翻译:https://www.cloudera.com/documentation/enterprise/latest/topics/cdh_hag_rm_ha_config.html#xd_583c10bfdbd326ba--43d5fd93-1410993f8c2--7f77
YARN(MRv2)ResourceManager高可用性
YARN ResourceManager负责跟踪集群中的资源并调度应用程序(例如,MapReduce作业)。在CDH 5之前,ResourceManager是YARN群集中的单点故障。ResourceManager高可用性(HA)以主备ResourceManager对的形式添加冗余来消除此单点故障。此外,从活动的ResourceManager故障切换到备用时,应用程序可以从保存的state store 恢复; 例如,如果在MapReduce作业中的映射任务完成后发生了ResourceManager的故障转移,则映射任务不会再次运行。这样可以处理以下事件,而不会对正在运行的应用程序产生任何显着的性能影响:
- 未计划的事件,例如机器崩溃
- 计划维护事件,例如运行ResourceManager的机器上的软件或硬件升级
ResourceManager HA需要运行ZooKeeper和HDFS服务。
继续阅读:
- Architecture架构
- 使用Cloudera Manager配置YARN(MRv2)ResourceManager高可用性
- 使用命令行配置YARN(MRv2)ResourceManager高可用性
- 使用YARN的rmadmin管理ResourceManager HA
Architecture架构
ResourceManager HA通过ResourceManager 的主备对来实现。在启动时,每个ResourceManager都处于standy状态; 进程已启动,但状态为未加载。当其中一个资源管理器转换为活动状态时,ResourceManager从指定的state store 加载内部状态并启动所有内部服务。转换活动状态可以由管理员(通过CLI)或自动故障转移触发。以下小节提供了有关ResourceManager HA组件的更多详细信息。
ResourceManager重新启动
如果启用恢复功能,重新启动ResourceManager允许恢复正在运行的应用程序。为此,ResourceManager将其内部状态(主要是应用程序相关的数据和令牌)存储到ResourceManagerStateStore; 当NodeManager连接时重新构建群集资源。可以替代的state store 是MemoryResourceManagerStateStore (基于内存的实现), FileSystemResourceManagerStateStore (基于文件系统的实现; HDFS可用于文件系统)和 ZKResourceManagerStateStore (基于ZooKeeper的实现)。
Fencing隔离
当运行两个资源管理器时,在两个资源管理器都假定它们处于活动状态时会出现裂脑情况。为了避免这种情况,只有一个ResourceManager应该能够执行主动操作,而另一个ResourceManager应该被“隔离”。基于ZooKeeper的状态存储ZKResourceManagerStateStore 只允许单个ResourceManager对存储状态进行更改,并隐式隔离其他ResourceManager。这是通过ResourceManager声明对根znode的独占创建 - 删除权限来完成的。root znode 上的ACL是基于ACLs配置自动创建的; 对于安全集群,Cloudera建议您为根主机设置ACL,以便两个ResourceManagers共享读写管理员访问权限,但具有独占的创建 - 删除访问权限。防护是隐含的,不需要显式配置(如HDFS和MRv1中的fencing需要显示配置)。 可以根据需要插入自定义的“Fencer”- 例如,使用不同的状态存储实现。
配置和故障转移代理
在HA设置中,应该配置两个ResourceManager以使用不同的端口(例如,不同主机上的端口)。为了促进这一点,YARN使用ResourceManager标识符的概念(rm-id)。每个ResourceManager都有一个唯一的rm-id,以及所有RPC配置(
自动故障转移
默认情况下,ResourceManager HA使用ZKFC(基于ZooKeeper的故障转移控制器)进行自动故障转移。在内部, StandbyElector 用于选择活动的ResourceManager。故障切换控制器作为ResourceManager的一部分运行(不像HDFS和MapReduce v1中的单独进程),并且在yarn-site.xml中配置适当的属性后不需要进一步设置。
如果您愿意,可以插入自定义故障转移控制器。
手动转换和故障转移
您可以使用命令行工具 yarn rmadmin 将特定的ResourceManager转换为活动或备用状态,从一个ResourceManager故障切换到另一个,获取ResourceManager的HA状态以及监控ResourceManager的健康状况。
使用Cloudera Manager配置YARN(MRv2)ResourceManager高可用性
最低要求的角色: 群集管理员(也由完全管理员提供)
您可以使用Cloudera Manager为CDH 5或更高版本配置ResourceManager高可用性(HA)。Cloudera Manager支持ResourceManager的自动故障转移。它不提供通过Cloudera Manager用户界面手动强制进行故障转移的机制。
重要提示:启用或禁用HA将导致先前的监控历史记录不可用。
启用高可用性
- 转到YARN服务。
- 选择Actions > Enable High Availability 。显示有资格运行备用ResourceManager的主机的屏幕。当前ResourceManager运行的主机不可用作为选择。
- 选择要安装备用ResourceManager的主机,然后单击继续。Cloudera Manager继续运行一组停止YARN服务的命令,添加备用ResourceManager,在ZooKeeper中初始化ResourceManager高可用性状态,重新启动YARN并重新部署相关的客户端配置。
- 在Cloudera Manager中启用ResourceManager HA时,默认情况下会为ResourceManager启用保留工作恢复。有关更多信息(包括禁用保留恢复工作的说明),请参阅工作保留YARN组件的恢复。
注意: ResourceManager HA不会影响JobHistory服务器(JHS)。JHS不保持任何状态,所以如果主机出现故障,您可以简单地将其分配给新的主机。您也可以通过执行以下操作来启用流程自动重新启动:
- 转到YARN服务。
- 单击配置选项卡。
- 选择范围 > JobHistory服务器。
- 选择类别 > 高级。
- 找到自动重新启动进程属性或通过在搜索框中键入它的名称来搜索它。
- 点击修改个人值
- 选择JobHistory服务器默认组。
- 重新启动JobHistory服务器角色。
禁用高可用性
- 转到YARN服务。
- 选择操作 > 禁用高可用性。显示运行ResourceManagers的主机的屏幕。
- 选择您希望保留哪个ResourceManager(主机)作为单个ResourceManager,然后单击继续。Cloudera Manager运行一组停止YARN服务的命令,删除备用ResourceManager和故障切换控制器,重新启动YARN服务并重新部署客户端配置。
使用命令行配置YARN(MRv2)ResourceManager高可用性
要配置并启动ResourceManager HA,请按以下步骤操作。
- 停止YARN守护进程
- 配置手动故障转移和可选的自动故障转移
- 重新启动YARN守护进程
停止YARN守护进程
停止运行所有主机上的MapReduce JobHistory服务,ResourceManager服务和NodeManager,如下所示:
$ sudo service hadoop-mapreduce-historyserver stop
$ sudo service hadoop-yarn-resourcemanager stop
$ sudo service hadoop-yarn-nodemanager stop
配置手动故障转移和可选的自动故障转移
配置故障转移:注意:
如图所示,在yarn-site.xml中配置以下属性,无论您是配置手动还是自动故障转移。它们足以配置手动故障转移。您需要为自动故障转移配置其他属性。
| 名称 | 使用 | 默认值 | 推荐值 | 描述 |
|---|---|---|---|---|
| yarn.resourcemanager.ha.enabled | ResourceManager, NodeManager, Client | false | true | 启用HA |
| yarn.resourcemanager.ha.rm-ids | ResourceManager, NodeManager, Client | (None) | Cluster-specific, for example: rm1,rm2 | Comma-separated list of ResourceManager ids in this cluster. |
| yarn.resourcemanager.ha.id | ResourceManager | (None) | ResourceManager-specific, for example: rm1 | Id of the current ResourceManager. Must be set explicitly on each ResourceManager to the appropriate value. |
| yarn.resourcemanager.address. |
ResourceManager, Client | (None) | Cluster-specific | The value of yarn.resourcemanager. address (Client-ResourceManager RPC) for this ResourceManager. Must be set for all ResourceManagers. |
| yarn.resourcemanager.scheduler.address. |
ResourceManager, Client | (None) | Cluster-specific | The value of yarn.resourcemanager. scheduler.address (AM-ResourceManager RPC) for this ResourceManager. Must beset for all ResourceManagers. |
| yarn.resourcemanager.admin.address. |
ResourceManager, Client/Admin | (None) | Cluster-specific | The value of yarn.resourcemanager. admin.address (ResourceManager administration) for this ResourceManager. Must be set for all ResourceManagers. |
| yarn.resourcemanager.resource-tracker.address. |
ResourceManager, NodeManager | (None) | Cluster-specific | The value of yarn.resourcemanager. resource-tracker.address (NM-ResourceManager RPC) for this ResourceManager. Must be set for all ResourceManagers. |
| yarn.resourcemanager.webapp.address. |
ResourceManager, Client | (None) | Cluster-specific | The value of yarn.resourcemanager. webapp.address (ResourceManager webapp) for this ResourceManager.Must be set for all ResourceManagers. |
| yarn.resourcemanager.recovery.enabled | ResourceManager | false | true | Enable job recovery on ResourceManager restart or failover. |
| yarn.resourcemanager.store.class | ResourceManager | org.apache.hadoop. yarn.server. resourcemanager. recovery. FileSystemResourceManagerStateStore | org.apache. hadoop.yarn. server. resourcemanager. recovery. ZKResourceManagerStateStore | The ResourceManagerStateStore implementation to use to store the ResourceManager's internal state. The ZooKeeper- based store supports fencing implicitly. That it, it allows a single ResourceManager to make multiple changes at a time, and hence is recommended. |
| yarn.resourcemanager. zk-address | ResourceManager | (None) | Cluster- specific | The ZooKeeper quorum to use to store the ResourceManager's internal state. |
| yarn.resourcemanager. zk-acl | ResourceManager | world:anyone:rwcda | Cluster- specific | The ACLs the ResourceManager uses for the znode structure to store the internal state. |
| yarn.resourcemanager.zk- state-store.root-node.acl | ResourceManager | (None) | Cluster- specific | The ACLs used for the root host of the ZooKeeper state store. The ACLs set here should allow both ResourceManagers to read, write, and administer, with exclusive access to create and delete. If nothing is specified, the root host ACLs are automatically generated on the basis of the ACLs specified through yarn.resourcemanager.zk-acl. But that leaves a security hole in a secure setup. |
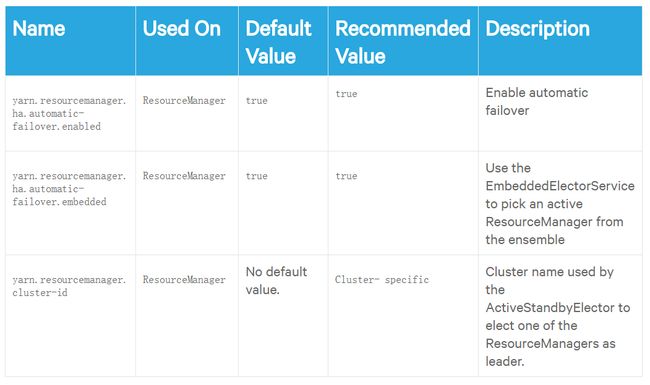
配置自动故障转移:
在yarn-site.xml中配置以下其他属性以配置自动故障转移。
配置工作保持恢复:
或者,您可以为资源管理器和节点管理器配置工作保留恢复。请参阅工作保留YARN组件的恢复。
以下是一个示例yarn-site.xml,显示配置的这些属性,包括保留ResourceManager和NM的恢复工作:
yarn.resourcemanager.connect.retry-interval.ms
2000
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.ha.automatic-failover.enabled
true
yarn.resourcemanager.ha.automatic-failover.embedded
true
yarn.resourcemanager.cluster-id
pseudo-yarn-rm-cluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.ha.id
rm1
yarn.resourcemanager.scheduler.class
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
yarn.resourcemanager.recovery.enabled
true
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKResourceManagerStateStore
yarn.resourcemanager.zk-address
localhost:2181
yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms
5000
yarn.resourcemanager.work-preserving-recovery.enabled
true
yarn.resourcemanager.address.rm1
host1:23140
yarn.resourcemanager.scheduler.address.rm1
host1:23130
yarn.resourcemanager.webapp.https.address.rm1
host1:23189
yarn.resourcemanager.webapp.address.rm1
host1:23188
yarn.resourcemanager.resource-tracker.address.rm1
host1:23125
yarn.resourcemanager.admin.address.rm1
host1:23141
yarn.resourcemanager.address.rm2
host2:23140
yarn.resourcemanager.scheduler.address.rm2
host2:23130
yarn.resourcemanager.webapp.https.address.rm2
host2:23189
yarn.resourcemanager.webapp.address.rm2
host2:23188
yarn.resourcemanager.resource-tracker.address.rm2
host2:23125
yarn.resourcemanager.admin.address.rm2
host2:23141
Address where the localizer IPC is.
yarn.nodemanager.localizer.address
0.0.0.0:23344
NM Webapp address.
yarn.nodemanager.webapp.address
0.0.0.0:23999
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.local-dirs
/tmp/pseudo-dist/yarn/local
yarn.nodemanager.log-dirs
/tmp/pseudo-dist/yarn/log
mapreduce.shuffle.port
23080
yarn.resourcemanager.work-preserving-recovery.enabled
true
重新启动YARN守护进程
在所有之前运行的主机上启动MapReduce JobHistory服务器,ResourceManager和NodeManager,如下所示:
$ sudo service hadoop-mapreduce-historyserver start
$ sudo service hadoop-yarn-resourcemanager start
$ sudo service hadoop-yarn-nodemanager start
使用yarn rmadmin 管理ResourceManager HA
您可以使用 yarn rmadmin 在命令行上管理您的ResourceManager HA。yarn rmadmin 具有以下与ResourceManager HA相关的选项:
[-transitionToActive serviceId]
[-transitionToStandby serviceId]
[-getServiceState serviceId]
[-checkHealth ]
其中serviceId 就是 rm-id.。
注意:尽管 -help 显示了 -failover 选项, 但是 yarn rmadmin 并不支持 。