Python网络编程(socket模块、缓冲区、http协议)
网络的概念:主机 端口 IP 协议
- 服务器:
- localhost/127.0.0.1
- 客户端:
- 只是在本机启动客户端,用127.0.0.1访问
- 服务器:
- 0.0.0.0
- 客户端:
- 可以在本机用127.0.0.1、192.168.0.1
- 服务器:
- 192.168.0.1
- 客户端:
- 局域网内用192.168.0.1
socket(创建套接字) --->
bind(绑定地址) --->
listen(设置监听)--->
accept(等待链接) --->
recv/send(收/发消息) --->
close ()
收发函数特性:
recv特征:
- 如果建立的另一端链接被断开, 则recv立即返回空字符串
- recv是从接受缓冲区取出内容,当缓冲区为空则阻塞
- recv如果一次接受不完缓冲区的内容,下次执行会自动接受
send特征:
- 如果发送的另一端不存在则会产生Pipe Broken异常
- send是从发送缓冲区发送内容,当缓冲区为满则堵塞
网络的收发缓存区:
在内存中开辟区域,用于
发送和接受的缓冲
作用:
- 协调数据的收发(接受和处理)速度
- 减少和磁盘的交互
sendall(date):
功能:
tcp套接字发送消息
参数:同
send
返回值:如果
发送成功则
返回None
否则返回异常
tcp粘包:
产生原因:
1.
tcp传输以
字节流的方式
发送消息,
消息之间没有边界
2.发送比
接受的速度快
影响:
对每次发送的内容是一个独立的意识需要单独识别时 容易使用原文件被更改
如何处理:
1.每次发送后
追加一个结尾标志,代表本次发送完毕
2.
发送一个
数据结构
3.
每次发送有一个
时间间隔
基于udp的服务端编程:
1.创建套接字:
sockfd = socket(AF_INET,SOCK_DGRAM)
2.绑定地址:
sockfd.bind()
3.消息收发
data, addr = sockfd.
recvfrom(buffersize)
功能:接受udp消息
参数:接受消息的大小
返回值:
data 接受到的内容
addr 消息发送的地址
recvfrom每次接受一个报文,
如果没有接受到的内容则直接丢弃
sockfd.
sendto(data, addr)
功能:udp消息发送
参数:
data 要发送的内容 bytes
addr 目标地址
返回:发送字节数
4.关闭套接字:
socket.close()
import
sys
sys.argv
作用:
获取从命令行获取的参数内容
Python3 demo.py 参数1, 参数2.....
sys.argv[0] 是命令本身(程序本身)
tcp流式套接字和udp数据报套接字区别:
- 1.流式套接字采用字节流的方式进行传输,
- 而数据报套接字使用数据报形式传输数据
- 2.tcp套接字会产生粘包,udp不会
- 3.tcp编程可以保证消息的完整性,udp则不一定
- 4.tcp需要listen、accept、udp不用
- 5.tcp消息的发送接收使用recv、send、sendall、
- udp使用recvfrom,sendto
socket模块和
套接字属性(s为套接字)
- s.type:表示套接字类型
- s.family:地址类型
套接字属性方法
s.fileno()
功能:
获取套接字的
文件描述符
文件描述符:
每一个IO事件 操作系统都会分配一个不同的的正整数,
该正整数即为此IO操作的文件描述符
默认开启的描述符:
- sys.stdin 0
- sys.stdout 1
- sys.stderr 2
s.getsockname()
功能:
获取套结字绑定
的地址
s.
getpeername()
功能:
获取链接套接字
客户端的地址
s.setsockopt(level,optname, value)
(#
设置端口可立即重用 必须在链接端口前设置
s.setsockopt(SOL_SOcKET, SO_REUSEADDR))
功能:设置套接字选项
参数:
level:设置
选项的类型(大类型) 常用:SOL_SOCKET
optname:
子类选项
value:
要设置的值
s.getsockopt(level
, optname)
功能:
获取套接字选项值
参数:
level:选项的类型
udp套接字应用--->
广播
一点发送多点接收
目标地址:广播地址 172.18.32
.255
tcp应用---> http传输
http协议:
超文本传输协议
用途:
网站中浏览器
网页的获取,基于
网站事物
数据传输
编写基于http协议的
数据传输
特点:
1.
应用层协议,传输层使用tcp服务
2.
简单、灵活,可以使用
多种编程语言操作
3.无状态的协议,既不用记录用户的输入内容
4.
http1.1 ---> http2.0(还没发布)
技术的成熟和稳定性
http请求(request):
请求格式:
1.请求行:说明具体的
请求类别和内容
GET /index.html /HTTP/1.1
请求类别 请求内容 协议版本
请求类别:
-
-
- GET: 获取网络资源
- POST: 提交一定的附加数据
- HEAD: 获取响应头
- PUT: 更新服务器资源
- DELETE: 删除服务器资源
- CONNECT: 未使用
- TRACE: 用于测试
- OPTIONS: 获取服务器性能信息
-
2.请求头:对
请求的具体描述
Accept:text/html
每一个键值对占一行,描述了一个特定信息
3.空行
4.请求体: 具体的
参数或提交的
内容
get参数或者post提交的内容
http响应(response):
响应格式:
1.响应行:
反馈具体的
响应情况
HTTP/1.1 20 OK
版本协议 响应码 附加信息
响应码:
-
- 1xx:提示信息,表示请求已经接收
- 2xx:响应成功
- 3xx:响应需要定向(重新记载链接第三方链接)
- 4xx:客户端错误
- 5xx:服务器端错误
- 1xx:提示信息,表示请求已经接收
常见响应码:
200 成功
404 请求
内容不存在
401 没有访问
权限
500 服务器
未知错误
503
服务器暂时
无法执行
2.响应头:对响应
内容的具体描述
3.空行
4.响应体:
将客户端请求内容进行返回
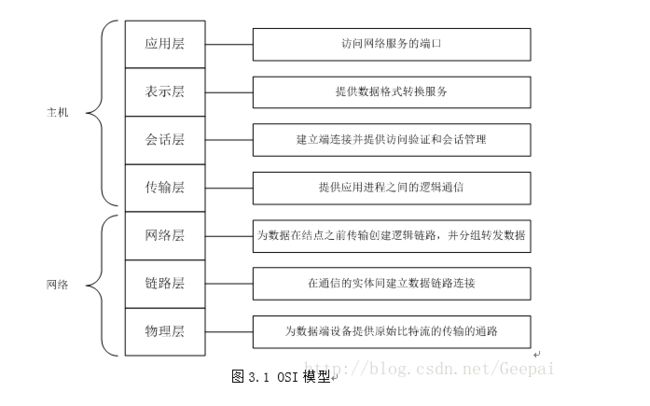
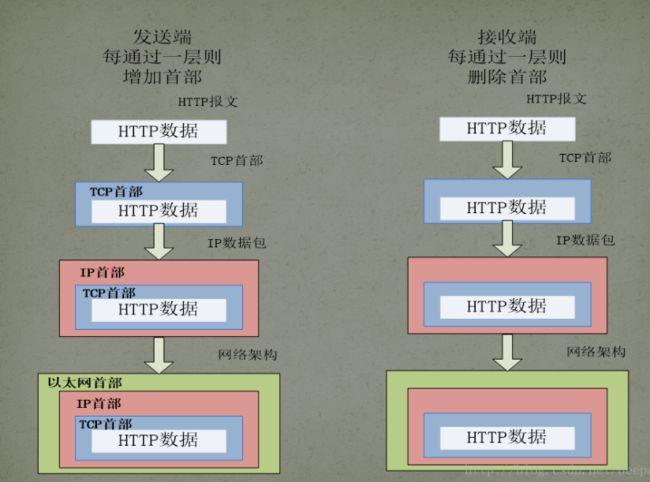
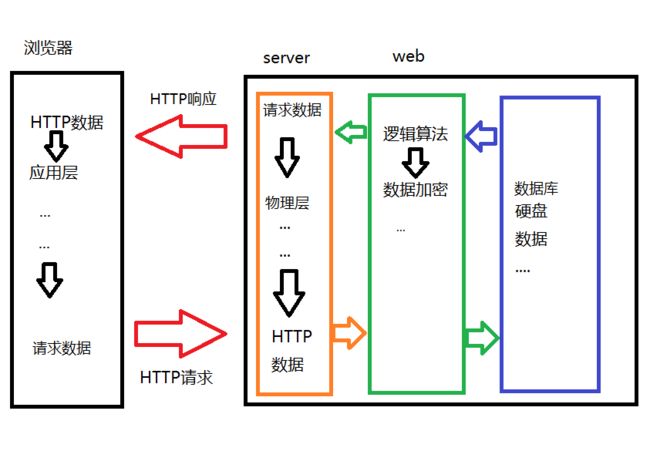
这里这个图就看了一眼 没特意去记 凭印象画的 可能不对 但是大体逻辑应该没错
我去百度搜了 什么也没搜到 不知道是不是我的打开方式不对还是什么
只搜到了上面的两张图..........
总结:
tcp,udp协议的区别和编程实现上的差异:
tcp:
- tcp是一种可靠的、面向有链接数据传输服务
- tcp能够保证数据的完整性、顺序性、无重复以及无差错
- tcp是一种以文件流的形式传输数据的服务 文件流之间是没有边界
- 的所以基友可能会产生粘包的情况 粘包是因为接受速度没有传输速度快
- 导致缓存区的数据拥堵 下次取出数据时从而产生非独立数据的链接 这种情况
- 叫做粘包 粘包只有传输多个数据时才会出现
- tcp的编程需要监听套接字 和 等待链接过程 只有链接成功才能发送数据
- 这种情况叫做三次握手、还有断开时的四次挥手
- 三次挥手:客户端请求链接、服务器返回报文、客户端完成链接
- 四次挥手:客户端请求断开、服务器接受请求、服务器准备完毕可以断开、客户端断开
- tcp收发送消息需要使用recv、send、sendall方法
- sendall比特殊 功能和send一样 但sendall有事务 若发送成功返回None 否则触发异常
- 链接时必须先运行服务器端后运行客户端
udp:
- udp就比较简单了 是面向无连接的不可靠的数据传输服务
- udp没有数据流 接受大小取决于接收方
- 若数据超出接收方接受范围则丢掉所有超出范围的内容
- udp不存在粘包的情况
- udp不需要等待链接 没有挥手过程 先发就发 想收就收 自由度比较高
- udp编程时收发消息使用recvfrom、sendto方法
- udp可用于广播可以随时断开或链接
- 客户端和服务器端可以随时运行
什么是http?
http 是超文本传输协议
一种网络数据传输的协议
没错就是 协议
并且所有的www文件都必须遵守这个标准
http作用是什么?
可以用力来网站中浏览器网页获取,基于网站上的一些数据传输 例如目前我正在打的字......
编写基于http协议的数据传输
http协议 请求和响应的格式以及每一部分做什么
请求部分:
请求行:请求的具体类别和内容 比如说 类别、内容、版本协议
请求头:请求具体描述
空行:就是空行
请求体:请求具体参数或内容
响应部分:
响应行:具体响应情况 比如说 版本协议 、响应码 、附加信息
响应头:响应具体描述
空行
响应体:响应具体参数或内容
http协议中请求的基本类型和作用:
GET:获取网络资源
POST:提交一定的附加数据
HEAD:获取响应头 响应返回的文件信息
PUT:更新服务器资源
DELETE:删除服务器资源
TRACE:用于测试
OPIONS:获取服务器性能信息
CONNECT:备用
http协议响应码的类型和表达含义:
以1开头的表示请求已经链接
以2开头的表示成功接收、提示
以3开头的代表重新定向进一步处理 第三方
以4开头的客户端错误
以5开头的服务器错误
http协议请求网页的流程:
建立连接、发送请求、响应请求、断开链接
这样的一个过程称为一个事物