视觉SLAM十四讲:回环检测-知识点+代码
目录
- 基于外观的几何关系
- 1. 基础知识
- 1.1 准确率和召回率
- 1.2 词袋模型
- 1.3 字典
- 1.4 字典的数据结构
- 1.5 相似度的计算
- 1.6 相似度评分的处理
- 1.7 检测回环后的验证
- 2. 实践与代码解析
- 2.1 创建字典
- 2.2 相似度计算
回环检测的关键是,如何有效地检测出相机经过同一个地方。如果能够成功地检测到这件事,就可以为后端的位姿图提供更多有效的数据,使之得到更好的估计,特别是得到一个全局一致的估计。我们可以利用回环检测进行重定位。
回环检测的方法:
- 暴力匹配。
对任意两幅图像都进行特征匹配,根据正确匹配的数量确定哪两幅图像存在关联。
缺点:计算复杂度高,检测效率低。 - 基于里程计的几何关系
当发现相机运动到之前的某一个位置附近时,检测有没有回环关系。
缺点:累计误差存在,无法正确发现“运动回之前位置”的事实——>附近?累计误差很大的情况下? - 基于外观的几何关系
仅依据两幅图像的相似性确定回环检测关系,摆脱了累计误差,使回环检测模块成为SLAM系统中相对独立的模块。
基于外观的几何关系
1. 基础知识
1.1 准确率和召回率
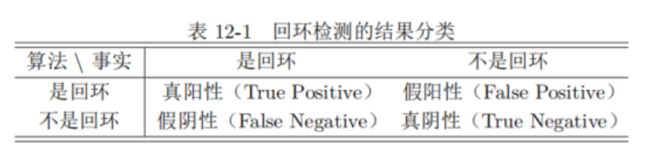
准确率:算法检测到“是回环”的结果里,有多少个真的是回环。(针对结果)
P r e c i s i o n = T P / ( T P + F P ) Precision = TP/(TP+FP) Precision=TP/(TP+FP)
召回率:有多少个真的回环,被算法检测到“是回环”了。(针对真实样本)
R e c a l l = T P / ( T P + F N ) Recall = TP/(TP+FN) Recall=TP/(TP+FN)
slam对准确率要求更高,因为如果实际不是回环,算法却判断为回环(即假阳性)会在后端Pose Graph中添加根本错误的边,严重影响算法结果。而召回率低一些关系不大,因为大不了没检测到回环,后端的优化有点漂移和累积误差而已。
1.2 词袋模型
词袋(BoW),强调的是词的有无,而不是顺序。目的是用“图像上有哪几种特征”来描述一幅图像。
大体步骤:
- BoW中的单词(某一类特征的组合,不等于特征点)——>字典
- 用单词出现的情况(或直方图)描述整幅图像——>向量描述图像
- 比较相似度,定义方式不唯一。
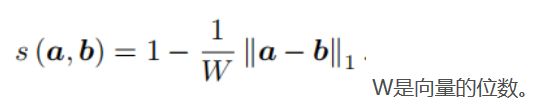
字 典 如 何 生 成 ? ? ? \red{字典如何生成???} 字典如何生成???
1.3 字典
字典生成问题类似于聚类问题,eg.想要一个有k个单词的字典,每个单词可以看作是局部相邻特征点的集合——>K均值算法!将已经提取的大量特征点聚类成一个含有k个单词的字典。
K-means大体步骤:

如 何 根 据 图 像 中 某 个 特 征 点 查 找 字 典 中 相 应 的 单 词 ? ? \red{如何根据图像中某个特征点查找字典中相应的单词??} 如何根据图像中某个特征点查找字典中相应的单词??
解决办法:K叉树
1.4 字典的数据结构
为提升查找效率,假定有N个特征点,希望构建一个深度为d,每次分叉为k的树——k叉树(叶子层是单词,中间节点的作用是方便查找)

根据已知特征查找单词时,可逐层对比,找到对应的单词。
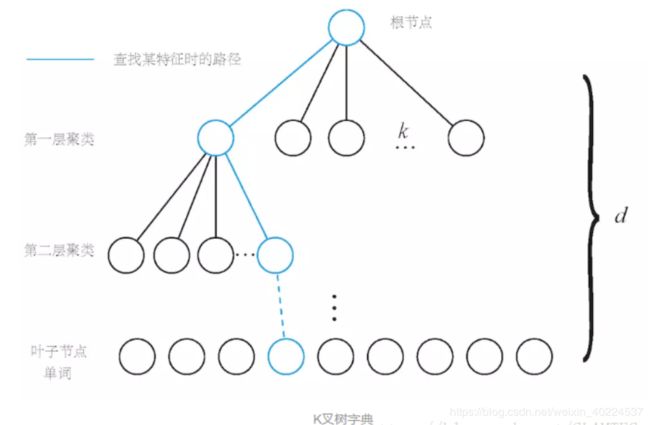
图 像 在 字 典 中 查 找 出 相 应 的 单 词 , 如 何 表 示 图 像 ? 两 图 像 的 相 似 度 如 何 计 算 ? \red{图像在字典中查找出相应的单词,如何表示图像?两图像的相似度如何计算?} 图像在字典中查找出相应的单词,如何表示图像?两图像的相似度如何计算?
1.5 相似度的计算
需要给叶子节点增加权重—对单词的区分性或重要性加以评估,给他们不同的权值以起到更好的效果。
加权方式:TF-IDF
基本思想:
TF:某单词在一幅图像中经常出现,则区分度高。IDF:某单词在字典中出现频率越低,分类图像时区分度越高。
计算:
TF:假设单幅图像A中单词 w i w_i wi出现了 n i n_i ni次,一共出现的单词数为 n n n次,(即图像里有 n n n个单词,其中某个单词出现的次数是 n i n_i ni次,换句话说就是一幅图像中有 n i n_i ni个特征点同属这个单词)
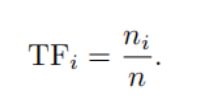
IDF:某个叶子节点 w i w_i wi中特征点的数量相对于所有特征点的比例。假设字典中所有特征数量为 n n n, w i w_i wi中特征点的数量为 n i n_i ni:

于是,某叶子节点 w i w_i wi的权重等于TF与IDF之积。
【注意】IDF是离线计算,也就是说所有的图像都已经有了,提取特征点聚类了。而TF是在线计算,来一张算一张。
对图像提取特征点,找到字典里的单词,计算权重,并且形成一个向量。
每个单词(也就是一小部分特征点的集合)指向这么一个数据结构:一个是图像号,一个是权重。这也就是词袋中的“逆序指针/索引”。
关于数据结构的详细解析可查看这篇博客的第三部分——指路。
图像的表示:
每一幅图像,都由向量表示,即一堆 ( w i , n i ) (w_i,n_i) (wi,ni)组成。 w i w_i wi是检测到的单词, n i n_i ni是上面算出的TF和IDF的乘积(每个单词在不同图像中对应的TF是不一样的,而单词自身的IDF是一样的)
A = { ( w 1 , n 1 ) , ( w 2 , n 2 ) , . . . , ( w N , n N ) } = v A A = \{(w_1,n_1),(w_2,n_2),...,(w_N,n_N)\} = v_A A={(w1,n1),(w2,n2),...,(wN,nN)}=vA
由于相似的特征可能会落到同一个类中,因此描述图像的向量会存在大量的零——>稀疏向量。通过词袋,我们用一个向量描述了一幅图像。
计算相似度:
直接计算两个向量的差异得到相似度。具体方法很多,这里给出一种 L 1 L_1 L1范式:
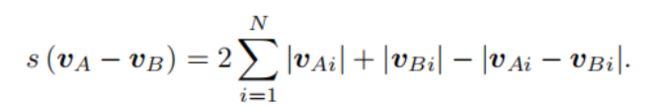
如 何 根 据 计 算 出 的 相 似 度 进 行 评 估 ? \red{如何根据计算出的相似度进行评估?} 如何根据计算出的相似度进行评估?
1.6 相似度评分的处理
取一个先验相似度 s ( v t , v t − δ t ) s(v_t,v_t - \delta t) s(vt,vt−δt),它表示某时刻关键帧图像与上一时刻的关键帧的相似性,然后其他的分值都参照这个值进行归一化。
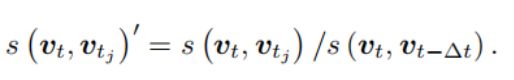
如果当前帧与之前某一帧的相似度超过当前帧与上一帧关键帧相似度的3倍,就认为可能存在回环。
【注意】用于回环检测的帧可以取的稀疏一些,彼此不同但涵盖整个环境。在后端优化中,主要优化的也是关键帧。把"相近"的回环聚成一类,使算法不要反复地检测同一类的回环。
1.7 检测回环后的验证
词袋的回环检测完全依赖外观而没有利用任何的几何信息。这导致外观相似的图像容易被当成回环。并且由于词袋不在乎单词的顺序,只在意单词的有无,更易引发感知偏差,所以在回环检测后,通常会有一个验证步骤。
具体方法分为两类:
- 时间上的一致性检测:设立回环缓存机制认为单次检测到的回环不足以构成良好的约束,一段时间内一直检测的回环才当做是回环(n,n+1,n+2……帧都和关键帧像,才当做是回环)
- 空间上的一致性检测:把回环上的两帧进行特征匹配,估计相机运动。把运动放到之前的Pose Graph中,检查与之前估计是否有很大出入。
2. 实践与代码解析
选取TUM数据集中的来自一组实际相机运动轨迹的10幅图像,首尾两张图位于同一地方。验证算法可否检测到这一回环。
2.1 创建字典
如何生成及使用ORB字典??–先根据词袋模型生成这10张图像对应的字典。
【注意】生成字典的数据应该来自与目标环境类似的地方。在计算能力和内存范围内,通常使用较大规模的字典——字典越大代表单词量越丰富,越容易找到当前图像对应的单词。
准备工作: 安装BoW库-采用cmake流程进行编译安装
相关代码:
int main( int argc, char** argv ) {
// read the image
cout<<"reading images... "<<endl;
vector<Mat> images;
for ( int i=0; i<10; i++ )
{
string path = "./data/"+to_string(i+1)+".png";
images.push_back( imread(path) );
}
// detect ORB features
cout<<"detecting ORB features ... "<<endl;
Ptr< Feature2D > detector = ORB::create();
vector<Mat> descriptors;
for ( Mat& image:images )
{
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
}
// create vocabulary
cout<<"creating vocabulary ... "<<endl;
DBoW3::Vocabulary vocab;
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;
vocab.save( "vocabulary.yml.gz" );
cout<<"done"<<endl;
return 0;
}
【注意】DBoW3::Vocabulary对象的构造函数中,可以指定树的分叉数量以及深度。这里用的是默认的构造函数,k=10,d=5。对于图像特征也使用默认参数,每幅图提取500个特征点。
【make过程出错】:
没有规则可制作目标“/usr/local/lib/libDBoW3.a”,由“gen_vocab” 需求
解决办法:只需要将CMakeList.txt中的libDBow3.a改为libDBow3.so即可。
【运行后单词数为0】:
将图片路径改为详细路径:string path = “/xxxxx/data/”+to_string(i+1)+".png";
【注意】最好还是在读取图片时搞个判断!!!太坑了!!!
实验结果:

可以看到:分支数量k=10,深度L=5,单词数量为4983,Weighting是权重,Scoring是评分。
2.2 相似度计算
在2.1实践中已经对十幅图像生成了字典,现在使用此字典生成词袋并比较他们的差异。
相关代码:
演示了两种对比方式:图像之间的比较以及图像与数据库之间的比较。
int main(int argc, char **argv) {
// read the images and database
cout << "reading database" << endl;
DBoW3::Vocabulary vocab("./vocabulary.yml.gz");
// DBoW3::Vocabulary vocab("./vocab_larger.yml.gz"); // use large vocab if you want:
if (vocab.empty()) {
cerr << "Vocabulary does not exist." << endl;
return 1;
}
cout << "reading images... " << endl;
vector<Mat> images;
for (int i = 0; i < 10; i++) {
string path = "/home/jiachenxin/slambook/ch11/data/" + to_string(i + 1) + ".png";
images.push_back(imread(path));
}
// NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may lead to overfit.
// detect ORB features
cout << "detecting ORB features ... " << endl;
Ptr<Feature2D> detector = ORB::create();
vector<Mat> descriptors;
for (Mat &image:images) {
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute(image, Mat(), keypoints, descriptor);
descriptors.push_back(descriptor);
}
// we can compare the images directly or we can compare one image to a database
// images :
cout << "comparing images with images " << endl;
for (int i = 0; i < images.size(); i++) {
DBoW3::BowVector v1;
vocab.transform(descriptors[i], v1); // v1:需要求的该图像的词袋模型 des[i]:第i图像上所有描述子
for (int j = i; j < images.size(); j++) {
DBoW3::BowVector v2;
vocab.transform(descriptors[j], v2);
double score = vocab.score(v1, v2); // 计算相似度
cout << "image " << i << " vs image " << j << " : " << score << endl;
}
cout << endl;
}
// or with database
cout << "comparing images with database " << endl;
DBoW3::Database db(vocab, false, 0);
for (int i = 0; i < descriptors.size(); i++)
db.add(descriptors[i]); // 生成数据库
cout << "database info: " << db << endl;
for (int i = 0; i < descriptors.size(); i++) {
DBoW3::QueryResults ret;
db.query(descriptors[i], ret, 4); // 返回四个结果
cout << "searching for image " << i << " returns " << ret << endl << endl;
}
cout << "done." << endl;
}
【注意】图像获取地址的修改
实验结果:
两幅图像对应的词袋描述向量:
运行命令:~/slambook/ch11/build$ ./feature_training
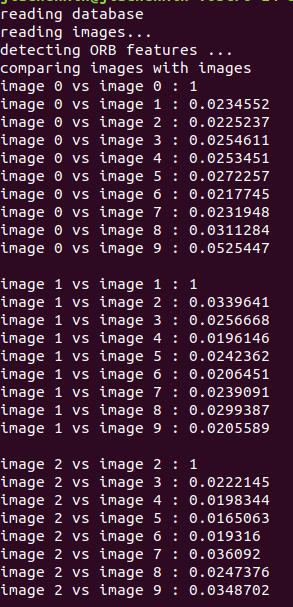
两图像间的比较(这里只截了一小块):
运行命令:~/slambook/ch11/build$ ./loop_closure
图像与数据库的比较(截取一下块):
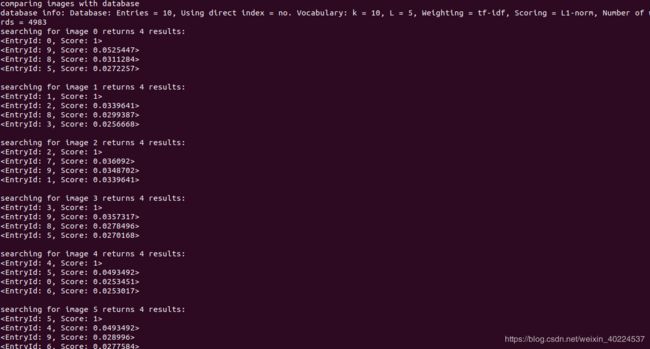
可以看到图像1和10的评分明显高于其他图像。