Protobuf介绍及简单使用(下)之文件读写
目录
Bin二进制文件
写bin文件API
用例一
读bin文件API
用例二
Prototxt文件
写Prototxt文件API
用例三
读Prototxt文件API
用例四
caffe中的prototxt
参考资料
在上节中主要介绍了Protobuf的数据结构定义的语法,以及如何编译proto文件,以及相关的主要读写proto文件结构中的API.至今已经知道如何定义一个proto中的数据结构,可以理解为相当与C语言中的头文件,但是最终其相应的数据结构有数据才行.上节中,知道Protobuf可以将proto中数据结构对应的具体数据写入到bin二进制文件中,但是如何读取以及写入到bin文件?这层洋葱需要继续剥掉.
Bin二进制文件
Protobuf可以将程序运行中产生的数据保持到二进制文件中,与xml相比,其生成的文件更加小,读取速度更快,Protobuf工具中提供了其读写二进制API.
写bin文件API
通过查看google protocol开发API文档中的message.h头文件,message类中提供了写bin文件API,其函数原型为:
bool |
|
参数:
std::ostream * output:为文件输出数据流
message类为其定义的数据结构的一个基类,其提供了一列的操作,将其通用接口进行了统一封装.
google官方message API接口为:
https://developers.google.cn/protocol-buffers/docs/referenc/cpp/google.protobuf.message#Message.SerializeToOstream.details
除了上述按照输出流进行写bin文件之外,还提供了其他按照文件描述符进行操作,其他API还有:
| 返回值 | 函数 |
bool |
SerializeToFileDescriptor(int file_descriptor) |
bool |
SerializePartialToFileDescriptor(int file_descriptor) |
bool |
SerializeToOstream(std::ostream * output) |
bool |
SerializePartialToOstream(std::ostream * output) |
用例一
相关用里proto数据结构,继续采用上节的Family数据结构,用例要求:向Family中添加两个成员并将最终结果写入到bin文件中,用例代码如下:
#include "family.pb.h"
#include
#include
#include
#include
using namespace std;
int main(){
GOOGLE_PROTOBUF_VERIFY_VERSION;
Family family;
Person* person;
const char * filename="test.db";
fstream output("test.db", ios::out | ios::binary);
if (!output)
{
cout<<"output file : "<< filename << " is not found."<set_age(25);
person->set_name("John");
person = family.add_person();
person->set_age(40);
person->set_name("Tony");
int size = family.person_size();
printf("size : %d \r\n", size);
for(int i = 0; i 用例中将添加的两个成员,写入到test.db二进制文件中,运行用例:

生成的test.db文件如下:

打开db文件,其内容经过加密解压之后,为一堆二进制数据:

读bin文件API
生成的bin文件不仅要求可以写文件,还要求可以读bin文件,并且能够将数据完全恢复出来,其相关API为
| 返回值 | 函数 |
| bool | ParseFromFileDescriptor(int file_descriptor) |
| bool | ParsePartialFromFileDescriptor(int file_descriptor) |
| bool | ParseFromIstream(std::istream * input) |
| bool | ParsePartialFromIstream(std::istream * input) |
不仅支持数据流操作方式,还支持文件描述符参数
用例二
该用例继续延续写bin文件用例,将其上个用例生成的bin文件中的数据,读取出来:
#include "family.pb.h"
#include
#include
#include
#include
using namespace std;
int main(){
GOOGLE_PROTOBUF_VERIFY_VERSION;
Family family;
Person* person;
const char * filename="test.db";
fstream input("test.db", ios::in | ios::binary);
if (!input)
{
cout<<"input file : "<< filename << " is not found."< 运行结果:

Protobuf其bin文件的读写相对比较简单,API中将协议中的数据封装与解析,能够极大缩短了开发时间.
Prototxt文件
在caffe中可以看到其生成的网络拓扑结构以及参数,并不是bin文件二进制形式,而是prototxt形式.该形式是ProtoBuf数据保存的另外一种形势,主要是以txt形式.最主要的功能是可视化,在需要经常修改配置用于调参情况下,可以采用这样形式,该形式组成的生成格式是与proto中的数据结构相对应.
对Prototxt文件的读写APi是在text_format.h文件中:
https://developers.google.cn/protocol-buffers/docs/reference/cpp/google.protobuf.text_format
写Prototxt文件API
写Prototxt文件API列表如下:
| 返回值 | 函数 |
| bool | Print(const Message & message, io::ZeroCopyOutputStream * output) |
| bool | PrintUnknownFields(const UnknownFieldSet & unknown_fields, io::ZeroCopyOutputStream * output) |
| bool | PrintToString(const Message & message, string * output) |
| bool | PrintUnknownFieldsToString(const UnknownFieldSet & unknown_fields, string * output) |
| bool | PrintFieldValueToString(const Message & message, const FieldDescriptor * field, int index, string * output) |
用例三
利用上述用例,将添加的两个成员写入到prototxt文件中,源码如下:
#include "family.pb.h"
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using google::protobuf::io::FileInputStream;
using google::protobuf::io::FileOutputStream;
int main(){
GOOGLE_PROTOBUF_VERIFY_VERSION;
Family family;
Person* person;
const char * filename="test.prototxt";
int fd = open(filename, O_WRONLY | O_CREAT | O_TRUNC, 0777);
FileOutputStream * output = new FileOutputStream(fd);
person = family.add_person();
person->set_age(25);
person->set_name("John");
person = family.add_person();
person->set_age(40);
person->set_name("Tony");
int size = family.person_size();
printf("size : %d \r\n", size);
for(int i = 0; i 运行结果生成的prototxt文件内容如下:
person {
age: 25
name: "John"
}
person {
age: 40
name: "Tony"
}
其文件格式类似与python中的元组,其数据字段格式如下:
变量名字:变量值
查看proto文件
syntax = "proto2";
message Person {
required int32 age = 1;
required string name = 2;
}
message Family {
repeated Person person = 1;
}
可以看到在prototxt中的字段是和proto中的字段是一一对应的,即proto文件定义数据结构格式,而prototxt定义具体的格式数据结构的每个字段的值,如果有多个相同的数据结构的值,则直接前面加上数据结构后面紧跟大括号即可
读Prototxt文件API
读取prototxt文件,并恢复文件里面的数据,相关API为:
| 返回值 | 函数 |
| bool | Parse(io::ZeroCopyInputStream * input, Message * output) |
| bool | ParseFromString(const string & input, Message * output) |
| bool | Merge(io::ZeroCopyInputStream * input, Message * output) |
| bool | MergeFromString(const string & input, Message * output) |
| bool | ParseFieldValueFromString(const string & input, const FieldDescriptor * field, Message * message) |
用例四
将上述生成的text.prototxt文件,重新读取到内存中:
#include "family.pb.h"
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
using google::protobuf::io::FileInputStream;
using google::protobuf::io::FileOutputStream;
int main(){
GOOGLE_PROTOBUF_VERIFY_VERSION;
Family family;
Person* person;
const char * filename="test.prototxt";
int fd = open(filename, O_RDONLY);
FileInputStream * input = new FileInputStream(fd);
bool success = google::protobuf::TextFormat::Parse(input, &family);
int size = family.person_size();
printf("size : %d \r\n", size);
for(int i = 0; i 运行结果:

能够成功将数据读取到内存中.
caffe中的prototxt
caffe中的prototxt文件一般用来描述整个网络,并描述出整个网络中的每层测参数,例子如下:
ame: "CaffeNet"
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 10 dim: 3 dim: 227 dim: 227 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 96
kernel_size: 11
stride: 4
}
}
上述是一个网络拓扑结构中每层的参数,其每层的参数是和caffe.proto中LayerParameter参数对应的:

比如上述第一个层,层名字为name,对应 LayerParamete中的name,其值为data,type为层的类型为Input输入层,top为输出的blob的名字为data, Input_param为一个数据结构嵌套,对应的是InputParameter
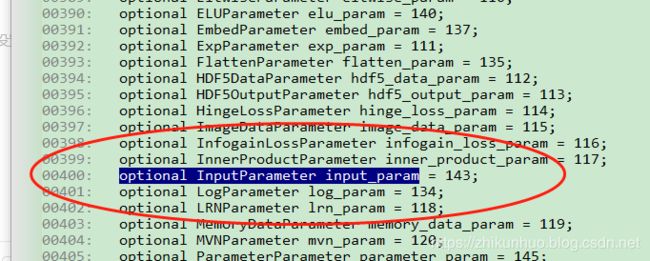
其 InputParameter数据结构如下:

该数据结构还进一步进行了嵌套,嵌套的数据类型为BlobShape,定义了Blob中的数据shape,由关键字repeated可知,在 InputParameter参数中BlobShape是可以重复设置多个repeated,可以定义多个Blob的4维数据:
最后其第一个层 data中的入参的Blobshape为dim: 10 dim: 3 dim: 227 dim: 227
依次对着caffe.proto文件,就可以读懂整个prototxt配置文件。
”授人以鱼不如授人以渔“,本篇不会讲述其prototxt文件中的整个网络结构的配置,只是教授读懂文件的方法,以为学习caffe的Net打下基础。
参考资料
https://developers.google.cn/protocol-buffers/docs/reference/cpp/google.protobuf.text_format
https://developers.google.cn/protocol-buffers/docs/reference/cpp/google.protobuf.text_format
《21天实战caffe》