依图科技 CTO 颜水成:视觉计算—AI 算法 vs. AI 芯片
2019-11-11 19:30:57
10月27日,由雷锋网 & AI掘金志主办的「全球AI芯片·城市智能峰会」,在深圳大中华喜来登酒店盛大召开。
延续雷锋网大会一贯的高水准、高人气,「全球AI芯片·城市智能峰会」以“城市视觉计算再进化”为主题,全面聚焦城市视觉与城市算力领域,是业内首个围绕“算法+算力”展开的大型智能城市论坛。
峰会邀请到了业内极具代表性的14位知名专家,世界顶尖人工智能科学家、芯片创业大牛、产业巨头技术高管、明星投资人齐聚,为行业资深从业者们分享前瞻的技术研究与商业模式方法论。

在大会上午环节,依图科技 CTO、IEEE Fellow颜水成博士发表了题为《视觉计算:AI 算法 vs. AI 芯片》的精彩演讲。
颜水成分享说,人类文明变迁的核心点在于基础设施的革命,由此带来的直接影响是人和人之间的沟通效率和方法有显著提升,沟通更有保障。而视觉智能作为AI的主力军,也同样非常依赖于基础设施的变革,一方面是视觉信号的传输,另一方面则是AI的算法和算力。随着IoT的发展和5G的普及,将会有越来越多的算力用于视觉计算。
颜水成介绍说,城市智能可以分成5个等级,从低到高分别是可记录——可识别——可关联——可预判——可规划,相应地,对基础设施的需求也不断提高。
而基础设施的提升,关键是“智能密度”的提升。宏观上,单个摄像头提取数据发展为不同的摄像头可以进行信息的共享、对话,形成一个更强大的智能体。微观上,则需要提升单位面积的智能算力。
他总结称,依图提出“算法即芯片”的思想,是视觉计算的核心驱动力。做一款AI芯片,首先要想清楚它的典型的应用场景,同时也要对芯片设计和未来的AI算法的发展趋势有一个预判,这样让算法和芯片设计能够相互优化,协同开发,同时又实现分层解耦。依图所承建的视觉计算国家新一代人工智能开放创新平台,将为视觉计算开发者提供更加标准和高效的支持与服务,提升智能芯片、智能算法和智能产品的整体产业能力,打造开放创新融合的共赢生态。

以下是颜水成大会现场演讲内容,雷锋网做了不改变原意的整理及编辑:
今天我代表依图分享一些我们对AI的看法和做法。我们做AI一直在追求创新,但其实在人类文明发展的历程中已经把创新蕴涵在其中了,这也是为什么很多创业公司的创始人和一些孵化器每年都会组织到世界文明的起源地探寻人类文明的真谛,比如说去埃及、希腊。
在探寻的过程中我们会发现,其实现在我们能够触及到的,用视觉的方式能了解到的是农业文明的中后期,比如说古希腊文明。但是本质上来说,文明是经历了原始文明、农业文明,以及我们能感受到的工业文明,还有现在我们所处的信息文明。

在文明的发展过程中,人类的智能化已经到了一个很高的水平。但是在另一个维度,还有一个新物种,就是人工智能。它在过去60多年的时间里,有了飞速的发展。就像刚才的嘉宾介绍的,人工智能最重要的发展点是2016年AlphaGo战胜了人类的围棋世界冠军,让我们想象到以后人工智能将会有更大的发展,因此在思考“人工智能的发展将超越人的智能”这个奇点的到来。
基础设施变革推动智能跃迁
总的来说,人类文明的变迁,核心点是在于基础设施的革命,而这种基础设施变革带来的直接影响是什么呢?是人和人之间的沟通效率和方法有很大的提升,而且这种沟通有了更好的保障。
比如说在原始社会我们只有弓箭、火;农业社会,有了道路和轮子,可以快速和别人沟通交流。工业社会,有内燃机、铁路,人和人沟通的效率又有更大的提高。到了信息社会,我们不需要进行人的迁移,通过互联网就可以在任何时间、任何地方跟其他人进行交互——核心点都是因为基础设施发生了巨大的变化。

同样地,信息文明中后期的智能文明,也非常依赖于基础设施的变化。就像我们今天所讨论的主题“视觉智能”,它其实是AI的主力军,它也同样非常依赖于基础设施的变革。一方面是视觉信号的传输,另外还有两个非常重要的维度,就是AI的算法和算力。当前用于处理视觉信号的AI算力在不断地提升,随着IoT的发展以及5G普及,会有越来越多的算力用于视觉计算,这跟人的大脑里面的状况非常相似,在人的大脑里面用来处理视觉信号的神经元占皮层的面积大概30%。
在依图,我们将视觉智能分成5个等级:
-
L1:简单的记录,便于我们回溯;
-
L2:可识别,帮助我们做检索;
-
L3:可关联,可以把不同的摄像头分析的结果相互关联,帮助我们做推理;
-
L4:可预判,有了更多的摄像头,可以对未来发展的趋势进行预判;
-
L5:可规划,帮助我们统筹规划。
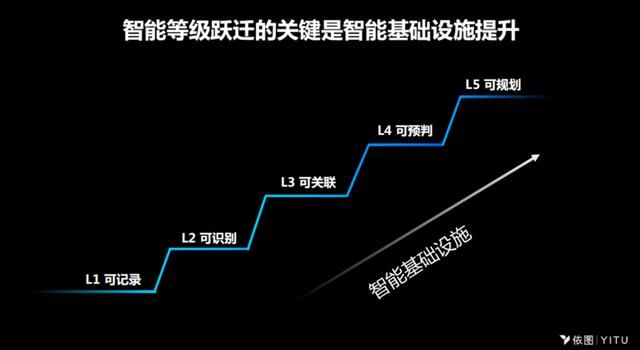
从L1到L5发展的过程,也是基础设施不断提升的过程。比如说在城市管理里面,当摄像头的数量从5000个上升到20万的时候,我们能为城市的管理者所提供的能力将会有大幅的变迁。

算法即芯片的核心概念
基础设施的提升,关键就是要提升它的智能密度,才能保障整个服务能够达到更好的水平。

宏观层面上,要提升智能的密度,也就是从单个摄像头提取数据,发展成让不同的摄像头互联并共享信息,彼此之间可以对话,基于这种分析形成一种更高的智能。
在微观层面,要提升单位面积的智能算力。不同于传统的机械算力,智能算力指芯片运行AI算法实现的智能。这是一个算力和算法相互融合、相互优化的过程。
依图为了实现这个目标,研发了一款AI芯片。当时发布会上现场插电演示,芯片发布即商用。也就是说,这款芯片发布的时候,基于这款芯片做的AI服务器,已经可以达到商用的程度。
其实AI芯片是专用的芯片,在市场上已经有很多的厂商,包括大厂、小厂,都在做这个事情。依图要做AI芯片,它背后的内在逻辑是什么?为什么依图还能做一款有市场竞争力的AI芯片呢?
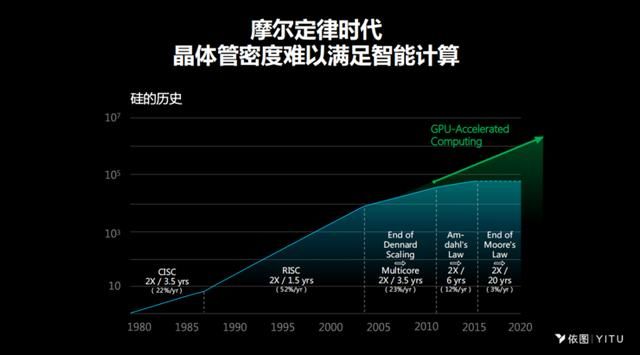
一是因为摩尔定律的时代已经结束。前面在很长一段时间里面,大家相信每18到24个月,在同样面积芯片上能够承载的晶体管的数目会翻一番,但是在最近几年,这个定律已经不再适用。另一方面,GPU加速的AI计算的算力大幅提升。

在这样的情况下,依图提出了一个核心的概念——算法即芯片。什么是算法即芯片?我们要做一款有竞争力的AI芯片的时候,要非常明确这个AI芯片典型的使用场景。
其次,要预测最前沿的AI算法发展趋势,当我们设计芯片的时候,我们要能够预测到可能有什么新算法,这在一个特定的场景中非常重要。要提前保障芯片在之后能够承载和支持这些最前沿的算法。这样我们在做芯片架构设计的时候,就相当于把未来AI算法发展的可能性包含进来,这样就实现了AI芯片和AI算法的相互优化,同时又实现分层的解耦,这样我们才有可能生产出一款具有市场竞争力的AI的芯片。
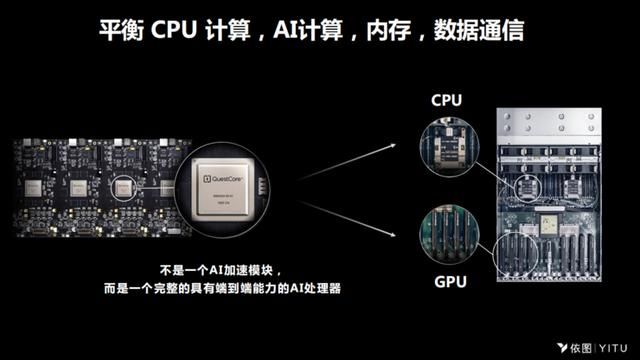
依图的AI芯片不是一个AI加速器,而是具备了一个完整的端到端处理能力的AI处理器。我们在设计芯片的时候,很好地平衡了CPU的计算、AI的计算、内存和数据通信之间的关系,这样可以更大程度地提升整体计算的效果。
依图求索芯片瞄准的使用场景是在云端的AI推理,它也支持边缘的计算,支持部署的系统化,同时也支持常见的不同类型的深度学习框架,更重要的是支持各种常用的视觉AI算法,比如说检测、识别、分割、追踪,对它未来可能会使用的场景进行了充分预测,因此在我们具体实施的时候,能保证它的高效化。
当前一路视频的功耗,能做到小于1瓦。整体来说我们已经具备端到端的处理能力,既具备传统CPU通用的计算能力,比如说数据的支持等等,也有非常强的解码能力,当然更强的是AI的通用视觉计算能力。
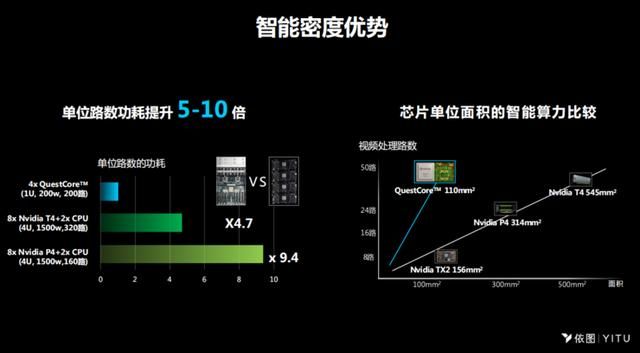
对比市场上通常用的CPU+GPU的架构,同样处理单路的视频,完成同样的功能,依图AI芯片所需要的功耗能够大概降低到市面上最先进GPU解决方案的1/5到1/10。另外一个维度是芯片的单位面积的智能算力,直接量化下来是能处理的路数,斜率越大,表示效率越高,依图的斜率远远大于市面上其他的斜率。
基于依图的QuestCore,已经有两款产品,一款是云端的AI服务器,一款是用于边缘计算的边缘盒子。1U的云端服务器支持200路高清视频全解析,边缘盒子支持16路。边缘盒子使用的场景包括智慧课堂、别墅安防等等。它们都有共同的特点,并不需要额外的CPU的支持,而且可以非常便捷地把市面上不同模型,快速地部署到我们的硬件上。
依图在做AI芯片和AI服务器的目标也非常明确,用一个机柜处理1万路视频,让数据中心建得起、用得省,而且也能使用世界领先的AI算法。“用得省”这一点非常重要,我们可以大幅节省电费,省80%的运维投入。

经过7年多的积累,依图在AI算法上已经做到非常好的程度,保证了我们解决方案的精度的要求。但要解锁很多的其它的场景,让解决方案落地,必须看我们的用户是不是用得起、买得起。基于依图AI芯片建立的AI服务器,很好地解决了这一问题。非常好的算法精度再加上用户可以买得起的硬件解决方案,帮助依图解锁越来越多的不同的场景。
依图的AI算法团队在视觉计算领域取得了非常多的大家熟知的成就。比如说在世界的竞赛中,依图总共获得了15次的世界冠军和提名奖,在国内获得了10次的大奖。比如说计算机视觉,Pascal2,这是欧盟举行了8年的比赛;ImageNet,这也是一个有8年历史的知名竞赛。在人脸识别领域有一个非常重要的评测,是美国国家标准技术局举办的,工业界最高水平人脸识别技术测试,依图的团队曾经连续三年获得第一名的成绩。今年在厦门举行的多媒体识别竞赛中,依图在11项比赛中有10项获得了A类证书。

我觉得评价一家公司AI能力,一方面是在比赛中获得的成绩,更重要的是你的团队有没有为这个社会留下有价值的AI的算法。依图的团队,比如说我们的创始人,他是做层次学习的,这一块他的成就对整个视觉分析起到了非常重要的作用。到了深度学习时代,比如说我们团队以前提出的1×1的卷积,也就是Network in Network,这是视觉计算里面几乎所有人都会用到的模块。还有一个刚刚加入到依图的同事,也是我的学生,他提出1/8卷积,将视觉分析的速度进行了加速,并且精度没有损失,他也是2017年ImageNet收官之战的冠军。依图的团队既在比赛中有很好的成绩,同时也为这个领域的发展提供了不少的原创性研究成果。
建设视觉计算国家开放创新平台,促进算法与芯片对接
正因为依图在AI芯片和AI算法两个维度都有不俗的表现,今年8月底科技部宣布依托依图建设视觉计算国家新一代人工智能开放创新平台。这个平台要做什么?它要解决的其中一个问题是现在的算法和芯片对接的一个非常挑战性的问题。
现在一般的AI芯片,要让客户所使用的话,首先要派人对我们的客户进行培训。但市面上有那么多人希望使用AI芯片,又有那么多的芯片提供商,其实很多的工作是重复浪费的,所以科技部希望依图能建设一个在线的算法和芯片对接测试平台,也就是把芯片“虚拟化”,在这个平台上,算法方和芯片方可以相互优化、协作开发,同时又实现芯片和算法的分层解耦。
具体说,任何算法开发者都可以把模型上传到这个平台,平台会把它转换成能够在不同芯片上运行的模型。同时,把这些模型放到物理芯片上进行测试,把全面分析的测试报告再分享给算法开发者和芯片开发者。借助这个过程,我们可以帮助大家更好地实现软硬件协同开发。
算法开发者根据测试报告就知道自己的算法,比如说在卷积类型、操作类型、I/O的时间消耗等,他可以进一步优化模型结构。大家知道要得到一个好的模型,其实有两个维度,一个是通过人工设计的方式去设计深度学习的基础模块,比如说我的团队提出的1×1卷积。
另一个是把一些优化和消耗的元素引入到系统里面,用NAS的方式去搜索适合各种芯片的高效的深度学习模型。比如说1/8卷积,基于这个思想,把特征层变成异构化,既有大尺寸,也有小尺寸,相应的设计不同特定类型的卷积操作,最后得到的卷积也是异构的。通过这种方式,把模型的尺寸变小,但不会影响应用。因为模型变小,它的推广性能将会提升,在训练的时候消耗的计算资源也会降低。这个模型在不同的硬件上测试,基本上都能实现标准的加速。
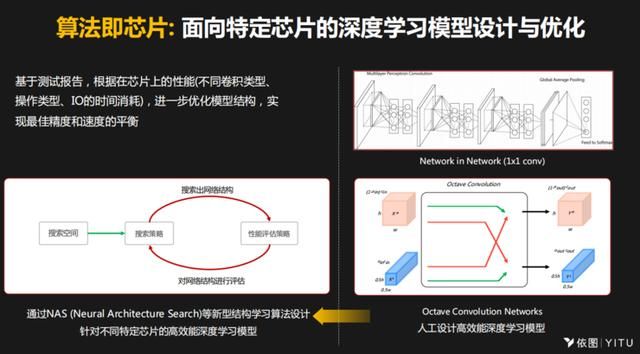
类似于这种技术模块,当我们加入到NAS 搜索空间里面,再把芯片本身的效率元素加入到NAS里面来,这样我们就可以提高模型的效率。
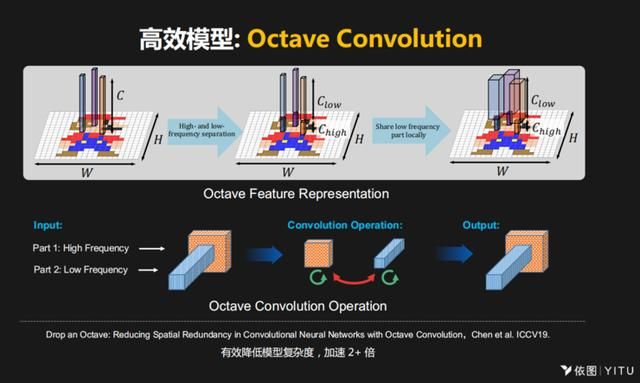
根据很多模型测试的结果,芯片设计者就都知道当前的算法以及未来发展的方向,可以对他们下一代芯片和工具链进行相应的优化。每年都会有新的深度学习的模型和想法出来,这些模型有非常好的理论加速,但在当前的芯片上往往没有办法直接实现出来——如果我们有一个社区,让算法开发者和芯片开发者多沟通、多交流,就可以更早地让这些芯片设计者把这些未来发展的趋势考虑进来,让实际的加速尽可能接近理论加速。

我在2017年做了一个More is Less结构。它的思想是,现在的深度学习卷积完成后,有40%的ReLU输出为零,这样ReLU具体值的大小是没有意义的,于是我们想有没有办法用极少的计算定位出问题。于是我们就为每一个卷积操作设计了一个配套的低功耗的卷积操作,这样在理论上这个模型精度是没有任何损失的,但是它的计算速度会大大提升。
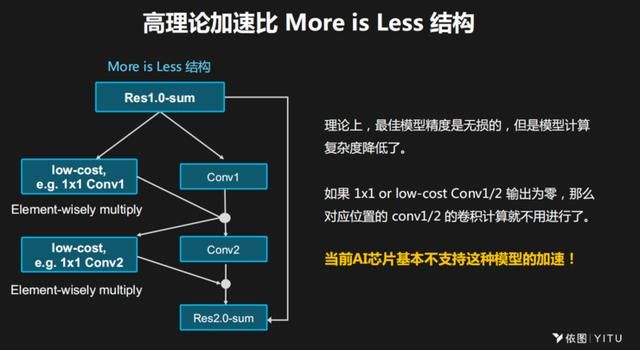
当前基本上所有AI的芯片都不支持这种架构。如果我们通过开放平台让算法开发者和芯片开发者更早地接触、更早地交流,或者说用一个经典的模型去做测试,做一个未来有价值的模型的驱动,芯片的设计将会更加有价值。这个成果对于推动整个AI领域的发展非常重要,它体现了芯片和AI算法两者相互融合的发展过程。
最后我做一个简短的总结,AI的使能和爆发都非常依赖基础设施,作为主力军的视觉计算更是如此。依图提出了“算法即芯片”的思想,是视觉计算的核心驱动力。当我们要做一款AI芯片,首先要想清楚它的典型的应用场景,同时我们在芯片设计和未来的最前沿AI算法的发展趋势有一个预判,这样让算法和芯片设计能够相互优化,协同开发,同时又实现分层解耦。
依图所承建的视觉计算国家新一代人工智能开放创新平台,将为视觉计算开发者提供更加标准和高效的支持与服务,提升智能芯片、智能算法和智能产品的整体产业能力,打造开放创新融合的生态,对于推动整个人工智能的发展将会非常有价值。