ZooKeeper在Hadoop和Kafka中的应用
ZooKeeper被越来越广泛地应用在大型分布式系统中,比如Hadoop、HBase和Kafka等。以下主要介绍一个ZooKeeper在Hadoop和Kafka中的应用。
一、Hadoop
1、ZooKeeper在Hadoop是什么作用?
在Hadoop中,ZooKeeper主要用于实现HA(High Availability),这部分逻辑主要集中在Hadoop Common的HA模块中,HDFS的NameNode与YARN的ResourceManager都是基于此HA模块来实现自己的HA功能的。
2、YARN是什么?为什么要在YARN中使用ZooKeeper?
YARN是Hadoop为了提高计算节点Master(JT)的扩展性,同时为了支持计算模型和提供资源的细粒度调度而引入的全新一代分布式调度框架。YARN主要由ResourceManager(RM)、NodeManager(NM)、ApplicationMaster(AM)和Container四部分组成。其中最为核心的就是ResourceManager,它作为全局的资源管理器,负责整个系统的资源管理和分配。
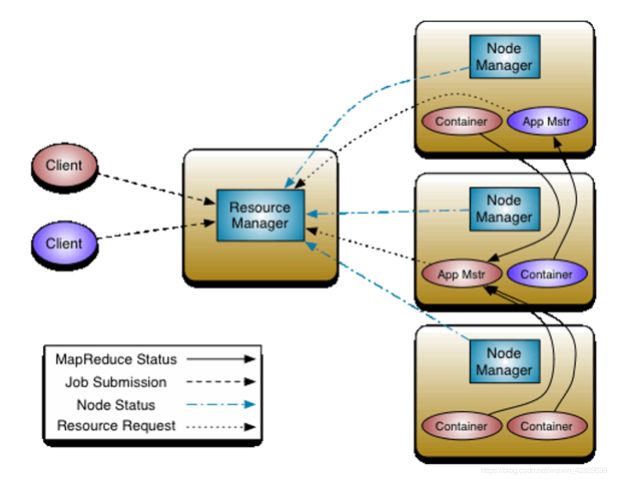
从YARN的架构体系中可以看到一个明显的缺陷:ResourceManager的单点问题。因此, Hadoop使用ResourceManager HA来解决ResourceManager的单点问题。
3、YARN中的ResourceManager是如何解决单点问题的?
ResourceManager使用基于ZooKeeper实现的ActiveStandbyElector组件来确定ResourceManager的状态:Active和Standby。具体如下:
(1)创建锁节点。成功创建的那个ResourceManager切换为Active状态,没有成功的那些ResourceManager则切换为Standby状态。
(2)注册Watcher监听。所有Standby状态的节点向锁节点注册一个节点变更的Watcher监听。
(3)主备切换。当Active状态的ResourceManager出现诸如重启或者挂掉的异常情况时,其在ZooKeeper上创建的Lock节点也会随之倍数删除。其他Standby状态的ResourceManager接收到来自ZooKeeper服务端的Watcher事件通知重复步骤1操作。
4、YARN是如何解决ResourceManager的“假死”的?
在分布式环境中,经常会出现诸如单机“假死”的情况。所谓的“假死”是指机器由于网络闪断或是其自身由于负载过高(常见的有GC占用时间过长或CPU的负载过高等)而导致无法正常地对外进行及时响应。在主备切换过程中,常会因此出现分布式的“脑裂”(Brain-Split)现象,即存在多个处于Active状态的ResourceManager各司其职。
YARN引入了Fencing机制借助ZooKeeper数据节点的ACL权限控制机制来实现不同RM之间的隔离。创建的根节点必须携带ZooKeeper的ACL信息,目的是为了独占该根节点,以防止其他RM对该节点进行更新。
二、Kafka
1、什么是Kafka?
Kafka主要用于实现低延迟的发送和收集大量的事件和日志数据——这些数据通常都是活跃的数据。这些数据通常以日志的形式记录下来,然后有一个专门的系统来进行日志的收集与统计。
2、Kafka中的主要概念
(1)消息生产者,即Producer,是消息产生的源头,负责生成消息并发送到Kafka服务器上。
(2)消息消费者,即Consumer,是消息的使用方,负责消费Kafka服务器上的消息。
(3)主题,即Topic,由用户定义并配置在Kafka服务端,用于建立生产者和消费者之前的订阅关系:生产者发送消息到指定Topic下,消费者从这个Topic下消费消息。
(4)消息分区,即Partition,一个Topic下面会分为多个分区。消息分区机制和分区的数量与消费者的负载均衡机制有很大关系。
(5)Broker,即Kafka的服务器,用于存储消息,在消息中间件中通常被称为Broker。
(6)消费者分组,即Group,用于归组同类消费者。在Kafka中,多个消费者可以共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组的名称,通常也称为消费者集群。
(7)Offset,消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文本中的偏移量,这个偏移量就是所谓的Offset。
3、Broker注册
在ZooKeeper上会有一个专门用来进行Broker服务器列表记录的节点,即“Broker节点”。每个Broker服务器在启动时,都会到ZooKeeper上进行注册,即到Broker节点下创建属于自己的节点。创建完Broker节点之后,每个Broker就会将自己的IP地址和端口号等信息写入到该节点中。
Broker创建的节点也是一个临时节点。
4、Topic注册
Broker服务器在启动后,会到对应的Topic节点下注册自己的Broker ID,并写入针对该Topic的分区总数。
分区数节点也是一个临时节点。
5、生产者如何进行负载均衡?
每当一个Broker启动时,会首先完成一个Broker注册过程,注册一些诸如“有哪些可订阅的Topic”的元数据信息。生产者就能够通过这个节点的变化来动态地感知到Broker服务器的变更。在实现上,Kafka的生产者会对ZooKeeper上的“Broker的新增与减少”、“Topic的新增与减少”和“Broker与Topic关联关系的变化”等事件注册Watcher监听,这样就可以实现一种动态的负载均衡机制了。通过ZooKeeper的Watcher通知能够让生产者动态地获取Broker和Topic的变化情况。
6、消费者如何实现负载均衡?
(1)设置PT为指定Topic所有的消息分区。
(2)设置CG为同一个消费者分组中的所有消费者。
(3)对PT进行排序,使分布在同一个Broker服务器上的分区尽量靠在一起。
(4)对CG进行排序。
(5)设置i为Ci在CG中位置的索引值,同时设置N = size(PT)/size(CG)。
(6)将编号为i × \times × N ~ (i + 1) × \times × N – 1的消息分区分配给消费者Ci。
(7)重新更新ZooKeeper上消息分区与消费者Ci的关系。