浏览迷是一个国内比较优秀的浏览器交流网站,每当有浏览器资讯的时候,总是能引起不少读者在评论区发表自己的看法,每篇文章普遍上千阅读量,不少人都喜欢到浏览迷进行浏览器内核检测,总之这是一个不错的社区,评论区的小尾巴,能反应国内用户的普遍浏览器使用情况,本篇就从数据抓取到数据清洗,然后数据分析,进行可视化,整个流程中涉及到的Codes和思路作一个详细的记录。
数据获取分析:
首先在浏览迷网站首页发现站点是一个有名的CMS:Wordpress,怎么根据站点的特征发现网站的技术栈这里推荐一个chrome插件:BuiltWith Technology Profiler,有一些老司机写爬虫多了,看一眼就能明显判断出来。既然是WP站,至少我们不用担心内容写到js中,各种抓包分析了,爬WP站相对还是简单一些的。
然后我们进入第一篇文章,评论区还是相当热闹的,打开控制台,审查元素,我们要的信息(浏览器,操作系统)都清清楚楚的在这了。
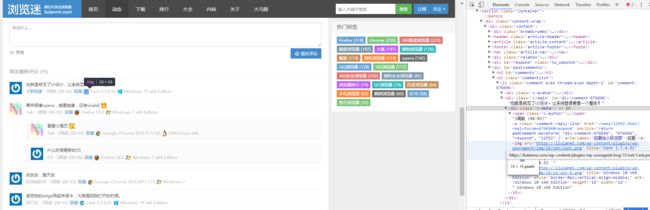
为了数据清洗比较方便,还是把浏览器信息和操作系统信息分开爬比较适当,先看浏览器信息,

在img标签中的title和alt属性中都有标注,就决定爬title中的信息,用pyquery一句搞定
[b.find("img").eq(0).attr("title") for b in pq(url=url)(".c-meta").items()]
但是还有一个问题,有的文章评论数量多,涉及到翻页加载评论,

针对这种情况,我们可以先尝试获取下面翻页的数字
try:
numend=doc2(".pagenav").text()[-1]
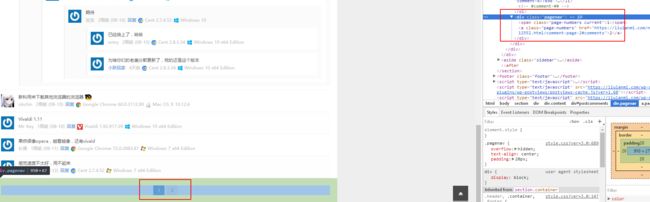
观察多数文章都是评论过两页的,所以,我们就默认评论是多页的,如果不是会抛出IndexError,然后再针对单页评论的文章进行抓取。
总体思路如下:
获取所有文章链接,保存到内存中或者写入文件,然后针对每篇文章进行评论区的浏览器类型和操作系统类型进行数据爬取,最后将操作系统型号和浏览器型号分开保存。
流程图:

数据获取,得到paperURL:
爬所有文章链接的代码如下:
import requests
import time
from pyquery import PyQuery as pq
from tqdm import tqdm#显示进度
fob=open("allurl.txt","w+",encoding="utf-8")#手动打开文件对象
urllist=[]#存储paperURL
def getallurl(pageurl):
doc=pq(s.get(pageurl).text)
for i in doc(".thumbnail").items():
urllist.append(i.attr("href"))
star=time.time()#计时
pbar=tqdm(total=240)
#每一页的URL,没在文章中分析,构成很简单。基础URL+数字
for n in range(1,241):
singpageurl="https://liulanmi.com/page/"+str(n)
getallurl(singpageurl)
pbar.update(1)
time.sleep(1)#避免频繁增加站点负担
#写入文件
for writeln in urllist:
fob.write(writeln+"\n")
fob.close()#手动关闭
pbar.close()
print (time.time()-star)#显示时间
因为整体数量不多,所以直接就是单线程顺序执行,几分钟就OK了。
数据获取,得到需要的信息:
因为有了文章统一资源定位器,所以接下来把前面分析的获取浏览器信息用python实现:
import requests
import time,os
from pyquery import PyQuery as pq
import gevent,gevent.monkey
gevent.monkey.patch_socket()
browserlist=[];oslist=[]
s=requests.Session()
def GetBrowserAndOS(paperurl):
content=s.get(paperurl).text
doc2=pq(content)
try:
numend=doc2(".pagenav").text()[-1]
sayurllist=[paperurl+"/comment-page-"+str(numm)+"#comments" for numm in range(1,int(numend)+1)]#构造的多页评论链接
for more in sayurllist:
contents=s.get(more).text
doc3=pq(contents)
for b in doc3(".c-meta").items():
browserlist.append(b.find("img").eq(0).attr("title"))
oslist.append(b.find("img").eq(1).attr("title"))
except IndexError:
for singe in doc2(".c-meta").items():
browserlist.append(singe.find("img").eq(0).attr("title"))
oslist.append(singe.find("img").eq(1).attr("title"))
def readfileurl():
global fileurl;fileurl=[]
with open("allurl.txt","r+") as fob2:
for f in fob2.readlines():
fileurl.append(f.strip())
def geventrun(s,n):
global taske
taske=[gevent.spawn(GetBrowserAndOS,u1) for u1 in fileurl[s:n]]
def geventallrun(taske):
gevent.joinall(taske)
def writefile(filename,infolist):
filenamefob=open(filename,"w+")
for info in infolist:
filenamefob.write("{name}\n".format(name=info))
filenamefob.close()
star=time.time()
readfileurl()
geventrun(0:1000);geventallrun(taske);time.sleep(10)
geventrun(1000:2000);geventallrun(taske);time.sleep(10)
geventrun(2000:-1);geventallrun(task);time.sleep(10)
writefile("OS.txt",oslist)
writefile("Browser.txt",browserlist)
print (time.time()-star)
使用了单线程协程爬取,用时大概16分钟
保存数据后的文件内容:

数据清洗
因为第一次是把浏览器信息和操作系统信息放在了一个文件,所以要用正则,进行数据清洗分割,这一次把浏览器信息和操作系统信息分开了,所以用不着该步骤
数据分析
TOP 20统计
python标准库collections模块中的Counter可以很方便的对列表中某个成员的出现次数进行统计
def readfile(filename,infolist):
with open(filename,"r+",encoding="utf-8") as fob:
for line in fob.readlines():
infolist.append(line.strip("\n"))
Browserlist=[];OSlist=[]
readfile("BrowserInfo.txt",Browserlist)
readfile("OSInfo.txt",OSlist)
from collections import Counter
top20browser=Counter(Browserlist).most_common(20)
top20os=Counter(OSlist).most_common(20)
print (top20browser)
print (top20os)
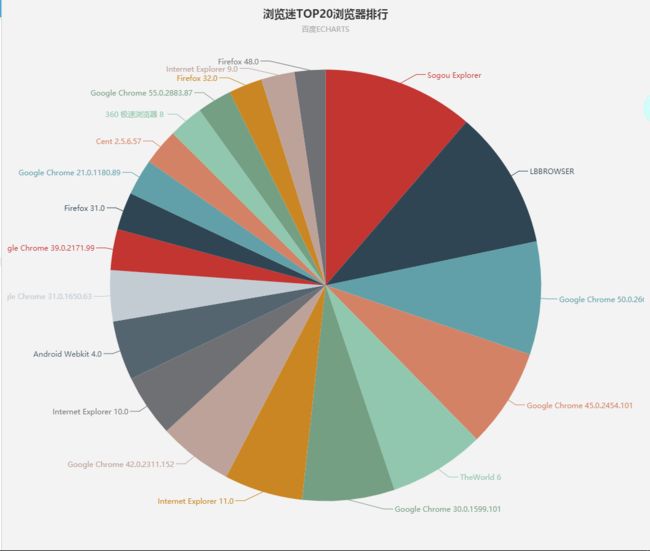
结果:

很出乎意料,搜狗浏览器排第一,chrome的版本比较多,世界之窗6竟然是前5,前20没有QQ浏览器的什么事。
用百度ECHARTS画个饼图,直观的感受一下:
javascript代码如下:
option = {
title : {
text: '浏览迷TOP20浏览器排行',
subtext: '百度ECHARTS',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a}
{b} : {c} ({d}%)"
},
legend: {
orient: 'vertical',
left: 'left',
//直接注释掉了,占空间data: ['‘]
},
series : [
{
name: '浏览器TOP20',
type: 'pie',
radius : '80%',
center: ['50%', '52%'],
data:[
{value:803, name:'Sogou Explorer'},
{value:738, name:'LBBROWSER '},
{value:601, name:'Google Chrome 50.0.2661.102'},
{value:528, name:'Google Chrome 45.0.2454.101'},
{value:510, name:'TheWorld 6 '},
{value:491, name:'Google Chrome 30.0.1599.101'},
{value:417, name:'Internet Explorer 11.0'},
{value:396, name:'Google Chrome 42.0.2311.152'},
{value:331, name:'Internet Explorer 10.0'},
{value:315, name:'Android Webkit 4.0'},
{value:271, name:'Google Chrome 31.0.1650.63'},
{value:217, name:'Google Chrome 39.0.2171.99'},
{value:200, name:'Firefox 31.0'},
{value:193, name:'Google Chrome 21.0.1180.89'},
{value:193, name:'Cent 2.5.6.57'},
{value:186, name:'360 极速浏览器 8 '},
{value:184, name:'Google Chrome 55.0.2883.87'},
{value:179, name:'Firefox 32.0'},
{value:177, name:'Internet Explorer 9.0'},
{value:164, name:'Firefox 48.0'}
],
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.6)'
}
}
}
]
};
操作系统方面统计
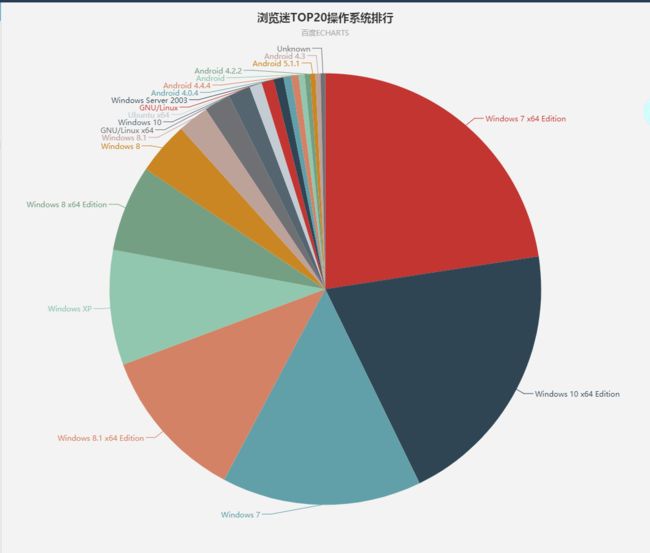
javascript代码如下:
option = {
title : {
text: '浏览迷TOP20操作系统排行',
subtext: '百度ECHARTS',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a}
{b} : {c} ({d}%)"
},
legend: {
orient: 'vertical',
left: 'left',
//data: []
},
series : [
{
name: '浏览迷操作系统TOP20',
type: 'pie',
radius : '80%',
center: ['50%', '52%'],
data:[
{value:6971, name:'Windows 7 x64 Edition'},
{value:6252, name:'Windows 10 x64 Edition'},
{value:4624, name:'Windows 7'},
{value:3565, name:'Windows 8.1 x64 Edition'},
{value:2661, name:'Windows XP'},
{value:1994, name:'Windows 8 x64 Edition'},
{value:1228, name:'Windows 8'},
{value:715, name:'Windows 8.1'},
{value:608, name:'GNU/Linux x64'},
{value:515, name:'Windows 10'},
{value:288, name:'Ubuntu x64'},
{value:283, name:'GNU/Linux'},
{value:227, name:'Windows Server 2003'},
{value:176, name:'Android 4.0.4'},
{value:174, name:'Android 4.4.4'},
{value:140, name:'Android'},
{value:125, name:'Android 4.2.2'},
{value:120, name:'Android 5.1.1'},
{value:119, name:'Android 4.3'},
{value:108, name:'Unknown'},
],
itemStyle: {
emphasis: {
shadowBlur: 10,
shadowOffsetX: 0,
shadowColor: 'rgba(0, 0, 0, 0.6)'
}
}
}
]
};
二次分析
感觉上面中的浏览器分析有些偏差,所以,用正则再次对Browser.txt中的数据清洗,把版本号都去掉,然后再次统计,\s\d{1,}\..{1,}很简单的几个字符,想了将近20分钟,个人正则不好,浪费了太多时间。
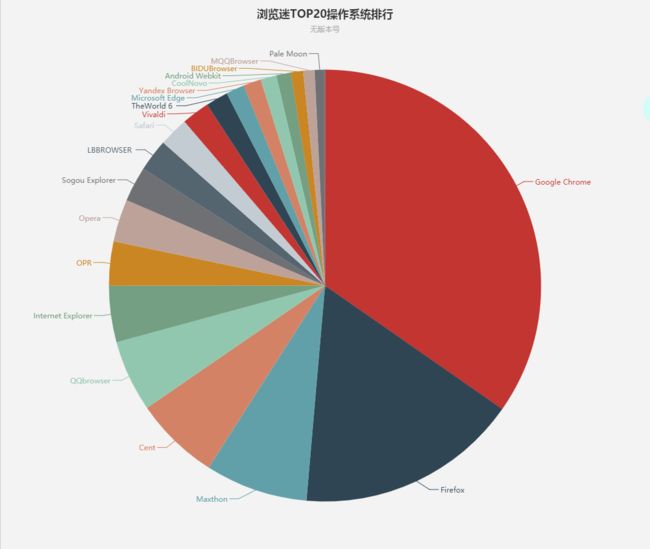
前20没有360,然后数据中把前30排出来,发现360在第21位,而且还是360极速浏览器和360se的总数。360极速浏览器曾经在浏览迷比较受欢迎,但是有一段时间360似乎放弃了极速版本,总是不更新。而且随着QQ推出了极速版本,用户都慢慢的离开了360极速,去Cent的最多。
百度统计的结果(2015.07-2017.07)

总结
以上的统计没有区分移动端和PC端,例如:GoogleChrome不仅仅是PC的占比,还有移动版的占比,同理,Maxthon(傲游浏览器)也是移动和PC的占比总和。
浏览迷评论区整体上反应了国内的浏览器市场情况,但是,用户对个别浏览器(2345,360safe)有嫌弃的特征。对这些少数浏览器,没有办法更好的分析。
而且数据是2011.11-2017.08 6年的分布情况,有时间应该把最近1到2年的数据单独分析。