R语言主成分分析法笔记
01、什么是主成分分析法
简要概括主成分分析法的作用:把能反映某种特征的很多指标汇总成一个指标。
举例而言,一家银行的流动性可以体现在它的现金资产占比和定期存款占比上——
银行A的现金资产占比是0.12,定期存款占比是0.37;
银行B现金资产占比是0.09,定期存款占比是0.5。
哪一家流动性更好呢?
如果我们能确定存在一个公式比如: 流动性指标 = 30%现金资产占比 + 70%定期存款占比 ,就可以衡量它们的流动性差异了。
银行A=(0.30.12+0.70.37)
银行B=(0.30.09+0.70.5)
决定各个变量应该以什么比例组合成一个新的综合指标,就是“主成分分析法”。
它的原理和推导过程并不难,有线性代数的基础是很容易看懂的。有兴趣的可以去百度一下,有很多详尽教学的。无名在这里不做赘述。
02、R语言进行数据读取
首先,因为一般需要处理的数据量巨大,手动输入程序中是不现实的。我们需要一条语句从csv文件中读取数据。
首先打开一个excel,在其中输入你的数据。第一行是表头,列一下你用了哪些变量。为了结果看的方便,无名把每个变量都命名为I1、I2以此类推。每一列对应一个变量的数据。
数据复制粘贴填好以后,左上角菜单里,点“另存为”,在另存为的“其它格式”中,选择另存为成“CSV(逗号分隔)”。另存为的路径最好不要是桌面,直接放在D盘E盘中,因为R语言对中文的支持不算好,路径中最好能不出现中文。
数据格式截图如下:
另存为成CSV文件后,在R语言中运行语句:
x <- data.frame(read.csv(“D:/PCA.csv”, head = T, sep = “,”))
“D:/PCA.csv”这个就是我放在D盘下的CSV数据文件,你们自行改成自己的文件路径就行。
用x作为存储数据的变量我就是图方便,随手打的,你们可以把变量叫别的名字。
注意点:
- 指标反映的内容需要一致。
I1是银行贷存比,I2是中国棒棒糖年产量——这是不行的!当然这个错误是不会有人犯的吧。
比较要注意的在于,比如银行贷存比,越高,银行流动性越低,而其它的指标如定期存款占比、拆出拆入资金比、现金资产占比,都是数值越高,银行流动性越高。那么,银行贷存比那一个变量列的所有数值,最好全部取倒数。保证所有变量,都是同向的,数值越高,反映的内容变化趋势也相同。
- 不可以有空值!
无名在这里被坑得很惨。因为查数据的时候总归会有一两年或者一两家机构的数据是缺失的,无名在做表格时,缺失的地方都是空着的,然后R语言分析的时候报了好多次错。检查了好久。
处理缺失值的方法,很复杂,如果是写硕博士论文一类的很有必要认真做的,可以去查查R语言“mice”包处理缺失值相关的内容。这里不做赘述。
如果你只是随便水一篇论文,可以把缺失值用平均值填写。比如A银行2003年到2018年所有的数据都有,中间就缺了一年2005年的数据,那么你就可以用其它年份的平均值先填一下。(但注意,这是不对的!对结果有影响,绝不可以写在你的论文里,也最好不要用!)
如果你既学不会处理缺失值,也不想填数据,那么唯一的处理方法就是删除,把缺失数值的那一行整体删除。如果某个变量缺失了太多数值,建议直接删除这个变量。如果你所有变量都缺失了大量数值,建议直接放弃吧,主成分分析法不适合你(这篇论文都不适合)。
03、确定数据适合主成分分析(数据检验)
啥叫检验呢,就是怕你放的几个变量是一个是关于流动性的,一个是关于棒棒糖的,完全不相关,根本不应该用主成分分析法合成一个指标。
做检验,就是你要去证明一下,我的数据做主成分分析,没问题!
检验用的R语言包叫psych。电脑里没有的话,运行如下语句安装:
install.packages("psych")
只要装一次,未来永久可用。
进行检验前,运行语句调用一下这个包:
library(psych)
开始检验。有两种检验方法。
- 第一种是bartlett球形检验。
运行语句:
cortest.bartlett(cor(x))
输出结果:
> corest.bartlett(cor(x))
$chisq
[1] 36.55689
$p.value
[1] 6.750071e-05
$df
[1] 10
看p.value,这是p值,它越小越好。只要小于0.05,说明你的数据做主成分分析法没有问题。
bartlett球形检验一般来说,只要你的数据是正正常常有关联的,都能通过,不用担心。
- 第二种是KMO检验。
输入语句:
KMO(cor(x))
结果如下:

MSA就是这个检验的统计量,overall是针对主成分分析法总体的,底下的是分别对用每个变量的数值。
越大越好。大于0.7,说明数据完美,超适合主成分分析;大于0.5,说明数据可以做主成分,但是不完美;小于0.5,说明数据不合适,别用主成分分析法了。
注:KMO检验无名觉得较难通过,它对数据的要求确实比较高。无名本来有6个变量,因为其中1个缺失值较多,本来抱着侥幸的心理觉得说不定能过,结果被拦下来了。最后不得不删除了一整个变量。缺失值对KMO的影响真的大呢。
最后随手贴个论文中怎么表明已经做过这两个检验了的写法。无名初稿的内容还没有修改。你们可以作为“如何在论文里写明这两种检验”的一个参考。
一、bartlett球形检验写法

二、KMO检验写法

04\用R语言进行主成分分析
无名觉得这反而是最简单的一块了。运行语句:
x.pr <- princomp(x, cor = TRUE)
summary(x.pr, loadings = TRUE)
输出结果如下:
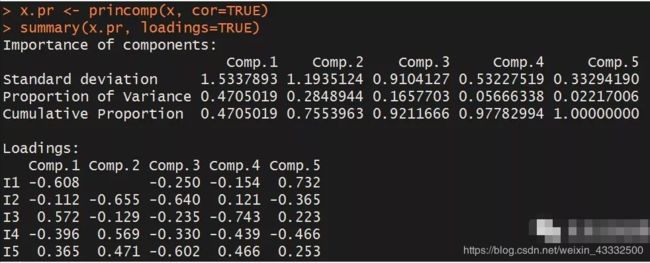
解释一下。
Comp.1是第一个主成分,向下看它这一列,1.5337893是它的标准差,没什么用;0.4705019是它本身对原本所有数据的方差的解释程度,你可以理解为,这个成分包含了原始数据中47.05019%的信息;最后一个数字还是0.4705019,因为这是累积解释度,其它成分还没和它加在一起。
Comp.2是第二个主成分,标准差不用看;0.2848944是它本身对原始数据的解释程度;0.7553963是累积解释度,就是从Comp.1到它这里所有的主成分加起来能解释原始数据的75.53963%。
以此类推。
累积解释度达到85%即为最适宜。因此,这个例子中,从Comp.1到Comp.3的累积解释度,已经达到了92.11666%,Comp.4和Comp.5可以直接扔掉,不管。
Loadings那一栏什么意思呢?
Comp.1 = -0.608 * I1 - 0.112 * I2 + 0.572 * I3 - 0.396 * I4 + 0.365 * I5
Comp.2 = -0.655 * I2 - 0.129 * I3 + 0.569 * I4 + 0.471 * I5
以此类推。
那么最终的指标,就应该是:
a * Comp.1 + b * Comp.2 + c * Comp.3
所以a、b、c的系数如何确定呢?
答案是根据方差解释度加权计算。每个主成分的方差解释度就是权重。
Comp.1对方差的解释度是0.4705019,
Comp.2对方差的解释度是0.2848944,
Comp.3对方差的解释度是0.1657703,
它们加总的累积方差解释度是,0.9211666 (0.4705019 + 0.2848944 + 0.1657703)。
因此
a = 0.4705019/0.9211666 = 0.5107674
b = 0.2848944/0.9211666 = 0.3092757
c = 0.1657703/0.9211666 = 0.1799569
系数a、b、c的值加起来应该正好是1。
最终确定的指标就应该是:
0.51 * Comp.1 + 0.31 * Comp.2 + 0.18 * Comp.3
在excel表中,用原始数据进行计算,就可以得到最终数值了。
最后再贴一下论文里的写法(再次声明这就是个初稿,数据什么的都不太对的,就是让你们参考一下,如何在论文里写明白主成分分析法)。
05、结语
全部代码如下:
x <- data.frame(read.csv("D:/***.csv", head = T, sep = ",")) #读取数据,***处填写路径
x #查看数据
install.packages("psych") #安装psych包
library(psych) #调用psych包
cortest.bartlett(cor(x)) #bartlett球形检验
KMO(cor(x)) #KMO检验
x.pr <- princomp(x, cor = TRUE) #主成分分析
summary(x.pr, loadings = TRUE) #查看主成分分析结果
eigen(cor(x)) #查看主成分分析的特征值与特征向量
其中,特征值和特征向量对于写论文来说可有可无,列在论文里也可以,本文就没有专门提出来了。
会线性代数的,去看一下原理,很容易理解特征值、特征向量的作用以及含义。
转载自微信公众号 :无名氏如是说 《R语言主成分分析法笔记》