摘要: 这是机器学习研究人员和从业人员所学到的12个关键经验教训的总结,包括避免陷阱,重点问题以及常见问题的答案。
7:特征工程是关键
有些机器学习项目成功了,有些失败了,到底什么在其中起到关键作用?最容易使用的特征是最重要的因素。如果你有许多独立的特征,每个特征都与类相关联,学习是很容易。另一方面,如果这个类是一个非常复杂的特征,你可能无法学习它。通常情况下,原始数据不是可以学习的形式,但是可以从中构建特征。这通常是机器学习项目中的大部分工作所在,它通常也是最有趣的部分之一,其中直觉、创造力和“黑色艺术”与技术材料一样重要。
初学者常常惊讶于机器学习项目实际进行机器学习的时间太少。但是,如果考虑收集数据,整合数据,清理数据并对数据进行预处理以及进行特征设计的尝试和错误可能会花费多少时间,你会发现这些才是真正费时间的。此外,机器学习不是建立数据集和运行模型的一步式过程,而是运行模型、分析结果、修改数据或模型并重复的迭代过程。训练通常是最快速的部分,但那是因为我们已经掌握了很好的技巧!特征工程是最困难的,因为它是特定领域的,而训练是通用标准执行的。但是,两者之间没有明显的边界。

8:更多数据击败更聪明的算法
在大多数计算机科学中,这两种主要的有限资源是时间和记忆。在机器学习中,还有第三个:训练数据。在20世纪80年代,数据是稀缺的。今天往往是时间是宝贵的。大量的数据是可用的,但没有足够的时间来处理它,所以它没有被使用。这导致了一个矛盾:尽管原则上更多的数据意味着可以学习更复杂的分类器,但在实践中是更简单的分类器被使用,因为复杂的分类器学习时间过长。今天所有的研究者都想找到快速训练复杂分类器的方法,而且在这方面确实取得了显着的进展。
部分原因是使用更聪明的算法。所有学习者本质上都是通过将附近的例子分组到同一个类来工作的,关键的区别在于“附近”。由于数据分布不均匀,训练可以产生广泛不同的边界,同时在重要的区域仍然做出相同的预测(具有大量训练实例的那些预测),大多数文本示例可能会出现。
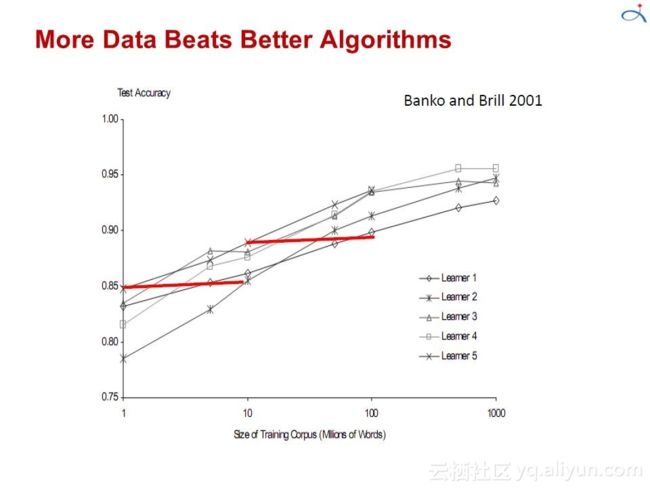
通常,首先尝试最简单的训练(例如,逻辑回归之前的朴素贝叶斯,支持向量机之前的k-最近邻居)。更复杂的训练是诱人的,但他们通常更难以使用,因为他们有更多的参数需要调整以获得更好的结果,并且他们的内部更不透明。
模型可以分为两种主要类型:表示具有固定大小的线性分类器,以及表示可随数据增长的线性分类器,如决策树。固定大小的分类器只能利用这么多的数据。原则上可变大小的分类器可以在给定足够数据的情况下学习任何函数,但实际上,由于算法或计算成本的限制,它们可能不会。而且,由于维度的诅咒,没有现有的数据量可能就足够了。出于这些原因,那些充分利用数据和计算资源的算法,通常会表现得很好,只要你愿意付出努力。机器学习项目通常会有一个重要的学习者设计组成部分,从业者需要有一些专业知识。
9:模型不只是一个
在机器学习的早期,每个人都有自己喜欢的模型,以及一些先验理由相信它的优越性。大部分人努力尝试很多参数的变化,并选择了最好的一个。然后系统的经验表明,不同应用的最佳模型往往是不同,并且包含许多模型的系统开始出现。但是随后研究人员注意到,如果不是选择找到的最佳变体,我们可以结合了许多变体,结果会更好。并且对设计者而言没有额外的工作量。
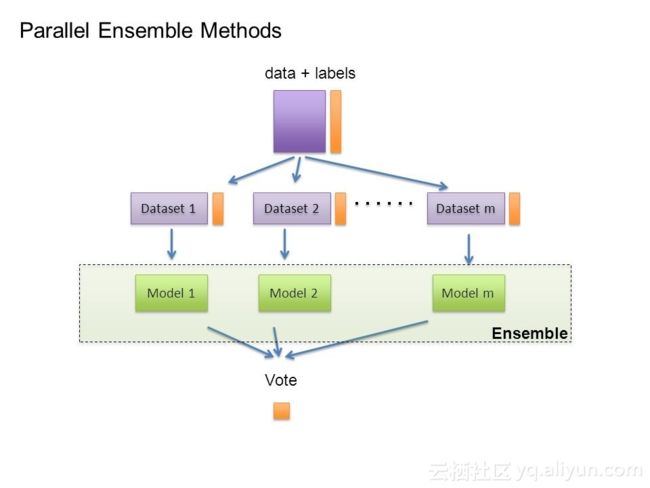
创建这样的模型集合有一个通用的名词:装箱。我们只需通过重采样生成随机变化的训练集,分别学习分类器并结合,看看他们的性能即可。这是有效的,因为它极大地减少了方差,而偏差只是稍微增加。在训练过程中,训练样例有权重,而且这些都是不同的,这样每个新的分类器都会将重点放在前面往往出错的例子上。在堆叠中,单个分类器的输出成为“更高层次”的输入,该模型计算出如何最好地组合它们。
在Netflix奖中,来自世界各地的团队竞相建立最佳视频推荐系统。随着比赛的进行,团队发现他们通过将学习者与其他团队相结合而获得最佳成绩。获胜者和亚军都是由100多名学习者组成的合并队伍,合并在一起进一步提高了模型的性能。毫无疑问,这将是未来的趋势。
10:简单并不意味着准确
奥卡姆的剃刀这个故事地指出,实体不应该超出必要的倍增。在机器学习中,这通常意味着,给定两个具有相同训练错误的分类器,其中较简单的分类器可能具有最低的测试错误。有关这一说法的证据经常出现在文献中,但事实上,它有很多反例,而“无免费午餐”定理暗示它不可能是真实的。

我们在前一部分看到一个反例:模型集合。即使在训练误差达到零之后,分类器的泛化误差也会继续提高。因此,与直觉相反,模型的参数数量与其过度拟合的倾向之间没有必然的联系。
相反,更复杂的观点将复杂性等同于假设空间的大小,因为较小的空间允许假设由较短的代码表示。如上面关于理论保证部分的界限可能会被视为暗示更短的假设。这可以通过将更短的代码分配给我们有一些先验偏好的空间中的假设来进一步细化。但将此视为准确性与简单性之间权衡的“证明”是循环推理:我们通过设计使我们喜欢的假设更简单,如果它们准确,那是因为我们的偏好是准确的,而不是因为假设“简单”代表了我们选择。
11:可描述并不意味着可以学习
本质上,所有可变规模模型的描述都具有形式的相关定理:“使用这种描述,每个函数都可以被描述或近似地描述”。然而,仅仅因为一个函数可以描述,并不意味着它可以被学习。例如,标准决策树模型不能学习含有更多叶子的树干。在连续的空间中,使用一组固定的基元描述甚至简单的函数往往需要无数的组件。

此外,如果假设空间具有许多评估函数的局部最优值(通常情况如此),则学习者可能无法找到真正的函数,即使它是可描述的。给定有限的数据、时间和记忆,标准模型只能学习所有可能函数的一小部分,而这些子集对于具有不同表述的模型是不同的。因此,关键问题不是“能否描述出来?
12:相关并不意味着因果关系
相关性并不意味着因果关系。但是,尽管我们讨论过的那种模型只能学习相关性,但他们的结果往往被视为代表因果关系。这不是错了吗?如果是这样,那么人们为什么这样做呢?

通常情况下,训练预测模型的目标是将它们用作行动指南。如果我们发现啤酒和尿布经常在超市买到,那么也许把啤酒放在尿布部分旁边会增加销售。但实际上实验很难说清楚。机器学习通常应用于观察性数据,其中预测变量不受学习者的控制。一些学习算法可能潜在地从观测数据中提取因果信息,但它们的适用性相当有限。另一方面,相关性是潜在因果关系的标志,我们可以用它作为进一步调查的指导。
结论
像任何学科一样,机器学习有很多的“民间智慧”,虽然不是100%正确,但对成功至关重要。多明戈斯教授的论文总结了一些最重要的内容。学习更多知识是他的书The Master Algorithm,这是一个非技术性的机器学习入门。他还教授在线机器学习课程,可以在这里查看。
本文由阿里云云栖社区组织翻译。
文章原标题《12-useful-things-know-about-machine-learning》,
译者:虎说八道,审校:袁虎。
详情请阅读原文