笔记回顾1|Adversarial Machine Learning的总览1
笔者原先是做传统安全的,专注于系统安全与软件安全的任务研究和算法优化。但是近几年,在“人工智能”话题火热的情况下,有关机器学习安全的问题,也是层出不穷。因此这段时间,对于这个方向有所初探,并把相关的内容自己总结成文记录下来。
注:这里引用一下我师弟Zhongling He当时在做报告时候的ppt时候的截图,帮助我总结来提炼重点。(虽然我也给了点微小的指点)

首先来回顾下机器学习的概念,其概念就是使用统计的技术使得计算机系统具有学习的“智能”。但是,计算机系统对于数据的学习能力只能局限于特定的任务,也是因为局限于当前的算法,对于场景和数据敏感性比较强,还没有我们认知中这么强的迁移能力。因此我们当前的人工智能还停留于“弱人工智能”阶段,同时要进步到“强人工智能”还需要一段时间。
这里还想补充一点,机器学习的起点就是基于数学的,目前在笔者视野范围里,一个模型的学习结果,是对于当前特定数据集合中规律的抽取,并通过数据组合规律的“学习”,去尽可能逼近最终目标场景中“函数”。

那么对于具体的学习任务而言,主要是分为三类,监督学习,非监督学习和强化学习。对于监督学习而言,输入模型的信息即为{Xi,Yi},Xi指的是第i个样本的特征向量,Yi指的是第i个样本的标签,与监督学习不同的是,非监督学习输入模型的信息只有{Xi}。而强化学习更为特殊,是以一个agent的状态,在向环境中获取信息,并作出相应action,获得reward来使得最终目标最优化。
当然,除了这三种之外,还有半监督学习,等等,都是在我们讨论的范围之中。

如上图所示,我们看到了对于监督学习而言,主要的子类有分类问题和回归问题。他们两者主要的问题在于,分类问题的输出结果是非连续的,也就是离散的,而回归问题的输出结果是连续值。对于分类问题而言,有比较多的现实生活中的例子,例如垃圾邮件过滤器中的分类模型,又例如现在深深得益于深度神经网络概念的图像分类问题;反观回归问题,则可以被应用于股票预测,或者是决策支持的领域当中。
图示中的结果,是针对不同的分类问题和回归问题在二维问题上的映射情况,具体的情况一般都会复杂很多,仅仅作为图示来参考。

可以看到非监督学习,和监督学习和强化学习有所不同,主要的任务可以认为是聚类、密度预测和降维等。聚类问题的中心思想是通过样本的相似性,将较为类似的样本分到一类之中,种类的数量可以自行分类,或者让算法根据具体场景自适应。
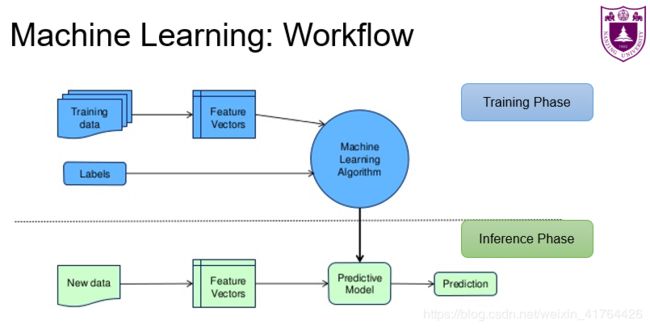
回顾了主要的方法之后,再来看看机器学习具体的工作流程是怎么样的。主要分为两个阶段:训练阶段和推理阶段。在训练过程中,主要是先获取训练数据和标签(如果是监督学习的话),然后一般对于准备好的数据集,不需要进行数据的清洗和预处理,如若数据是自行收集、调研或爬虫爬取的话,可能还需要对数据进行一些先行处理。接着对数据进行数据化的表示,然后输入到提前准备(挑选)好的模型中,进行适当轮次的训练。在推理阶段过程中,则是获取到需要预测的数据,再对数据进行相同的处理,表示成相同的特征向量,进入到模型之后,就可以获得最后的预测结果。
其实到这一步,我们可以看到,到底在整个过程中,会有哪些问题的产生呢?请看下图
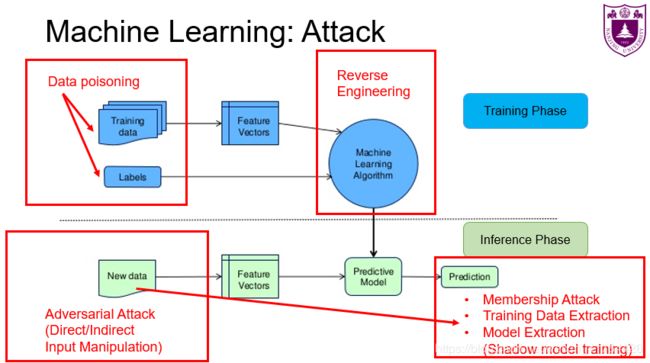
在训练阶段,主要是在输入数据和模型训练的过程中,会产生安全隐患。而在推理阶段,在预测数据部分和结果预测部分,也会对原有的模型产生威胁。由阶段我们分作四部分来阐述:
1、训练阶段的输入数据
当我们能接触,或间接修改模型训练阶段的输入数据的时候,无论是篡改部分数据的特征样本,亦或是“翻转”样本的标签,也可以是在部分训练数据分布敏感的场景下,都有可能对最后的模型准确性产生影响。
2、训练阶段的模型训练
一些在线的模型训练API,如若没有做好万全的防御措施,则可能会被恶意的攻击者,通过“逆向工程”的方式来解析模型的内部结构,从而导致模型的隐私信息的泄露。
3、推理阶段的预测数据
一个模型最重要的部分,就是希望能在推理阶段,能有尽可能高的推理准确率,不论其是否在训练数据中出现过。如果,我们恶意的对推理数据进行一些变化,让它看起来还是和正常的数据类似,但是我们在其某些特征上,动了些手脚,亦或是我们将部分信息“隐写”在图片当中,让模型进行错误的分类。
4、推理阶段的结果预测
一旦需要预测的数据出现了误差,那么最终的结果不论是对错,都已经对模型的准确性和鲁棒性产生了影响。在这个阶段,当恶意的攻击者,变化尽量少的数据样本,达到了最高的错误分类情况,那么他们就攻击成功了。当然还有更加危险的情况,就是如果部分的模型信息被泄露了的话,很有可能可以通过模型的输入和输出,通过建立“影子”模型,模拟原有模型的行为,从而实施更加自由的攻击模式。
这些是此领域中的overview,更加详细的内容,会在之后的博客中呈现。如有偏误,望斧正。
以上。