redis的一些优化点总结
记录一下自己遇到或者学习到的一些redis性能问题以及解决方式(持续更新)
一. 备份
(1)推荐备份方式:主节点开启 AOF ,从节点开启 AOF + RDB
bgsave(RDB) 做镜像全量持久化,AOF 做增量持久化。因为 bgsave 会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要 AOF 来配合使用。在 Redis 实例重启时,会使用 bgsave 持久化文件重新构建内存,再使用 AOF 重放近期的操作指令来实现完整恢复重启之前的状态。
主节点不需要开启RDB的原因是:RDB 是通过 fork 子进程来协助完成数据持久化工作的,这个fork操作会阻塞主线程。因此,如果当数据集较大时,redis节点的服务会暂停。fork子进程的时间可以通过info stats命令查看。
info stats
# Stats
total_connections_received:212773384
total_commands_processed:553178614
instantaneous_ops_per_sec:6
total_net_input_bytes:37723001227
total_net_output_bytes:101881501790
instantaneous_input_kbps:0.38
instantaneous_output_kbps:2.83
rejected_connections:0
sync_full:2
sync_partial_ok:0
sync_partial_err:0
expired_keys:33758214
evicted_keys:0
keyspace_hits:97804505
keyspace_misses:67911494
pubsub_channels:1
pubsub_patterns:0
**latest_fork_usec:175367**
migrate_cached_sockets:0
(2)如果redis绑定了CPU,那么fork的子进程和父进程公用一个cpu,这时候子进程的持久化操作就会影响到主进程的读写操作了,所以最好不要绑定cpu。
(3)主节点重写AOF文件的时候,也会占用CPU和内存资源,导致机器负载过高,所以,不应该在一个节点上面使用过多的内存,可以考虑集群方案。或者主节点不做任何持久化操作。
(4)一主多从的时候,最好不要多个从都向主同步数据,这样会导致主节点负载过高。可以考虑使用master->slave1->slave2…这样的方式
(5)写时复制技术也有一些要注意的地方,和TransparentHugePage有关。
二. 大量的key过期
大量的key同时失效会导致缓存穿透的同时,也会导致redis节点CPU突然升高。
解决方案是尽量让过期时间分散一些,然后调整hz参数。
#hz默认设为10,提高它的值将会占用更多的cpu,当然相应的redis将会更快的处理同时到期的许多key,以及更精确的去处理超时。取值范围是1~500,通常不建议超过100(Redis 作者建议),只有在请求延时非常低的情况下可以将值提升到100。
hz 10
hz参数代表定期的频率,代表了一秒钟内,后台任务期望被调用的次数。Redis 3.0.0 中的默认值是 10 ,代表每秒钟调用 10 次后台任务。hz 调大将会提高 Redis 主动淘汰的频率,如果你的 Redis 存储中包含很多冷数据占用内存过大的话,可以考虑将这个值调大 。我们实际线上将这个值调大到 100 ,观察到 CPU 会增加 2% 左右,通过观察 keyspace 个数和 used_memory 大小,对冷数据的内存释放速度确实有明显的提高。
三.redis存储结构上面的探究
先说下redisObject,这是redis存储对象定义的结构体,包括
type 类型
encoding 内部编码类型
LRU记时时钟
refcount 引用计数器
*ptr 数据指针
先记下type和encoding对应关系
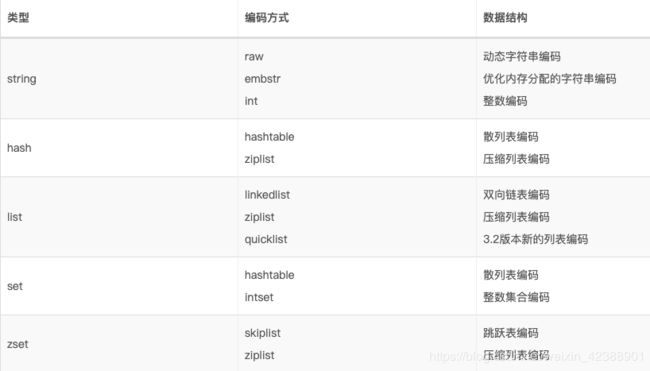
(1)短结构
在list、hash、zset这样的集合在元素较少的时候,使用的数据结构是ziplist,压缩列表。而正常情况redis使用双向链表linkedlist或者quicklist表示list、hashtable表示hash、使用散列表+skiplist表示zset。ziplist使用序列化压缩存储数据,是连续的存储,每次读写都需要重新编码,并且新增/减少数据的时候还会移动,有点像数组的方式。这样的方式更节省内存(表示链表连指针都没有),只用两个长度值(前一个节点的长度和当前节点的长度)和被存储一个字符串表示。
ziplist总结起来就是:
- 内部表现为数据紧凑排列的一块连续内存数组。
- 可以模拟双向链表结构,以O(1)时间复杂度入队和出队。
- 新增删除操作涉及内存重新分配或释放,加大了操作的复杂性。
- 读写操作涉及复杂的指针移动,最坏时间复杂度为O(n2)。
- 适合存储小对象和长度有限的数据。
这样的方式会减少内存占用,但是带来的编解码也会消耗时间,如果集合里的元素非常多的话,这样是得不偿失的。因此,可以通过配置来权衡这个问题。
entries代表元素个数,value表示节点值大小小于多少字节会采用ziplist
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2 表示最大压缩空间或长度,最大空间使用[-5-1]范围配置,默认-2表示8KB,正整数表示最大压缩长度
list-compress-depth 0 表示最大压缩深度,默认=0不压缩
list-max-ziplist-entries 512
list-max-ziplist-value 64
#如果set里面全是数字的话,多少个元素以下使用ziplist
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
ziplist的长度最好限制在500-2000内,每个元素在128byte以下,那么短结构就能起到一个不错的效果,适合存储小对象。备注:redis只能从短结构向正常结构转变,不能反向转变。
(2)hash分片存储
计算出键的CRC32校验和,是一个整数。然后跟元素总数进行hash运算,算出分片位置,获取值。结合上面说的ziplist,本来元素数量超过ziplist调优值的集合,通过分散到不同的分片,就能够继续使用短结构存储,节省存储空间。
(3)序列化方式
通常会把对象序列化成二进制存进redis,java内置的java-build-in-serializer性能不太行,可以考虑使用protostuff,kryo,henssian、Jackson,速度和压缩比上面都还可以。
(4)共享对象池
Redis内部维护[0-9999]的整数对象池。创建大量的整数类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚至超过了整数自身空间消耗。所以Redis内存维护一个整数对象池,节约内存。
共享对象池会影响到淘汰策略,因为多个引用共享一个redisobject的同时,lru计时器也会被共享,导致无法获取每个对象的最后访问时间,设置maxmemory+LRU策略的话,共享对象池将会失效。备注:ziplist无法使用对象池,因为需要编码,对象共享判断成本过高。
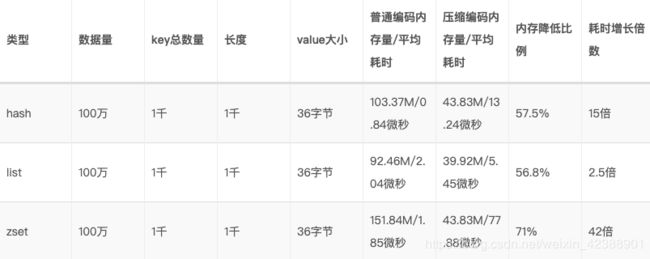
记下ziplist在集合中应用时,内存和速度(info Commandstats命令)的对比。可见ziplist可以极大降低内存占用,但是会增加耗时,需要做权衡。(参考了redis开发与运维一书)