Leetcode刷题笔记(python3版)
EASY LEVEL:
169. Majority Element
Given an array of size n, find the majority element. The majority element is the element that appears more than ⌊ n/2 ⌋ times.
You may assume that the array is non-empty and the majority element always exist in the array.
Example 1:
Input: [3,2,3] Output: 3
Example 2:
Input: [2,2,1,1,1,2,2] Output: 2
思路:这可以用字典也可以直接sort以后取中间的那个数,因为大于n/2次的数一定是排序以后出现在最中间。
class Solution:
def majorityElement(self, nums: List[int]) -> int:
from collections import Counter
d = Counter(nums)
return [k for (k,e) in d.items() if e>int(len(nums)/2)][0]
class Solution:
def majorityElement(self, nums: List[int]) -> int:
return sorted(nums)[len(nums)//2]
1108. Defanging an IP Address
题目:Given a valid (IPv4) IP address, return a defanged version of that IP address. A defanged IP address replaces every period "." with "[.]".
Example 1:
Input: address = "1.1.1.1"
Output: "1[.]1[.]1[.]1"这道题其实就是把中间的'.'变成‘[.]’而已:
class Solution:
def defangIPaddr(self, address: str) -> str:
x = '[.]'.join(address.split(sep='.'))
return(x)join相当于join一个string
771. Jewels and Stones
You're given strings J representing the types of stones that are jewels, and S representing the stones you have. Each character in S is a type of stone you have. You want to know how many of the stones you have are also jewels.
The letters in J are guaranteed distinct, and all characters in J and S are letters. Letters are case sensitive, so "a" is considered a different type of stone from "A".
Example 1:
Input: J = "aA", S = "aAAbbbb"
Output: 3此道题是看J中的字母在S中出现的次数的总和:
1.在S中数一下每个出现字母的次数并分别求和; 2. 循环遍历J,把每个字母对应的加上。
class Solution:
def numJewelsInStones(self, J: str, S: str) -> int:
c = 0
for i in range(len(J)):
c = c+ sum(map(J[i].count, S))
return cmap()函数的使用。
938. Range Sum of BST
Given the root node of a binary search tree, return the sum of values of all nodes with value between L and R(inclusive).
The binary search tree is guaranteed to have unique values.
Example 1:
Input: root = [10,5,15,3,7,null,18], L = 7, R = 15
Output: 32这道题用到了递归的思想。画出这棵BST:
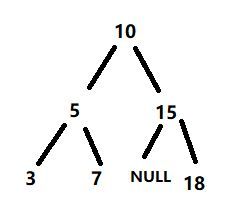
假设二叉树顶点值为V,可以分成三种情况:
1. V 2. V>R:那么顶点所有右子树都大于R,需要去左子树找到大于L并小于R的值; 3.L<=V<=R: 这样左右子树都要找,因为顶点也包括在这个范围之内。 代码: 需要了解在什么时候使用递归的思想! Implement function ToLowerCase() that has a string parameter str, and returns the same string in lowercase. Example 1: 非常简单的一道题,无需多说 A valid parentheses string is either empty A valid parentheses string Given a valid parentheses string Return Example 1: 我的想法是,对 '(' 和 ')' 进行计数,开始会有两种情况:"((" 和 "()",第一个出现的一定是"("并且一定是最后要被移除的。我们只要找到原来string里面需要移除的字符串位置就可以。设定一个count是left(计算"("的个数),一个count是right(计算")"的个数),那么从第二个字符开始计数的时候,只要left == right,说明到达了一个全部括号都回头的状态,那么这个位置就是需要被移除的位置。而所有需要被移除的位置有三种: 第一个+括号回头的位置+括号回头的下一个位置(如果没有超过字符串长度的话)。 还有用栈来实现的,也很值得借鉴: 要多多使用方便的数据结构! International Morse Code defines a standard encoding where each letter is mapped to a series of dots and dashes, as follows: For convenience, the full table for the 26 letters of the English alphabet is given below: Now, given a list of words, each word can be written as a concatenation of the Morse code of each letter. For example, "cba" can be written as "-.-..--...", (which is the concatenation "-.-." + "-..." + ".-"). We'll call such a concatenation, the transformation of a word. Return the number of different transformations among all words we have. Note: 此题如果用python的字典功能会很好解决,把每个字母map到字典里面去,得到他们的莫斯编码,最后unique一下就得到了结果。 Given a binary matrix To flip an image horizontally means that each row of the image is reversed. For example, flipping To invert an image means that each Example 1: Notes: 其实还是搞复杂了,网上有一行的代码很值得学习: Given an array You may return any answer array that satisfies this condition. Example 1: 这道题只需要先把偶数找出来然后并上奇数就可以: In a array Return the element repeated Example 1: 说实话这题一开始想的是把所有的数一遍然后找出count>2的,最后运行出来时间太慢了。。。原来的代码: 后来想,其实不需要知道一个重复的元素出现了几次,根本不需要count,只需要在出现第一个重复的时候把那个重复的元素返回回来就好了。。。 所以新建了一个新的list,每次加一个元素进去,到第i次的时候遍历原来数组从第i+1到最后一个元素,看看有没有重复的,因为题目说数组里只有一个重复的元素,所以如果找到第一个重复的数一定是唯一的那个,也不用管它后面出现了几次,直接return回来其实就可以了,这样算法复杂度就下降了不少。 看排名最高的参考答案是利用了字典。。。看来我还是不熟悉。。 字典的概念需要非常了解! There is a robot starting at position (0, 0), the origin, on a 2D plane. Given a sequence of its moves, judge if this robot ends up at (0, 0) after it completes its moves. The move sequence is represented by a string, and the character moves[i] represents its ith move. Valid moves are R (right), L (left), U (up), and D (down). If the robot returns to the origin after it finishes all of its moves, return true. Otherwise, return false. Note: The way that the robot is "facing" is irrelevant. "R" will always make the robot move to the right once, "L" will always make it move left, etc. Also, assume that the magnitude of the robot's movement is the same for each move. Example 1: 这题其实就是L的个数和R相等,U的个数和D相等,那么它就回到原点。 其实我还是写复杂了。。。看来python还不是特别熟。。 string.count()这个函数需要掌握! Given a string s consists of upper/lower-case alphabets and empty space characters If the last word does not exist, return 0. Note: A word is defined as a character sequence consists of non-space characters only. Example: Input: "Hello World" Output: 5 这题很简单,只要split by 空格然后计算最后一个元素的长度就可以了。需要注意的是最后发现"a "这种,他会把后面的空格去掉,那么last word是a,所以这种情况特殊处理一下: Given an n-ary tree, return the postorder traversal of its nodes' values. For example, given a Return its postorder traversal as: Note: Recursive solution is trivial, could you do it iteratively? 这是一题让你后序遍历树。。先左节点再右节点再根节点。。并且题目不许你用递归。 有一种方法是用栈来实现。栈是先进后出,第一步先把root节点放进栈里,然后把root的children放进栈里,再把children的children放进栈里,那么在最后出来的时候,先是孩子节点先出,再是根节点,符合后序遍历的要求。 Given an n-ary tree, return the preorder traversal of its nodes' values. For example, given a Return its preorder traversal as: Note: Recursive solution is trivial, could you do it iteratively? 和上面一题相似,只是要你先序遍历,就是先根节点再左节点再右节点 就是先visit根节点,再遍历根节点child运用同样的递归的方法。 You are given an array of strings A string is good if it can be formed by characters from Return the sum of lengths of all good strings in Example 1: 其实就是找哪些字母可以由chars里的字母组成,那就看看每个在words里的字符在chars里是不是都存在,如果是那么就加上这个字符的长度,最后就可以算出最终的长度。 A binary tree is univalued if every node in the tree has the same value. Return Example 1: 这题看一棵树是不是每个节点上的数字都一样,当然不包括null。。 写了一个helper function,也就是说,每次遍历节点,比较节点和左右孩子的值的大小,如果不一样就return false。 有两步: 1. 记录了根节点的值 2.将根节点的值,运用递归将这个值和各个节点进行比较,如果发现有一个不同就返回false,并且需要left和right中,只要一个false就返回false Determine whether an integer is a palindrome. An integer is a palindrome when it reads the same backward as forward. Example 1: Example 2: 其实只要把它变成一个list看这个list的reverse的list和他本身是否相等,不相等就return false即可。 The set Given an array Example 1: Note: 首先可以定义一个set([1:len(num)]),假如说是[1,2,3,4],那么重复的number就是nums比这个set多的,少的number就是set比这个nums多的。这样算法复杂度会低一些。(另一种方法是count,但是这样算法复杂度会高,试了一下这种方法,没有pass因为时间太长) # Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def rangeSumBST(self, root: TreeNode, L: int, R: int) -> int:
if not root:
return 0
result = 0
if root.val > R:
#root = root.right
result = result + self.rangeSumBST(root.left, L, R)
elif root.val < L:
#root = root.left
result = result + self.rangeSumBST(root.right, L, R)
elif L <= root.val <= R:
result = result + root.val
result = result + self.rangeSumBST(root.left, L, R)
result = result+ self.rangeSumBST(root.right, L, R)
return result709. To Lower Case
Input: "Hello"
Output: "hello"class Solution:
def toLowerCase(self, str: str) -> str:
st = str.lower()
return st
1021. Remove Outermost Parentheses
(""), "(" + A + ")", or A + B, where A and B are valid parentheses strings, and + represents string concatenation. For example, "", "()", "(())()", and "(()(()))" are all valid parentheses strings.S is primitive if it is nonempty, and there does not exist a way to split it into S = A+B, with A and B nonempty valid parentheses strings.S, consider its primitive decomposition: S = P_1 + P_2 + ... + P_k, where P_iare primitive valid parentheses strings.S after removing the outermost parentheses of every primitive string in the primitive decomposition of S.Input: "(()())(())"
Output: "()()()"
Explanation:
The input string is "(()())(())", with primitive decomposition "(()())" + "(())".
After removing outer parentheses of each part, this is "()()" + "()" = "()()()".class Solution:
def removeOuterParentheses(self, S: str) -> str:
str_x = list(S)
rmv = [0]
left = 0
right = 0
for i in range(len(str_x)):
if str_x[i] == '(':
left +=1
elif str_x[i] == ')':
right +=1
if left == right:
rmv.append(i)
if i<(len(str_x)-1):
rmv.append(i+1)
index_list = [int(i) for i in rmv]
str_new = [v for i,v in enumerate(str_x) if i not in index_list]
str_final = "".join(str_new)
return(str_final)
class Solution:
def removeOuterParentheses(self, S: str) -> str:
res = ''
stack = []
# basket is used to store previous value
basket = ''
for p in S:
if p == '(':
stack.append(p)
else:
stack.pop()
basket += p
# if the stack is empty it means we have a valid
# decomposition. remove the outer parentheses
# and put it in the result/res. make sure to
# clean up the basket though!
if not stack:
res += basket[1:-1]
basket = ''
return res804. Unique Morse Code Words
"a" maps to ".-", "b" maps to "-...", "c" maps to "-.-.", and so on.[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]Example:
Input: words = ["gin", "zen", "gig", "msg"]
Output: 2
Explanation:
The transformation of each word is:
"gin" -> "--...-."
"zen" -> "--...-."
"gig" -> "--...--."
"msg" -> "--...--."
There are 2 different transformations, "--...-." and "--...--.".
words will be at most 100.words[i] will have length in range [1, 12].words[i] will only consist of lowercase letters.class Solution:
def uniqueMorseRepresentations(self, words: List[str]) -> int:
map = [".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]
alb = ["a","b","c","d","e","f","g","h","i","j","k","l","m","n","o","p","q","r","s","t","u","v","w","x","y","z"]
# 把对应关系封装到字典里面
edict = dict(zip(alb, map))
res = set()
for word in words:
mword = ""
for w in word:
mword = mword + edict[w]
res.add(mword)
return len(res)832. Flipping an Image
A, we want to flip the image horizontally, then invert it, and return the resulting image.[1, 1, 0] horizontally results in [0, 1, 1].0 is replaced by 1, and each 1 is replaced by 0. For example, inverting [0, 1, 1] results in [1, 0, 0].Input: [[1,1,0],[1,0,1],[0,0,0]]
Output: [[1,0,0],[0,1,0],[1,1,1]]
Explanation: First reverse each row: [[0,1,1],[1,0,1],[0,0,0]].
Then, invert the image: [[1,0,0],[0,1,0],[1,1,1]]
1 <= A.length = A[0].length <= 200 <= A[i][j] <= 1这道题我的想法是分两步:1.把每个元素都倒序一下;2.把每个元素的0变成1,1变成0class Solution:
def flipAndInvertImage(self, A: List[List[int]]) -> List[List[int]]:
s_new = []
for s in range(len(A)):
A[s].reverse()
# 因为怕把1直接变成0,全部的都是0就找不到原来的0,所以先变成2
s_f = [2 if x==1 else x for x in A[s]]
s_f = [1 if x==0 else x for x in s_f]
s_f = [0 if x==2 else x for x in s_f]
s_new.append(s_f)
return(s_new)class Solution:
def flipAndInvertImage(self, A: List[List[int]]) -> List[List[int]]:
return [[1 - x for x in i] for i in [i[::-1] for i in A]]
```
nested list comprehensions - firstly it reversed the list and then invert 1 with 0 (each item less 1 with absolute value)
```905. Sort Array By Parity
A of non-negative integers, return an array consisting of all the even elements of A, followed by all the odd elements of A.Input: [3,1,2,4]
Output: [2,4,3,1]
The outputs [4,2,3,1], [2,4,1,3], and [4,2,1,3] would also be accepted.
class Solution:
def sortArrayByParity(self, A: List[int]) -> List[int]:
return [i for i in A if i % 2 ==0]+[i for i in A if i % 2 != 0]961. N-Repeated Element in Size 2N Array
A of size 2N, there are N+1 unique elements, and exactly one of these elements is repeated N times.N times.Input: [1,2,3,3]
Output: 3class Solution:
def repeatedNTimes(self, A: List[int]) -> int:
dup = [x for x in A if A.count(x) >1]
return(dup[0])class Solution:
def repeatedNTimes(self, A: List[int]) -> int:
A_new = []
for i in range(len(A)-1):
A_new.append(A[i])
for j in range((i+1),len(A)):
if A[j] in A_new:
return(A[j])from collections import Counter
class Solution:
def repeatedNTimes(self, A: List[int]) -> int:
rep_dic = dict(Counter(A)) # Creates dictionary with number of repetitions
for key in rep_dic:
if rep_dic[key] == len(A)/2: return key # When value equals N, return key657. Robot Return to Origin
Input: "UD"
Output: true
Explanation: The robot moves up once, and then down once. All moves have the same magnitude, so it ended up at the origin where it started. Therefore, we return true.class Solution:
def judgeCircle(self, moves: str) -> bool:
A = list(moves)
# 分别计算LRUD有几个
L_final = [x for x in A if x == 'L']
R_final = [x for x in A if x == 'R']
U_final = [x for x in A if x == 'U']
D_final = [x for x in A if x == 'D']
if((len(L_final)==len(R_final))&(len(U_final)==len(D_final))):
return True
return Falseclass Solution:
def judgeCircle(self, moves: str) -> bool:
return (moves.count('D') == moves.count('U') and moves.count('L') == moves.count('R'))
# string.count() counts occurances in a string58. Length of Last Word
' ', return the length of last word in the string.class Solution:
def lengthOfLastWord(self, s: str) -> int:
if s == "": length = 0
else:
s = s.rstrip(" ")
length = len(s.split(sep = " ")[-1])
return length
590. N-ary Tree Postorder Traversal
3-ary tree: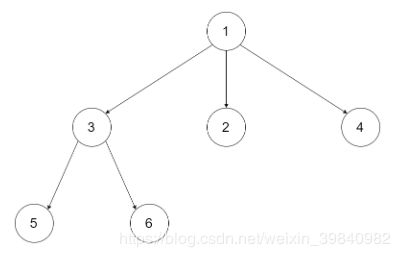
[5,6,3,2,4,1]."""
# Definition for a Node.
class Node:
def __init__(self, val, children):
self.val = val
self.children = children
"""
class Solution:
def postorder(self, root: 'Node') -> List[int]:
if root is None: return []
stack = [root]
res = []
while stack:
node = stack.pop()
res.append(node.val)
for child in node.children:
stack.append(child)
print(child.val)
return(res[::-1])
589. N-ary Tree Preorder Traversal
3-ary tree:[1,3,5,6,2,4]."""
# Definition for a Node.
class Node:
def __init__(self, val, children):
self.val = val
self.children = children
"""
class Solution:
def preorder(self, root: 'Node') -> List[int]:
if root is None: return []
result = [root.val]
for child in root.children:
result.extend(self.preorder(child))
return result
1160. Find Words That Can Be Formed by Characters
words and a string chars.chars (each character can only be used once).words.Input: words = ["cat","bt","hat","tree"], chars = "atach"
Output: 6
Explanation:
The strings that can be formed are "cat" and "hat" so the answer is 3 + 3 = 6.class Solution:
def countCharacters(self, words: List[str], chars: str) -> int:
ch_list = list(''.join(chars))
j_x = 0
for i in range(len(words)):
i_list = list(''.join(words[i]))
x_n = collections.Counter(i_list) -collections.Counter(ch_list)
if len(x_n) == 0:
j_x = j_x + len(i_list)
return(j_x)965. Univalued Binary Tree
true if and only if the given tree is univalued.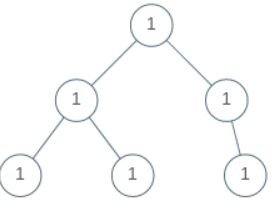
Input: [1,1,1,1,1,null,1]
Output: true# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
# value用来记录根节点的值和别的值进行比较
class Solution:
def isUnivalTree(self, root: TreeNode) -> bool:
if not root: return True
value = root.val
flag = self.helper(root,value)
return flag
def helper(self,root,value):
if not root: return True
if root.val!=value:
return False
left = self.helper(root.left,value)
right = self.helper(root.right,value)
return left and right9. Palindrome Number
Input: 121
Output: true
Input: -121
Output: false
Explanation: From left to right, it reads -121. From right to left, it becomes 121-. Therefore it is not a palindrome.class Solution:
def isPalindrome(self, x: int) -> bool:
s_new = list(str(x))
if s_new == s_new[::-1]: return True
else: return False645. Set Mismatch
S originally contains numbers from 1 to n. But unfortunately, due to the data error, one of the numbers in the set got duplicated to another number in the set, which results in repetition of one number and loss of another number.nums representing the data status of this set after the error. Your task is to firstly find the number occurs twice and then find the number that is missing. Return them in the form of an array.Input: nums = [1,2,2,4]
Output: [2,3]
class Solution:
def findErrorNums(self, nums: List[int]) -> List[int]:
x = sum(nums)-sum(set(nums))
lost = ((len(nums)+1)*len(nums))//2-sum(set(nums))
return([x,lost])