python_sklearn机器学习算法系列之PCA(主成分分析)------人脸识别(k-NearestNeighbor,KNN)
本文主要目的是通过一个简单的小例子和很短的代码来快速学习python 中的sklearn.decomposition 的 PCA(主成分分析)这一模块的基本操作和使用,注意不是用python纯粹从头到尾自己构建PCA(主成分分析),既然sklearn提供了现成的我们直接拿来用就可以了,当然其原理十分重要,下面简单介绍:
(关于PCA更多数学上面的推导可以查看笔者另一篇博客https://blog.csdn.net/weixin_42001089/article/details/83151342)
定义:主成分分析(Principal Component Analysis,PCA), 将多个变量通过线性变换以选出较少个数重要变量的一种多元统计分析方法。又称主分量分析。
哈哈哈,听起来有点高大上是不是?我们举个不太恰当的类子来说明一下:比如现在我们要判断一个男生是不是高富帅,那么我们就需要了解一下他的情况以便做出判断,我们可以从他多方面进行考虑:身高、学历、性格、资产、兴趣、样貌、血压、心率、作息时间……等等。如果可以,我们足以采集许多参数,但是就判断其是否是高富帅来说,显然身高、资产、样貌这三个参数非常重要,甚至我们仅通过这三个参数就可以做出判别,这个过程就是上面所谓的 “选出较少个数重要变量”。再说的直白一点就是身高、资产、样貌这三个参数对我们做判断贡献很大,而另一些参数例如作息时间贡献较少,PCA要做的就是在众多特征中选取最重要的几个特征,很明显PCA后特征数变少了,故说PCA是降维也可以理解了对吧。
那PCA是怎么挑选出这些特征的呢?它的核心步骤就是:(假如原始数据集为矩阵M,M中每一行代表一个样本,每一列代表同一个特征)
一 (零均值化):求每一列的平均值,然后该列上的所有数都减去这个均值。
二 :求该矩阵的协方差矩阵
三 :求特征值、特征矩阵
四 :保留主要的成分(即保留值比较大的前n个特征)
当然这里只是简单的口述了一下过程,大家可以去查每一步的具体数学公式,因为本文重点是强调怎样使用,所以关于原理就讲到这里。
下面我们开始讲我们要用到的数据集,即fetch_lfw_people
使用from sklearn.datasets import fetch_lfw_people导入后其会自行下载,下载后可以在C:\Users\asus-\scikit_learn_data\lfw_home\lfw_funneled找到,如下

每一个文件下都有人名对于的图片,例如Alison_Lohman下就是一个美女嘿嘿

使用下面代码可以看到该数据集都包含什么?
print (lfw_people.keys())![]()
这里比较重要的就是data,target和target_names了。其实关于人脸的数据集包括两大部分,一类是Face Recognition使用fetch_lfw_people引用:每个文件下都有很多图片,用于给出一张图,判断出是哪个人;另一类就是Face Verification使用fetch_lfw_pairs引用:每一个sample是两张图片(可能属于同一个人、也可能不是)。所以我们下载好后的文件夹下有的有很多图片,有的有仅一张例如:
而这里就一张
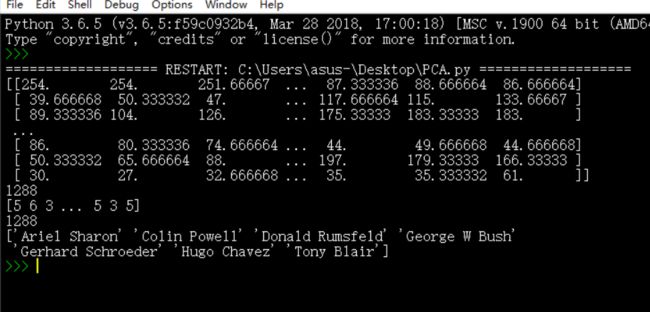
那么我们这里主要是实现Face Recognition,该数据集一共包括1288张图片,每张图片包括1850个特征,data就是记录每一张图片的1850个特征的,target_names里面是人名,target是记录该张图片的人的名字(分别用0,1……代表)
由下面可以直观看到:
from sklearn.datasets import fetch_lfw_people
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
print(lfw_people.data)
print(len(lfw_people.data))
print(lfw_people.target)
print(len(lfw_people.target))
print(lfw_people.target_names)
可以看到有一个叫Colin Powell的人,我们去文件夹下看一下这位大神,Oh my god! 这里有很多他
好了到此我们源数据已经介绍完毕,我们要使用PCA将1850个特征值降为100个
PCA 最关键参数就是n_components,其代表我们要降到多少维,我们这里设为100
它有两个关键函数分别为:
fit(X),表示用数据X来训练PCA模型。
fit_transform(X),用X来训练PCA模型,同时返回降维后的数据。
测试代码如下:
#PCA
import warnings
from sklearn.cross_validation import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
#忽略一些版本不兼容等警告
warnings.filterwarnings("ignore")
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
x=lfw_people.data
n_features=x.shape[1]
y=lfw_people.target
target_names=lfw_people.target_names
#分割训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.4)
#先训练PCA模型
PCA=PCA(n_components=100).fit(x_train)
#返回测试集和训练集降维后的数据集
x_train_pca = PCA.transform(x_train)
x_test_pca = PCA.transform(x_test)
print(x_train_pca.shape)
print(x_test_pca.shape)
运行结果

可以看到训练集和测试集分别为772和516,因为我们将test_size=0.4所以1288*0.4大约就是516,另外就是两者维度都降为100啦!
下面我们就选用分类算法了,这里选用k-NearestNeighbor算法,关于这个算法的具体python调用请看之前的一片文章:
python_sklearn机器学习算法系列之k-NearestNeighbor(K最近邻分类算法)
这里不再阐述直接上代码:
#PCA
import warnings
from sklearn.cross_validation import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
#忽略一些版本不兼容等警告
warnings.filterwarnings("ignore")
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
x=lfw_people.data
n_features=x.shape[1]
y=lfw_people.target
target_names=lfw_people.target_names
#分割训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.4)
#先训练PCA模型
PCA=PCA(n_components=100).fit(x_train)
#返回测试集和训练集降维后的数据集
x_train_pca = PCA.transform(x_train)
x_test_pca = PCA.transform(x_test)
#KNN核心代码
knn=KNeighborsClassifier(n_neighbors=6)
knn.fit(x_train_pca ,y_train) #用训练集进行训练模型
#识别测试集中的人脸
y_test_predict=knn.predict(x_test_pca)
#输出
for i in range(len(y_test_predict)):
print(target_names[y_test_predict[i]])
输出为:
成功实现输出了这些人都叫什么名字,但是问题又来了,我们怎么知道结果对不对呢?别着急接下来我们解决这个问题
我们用的是统计学上面的一些概念,准确率,召回率、F1值、混淆矩阵。下面做简单介绍
召回率recall:检索到的相关文档 /库中所有的相关文档
准确率precision:检索到的相关文档/所有被检索到的文档
F1=准确率 * 召回率 * 2 / (准确率 + 召回率)
有点晕是吧,好的我们再举个简单例子:假设一个袋子中有4颗黑球,6颗红球,8颗白球,我们现在伸手进去抓球,目的是抓白球,结果抓出来1个黑球,2个红球,2个白球(哈哈,假设球很小,我们一次性能抓5个)那么:
precision=2/(1+2+2)=0.4 recall=2/8=0.25 相信F1值大家也会算了吧
其实F1就是综合考虑召回率recall和准确率precision的一个指标
至于混淆矩阵的每一列代表了预测类别 ,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目。
通过下面三条代码可以看这些统计值:
print(knn.score(x_test_pca, y_test)) #预测准确率
print(metrics.classification_report(y_test,y_test_predict)) #包含准确率,召回率等信息表
print(metrics.confusion_matrix(y_test,y_test_predict)) #混淆矩阵
好了,看看我们预测结果的好坏吧
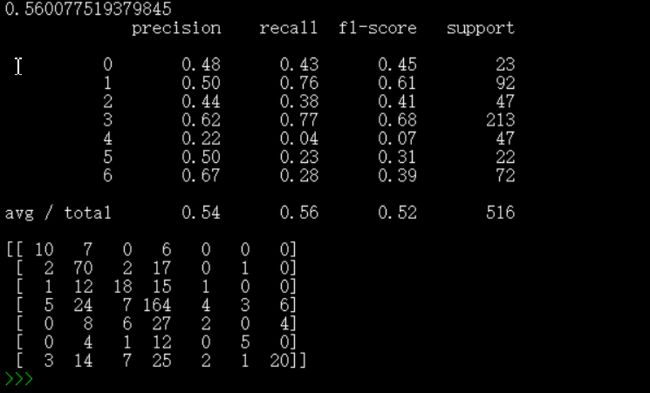
可以看到结果不是很好,比如第一个人的图片有23张,被正确预测是10张,7张被误认为是第二个人,6张被误判为第4个人
当然了有很多优化的方案,比如分类算法可以选用SVM等等
好了,最后给一下本文完整的代码,供大家学习,有不完善的地方,望大家海涵:
#PCA
import warnings
from sklearn import metrics
from sklearn.cross_validation import train_test_split
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsClassifier
#忽略一些版本不兼容等警告
warnings.filterwarnings("ignore")
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
x=lfw_people.data
n_features=x.shape[1]
y=lfw_people.target
target_names=lfw_people.target_names
#分割训练集和测试集
x_train,x_test,y_train,y_test = train_test_split(x, y, test_size=0.4)
#先训练PCA模型
PCA=PCA(n_components=100).fit(x_train)
#返回测试集和训练集降维后的数据集
x_train_pca = PCA.transform(x_train)
x_test_pca = PCA.transform(x_test)
#KNN核心代码
knn=KNeighborsClassifier(n_neighbors=6)
knn.fit(x_train_pca ,y_train) #用训练集进行训练模型
#识别测试集中的人脸
y_test_predict=knn.predict(x_test_pca)
'''
#输出
for i in range(len(y_test_predict)):
print(target_names[y_test_predict[i]])
'''
print(knn.score(x_test_pca, y_test)) #预测准确率
print(metrics.classification_report(y_test,y_test_predict)) #包含准确率,召回率等信息表
print(metrics.confusion_matrix(y_test,y_test_predict)) #混淆矩阵
更多算法可以参看博主其他文章,或者github:https://github.com/Mryangkaitong/python-Machine-learning