是十六进制的00e9,不需要区分大小写。在Unicode表中,é的代码点为U+00E9,00e9对应十进制的233,超出了ASCII码表0-127的范围
除了使用十六进制外,还可以使用八进制来匹配字符,正则表达式的格式就是\后,接三位数字
\351
//等价于
、\u00e9
7. 量词
- 配合练习的app:Reggy
7.1 贪心、懒惰和占有
指的是量词的特性
- 贪心
量词自身是贪心的。贪心的量词首先会匹配整个字符串。尝试匹配时,会尽可能多的选定内容,也就是整个输入
量词首次尝试匹配整个字符串,如果失败则回退一个字符后再次尝试,这个过程则称为回溯backtracking。每次会回退一个字符后,直到找到的匹配内容或者没有字符可以尝试为止。而整个过程都会被记录,对资源的消耗最大
整个过程就是:先吃尽把整个字符串,然后每次再吐一点,慢慢咀嚼消化
- 懒惰
懒惰是另外一种策略。从目标的起始位置开始尝试寻找匹配,每次检查字符串的一个字符,寻找要匹配的内容。最终,会尝试匹配整个字符串。要使一个量词称为懒惰的, 必需要普通的量词后添加一个?。意味着,每次只吃一点
- 占有
占有量词会覆盖整个目标然后尝试寻找匹配的内容,但只会尝试一次,并不会回溯。占有个量词就是在普通的量词前加一个+,意味着, 并不咀嚼而是直接吞咽,然后才去想吃什么
7.2 用*、+和?进行匹配
- Kleene星号
这一命名是为了纪念正则表达式的发明人Stephen Kleene
.*:将会以贪心的方式匹配,匹配任意字符零次或者多次。
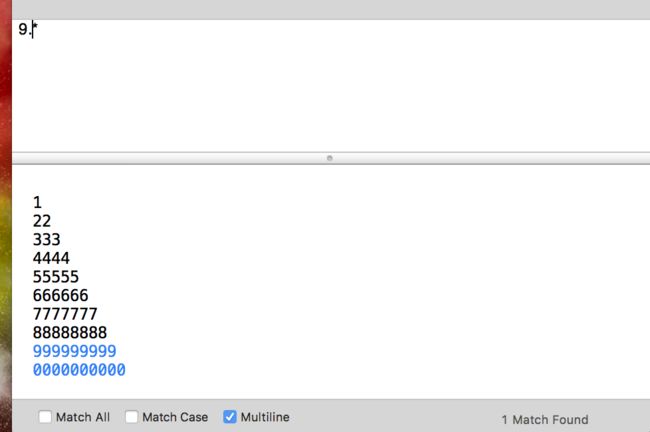
在Multiline模式下,9以及0两行都会标亮,在这个模式下,.号会匹配换行符,而一般情况下,.号并不会匹配换行符
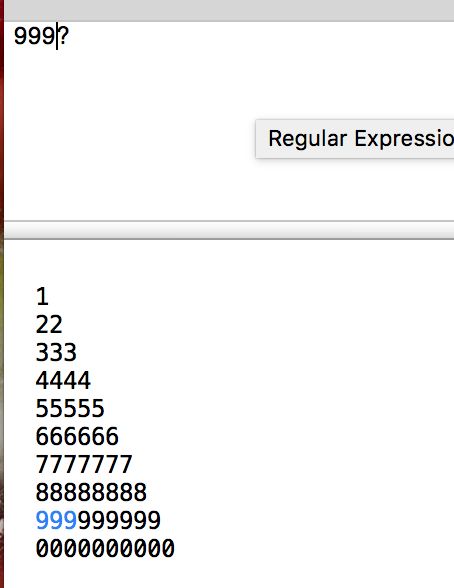
*,+,?默认都是贪心的量词,第一次都会尽可能多地匹配字符
| 语法 | 描述 |
|---|---|
* |
零个或者多个 |
+ |
一个或者多个 |
? |
零个或者一个 |
7.3 匹配特定次数
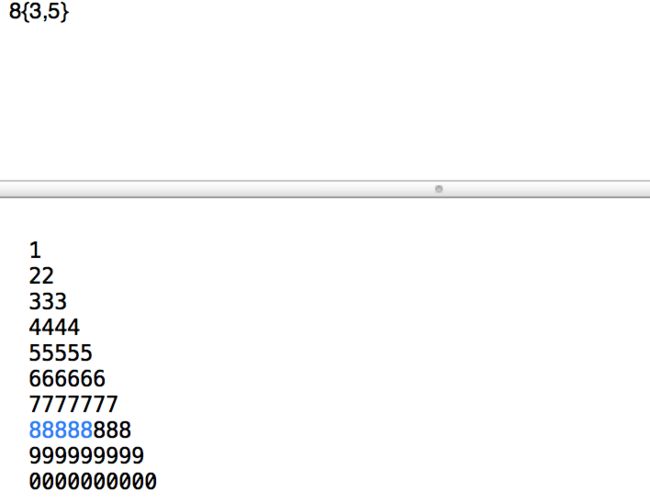
-
6{1}:匹配一个6 -
7{1,}:匹配多个7 -
8{3,5}:匹配888,8888,88888
7{1,} ---> 等价于: 7+
7* ---> 等价于: 7{0,}
7? ---> 等价于: 7{0,1}
| 语法 | 描述 |
|---|---|
{n} |
精确匹配n次 |
n, |
匹配n次或者更多次 |
m,n |
匹配m次至n次 |
0,1 |
零次或1次,与?相同 |
1,0 |
1次或更多,与+相同 |
0, |
零次或多次,与*相同 |
7.4 懒惰量词

只匹配了两个5,而不像贪心型量词那样,匹配5个数字5
| 语法 | 描述 |
|---|---|
?? |
懒惰匹配零次或一次,可选 |
+? |
懒惰匹配一次或者多次 |
*? |
懒惰匹配零次或多次 |
{n}? |
懒惰匹配n次 |
{n,}? |
懒惰匹配n次或多次 |
{m,n}? |
懒惰匹配m至n次 |
如果想要匹配最少而非最多数目的字符,可以使用懒惰量词
7.5 占有式匹配
占有式匹配很像贪心式匹配,会选定尽可能多的内容,但与贪心式不同的是,不会进行回溯,所以速度也就最快。占有式量词并不会放弃找到的内容,匹配到内容后就会占有,这也是为啥称为占有式的原因
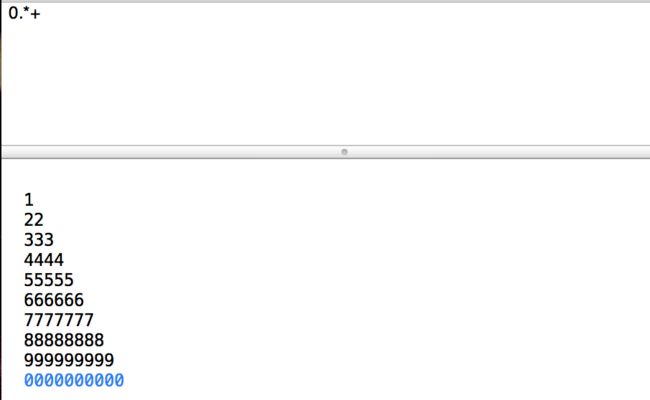
当将表达式修改为.*+0时,却没有匹配到任何字符,最后一行0并没有被高亮
原因就是没有回溯,首先一下子选定了所有了输入,不再回过来查看。它会一下子挥霍了自己的财产,一下子没在结尾找到0,也不知道再从哪里开始找起
当知道文本内容时,知道在哪里可以找到匹配,应该考虑使用占有式量词
| 语法 | 描述 |
|---|---|
?+ |
占有式匹配零次或者一次,可选 |
++ |
占有式匹配一次或多次 |
*+ |
占有式匹配零次或多次 |
{n}+ |
占有式匹配n次 |
{n,}+ |
占有式匹配n次或更多次 |
{m,n}+ |
占有式匹配m至n次 |
8. 简单实例
-
匹配北美电话号码
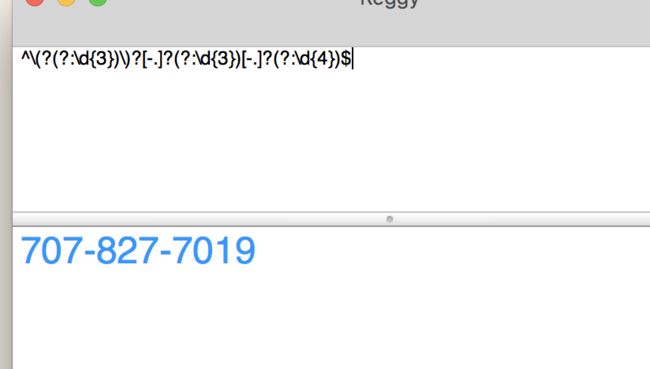 匹配电话号码
匹配电话号码
^\(?(?:\d{3})\)?[-.]?(?:\d{3})[-.]?(?:\d{4})$:
-
^:判定一行开始或者主题词开始开头的零宽度断言 -
\(?:判定(,可选 -
?:\d{3}:匹配连续三位数字的非捕获分组 -
\)?:判定),可选 -
[-.]?:允许有可选的连字符-或者. -
?:\d{3}:匹配连续三位数字的非捕获分组 -
[-.]?:允许有可选的连字符-或者. -
?:\d{4}:匹配连续四位数字的非捕获分组 -
$:匹配一行或者主题词的结尾
自己想到的一个改进,可能不合理:^\(?((?:\d{3})\)?[-.]?){2}?(?:\d{4})$
- 匹配邮箱
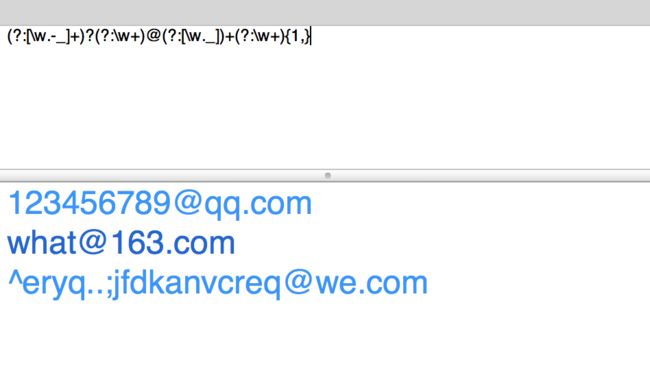
表达式 (?:[\w.-_]+)?(?:\w+)@(?:[\w._])+(?:\w+){1,}从Regexr Community 中的Email Address得到,网站给的是JavaScript下适用的,自己尝试做了一点点修改,瞎改的,不要试图拿来直接在自己的代码中用。。。
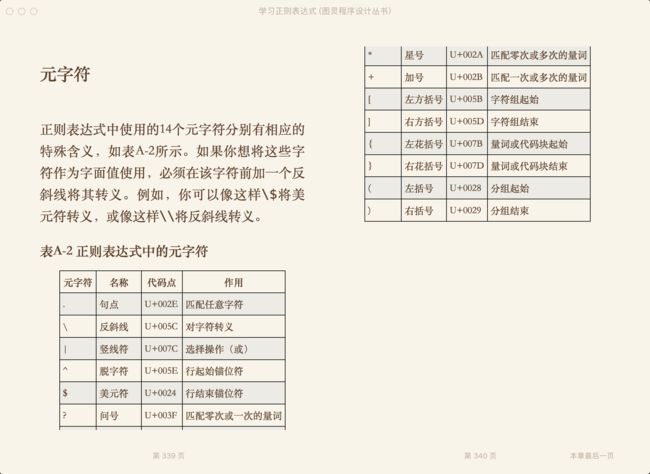
偷个懒,直接截图
9. 最后
书看是看完了,然而感觉啥都没记住,需要多多练习。书后面3章看了看,没做啥记录
本人很菜,有错误,请指出
共勉 :)