利用selenium携带cookies实现免登录
前面爬虫系列我在介绍中谈到过Javascript进行渲染的界面,普通的请求是无法获取关键代码块的。
selenium确实是个神器,但是越来越多的网站也对selenium进行了识别和通过登录方式进行了限制,在登录方面因selenium携带cookies的方式和用requests库请求所携带的方式有很大的不同,之前走过了不少的坑,所以在此作下登录的总结。以大麦网和淘宝网为例。
1、大麦网
大麦网是一个用于演唱会购票的网站,如果想利用selenium进行抢票操作就必须进行登录。
我的思路是写两个脚本:1. selenium驱动在登录界面的时候进行手动微信扫码登录,然后获取cookies保存在本地。2. 利用selenium加载界面(此时是未登录状态),然后往浏览器从本地里添加cookies,刷新,登录成功!
1.1 脚本一 获取cookies并保存本地
from selenium import webdriver
import os
import time
import json
def browser_initial():
""""
进行浏览器初始化
"""
os.chdir('E:\\pythonwork')
browser = webdriver.Chrome()
log_url = 'https://passport.damai.cn/login?ru=https%3A%2F%2Fwww.damai.cn%2F'
return log_url,browser
def get_cookies(log_url,browser):
"""
获取cookies保存至本地
"""
browser.get(log_url)
time.sleep(15) # 进行扫码
dictCookies = browser.get_cookies() # 获取list的cookies
jsonCookies = json.dumps(dictCookies) # 转换成字符串保存
with open('damai_cookies.txt', 'w') as f:
f.write(jsonCookies)
print('cookies保存成功!')
if __name__ == "__main__":
tur = browser_initial()
get_cookies(tur[0], tur[1])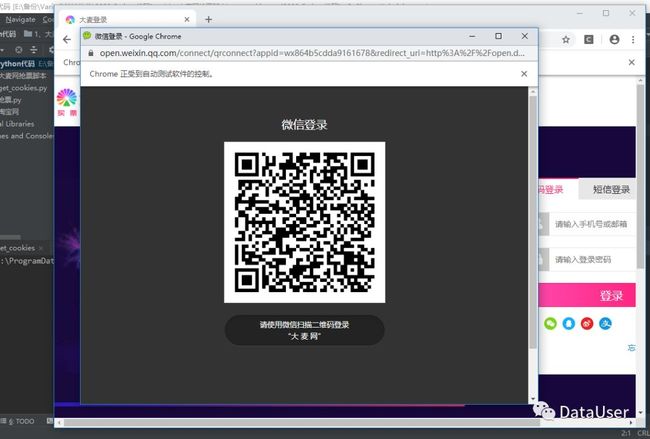 图1
图1
代码运行时会出现二维码,扫码后登录成功,程序自动保存cookies至本地。
 图2
图2
1.2 脚本二 加载本地的cookies访问网页
from selenium import webdriver
import os
import json
def browser_initial():
""""
浏览器初始化,并打开大麦网购票界面(未登录状态)
"""
os.chdir('E:\\pythonwork')
browser = webdriver.Chrome()
browser.get('https://detail.damai.cn/item.htm?spm=a2oeg.search_category.0.0.8778f91as7xLdc&id=610870234751&clicktitle=2020%E5%BC%A0%E6%9D%B0%E3%80%8C%E6%9C%AA%C2%B7LIVE%E3%80%8D%E5%B7%A1%E5%9B%9E%E6%BC%94%E5%94%B1%E4%BC%9A%20%E5%90%88%E8%82%A5%E7%AB%99')
return browser
def log_damai(browser):
"""
从本地读取cookies并刷新页面,成为已登录状态
"""
with open('damai_cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
# 往browser里添加cookies
for cookie in listCookies:
cookie_dict = {
'domain': '.damai.cn',
'name': cookie.get('name'),
'value': cookie.get('value'),
"expires": '',
'path': '/',
'httpOnly': False,
'HostOnly': False,
'Secure': False
}
browser.add_cookie(cookie_dict)
browser.refresh() # 刷新网页,cookies才成功
if __name__ == "__main__":
browser = browser_initial()
log_damai(browser)结果如下图,出现的界面显示未登录,稍等几秒浏览器读取cookies后显示登录状态。
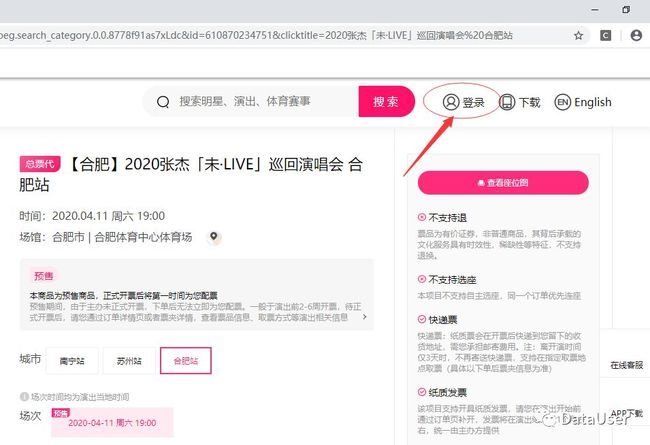 图3 未登录
图3 未登录
 图4 已登录
图4 已登录
以上代码最难的部分就是往浏览器里面添加cookies的地方,我们怎么知道要改哪些参数并设置呢?原来获取下来的cookies是以列表的形式储存的,而列表里的元素是字典,每一个字典都是一个cookies,所以我们需要遍历列表,以字典形式往浏览器添加。我遍历了一遍本地保存的cookies,如下图。
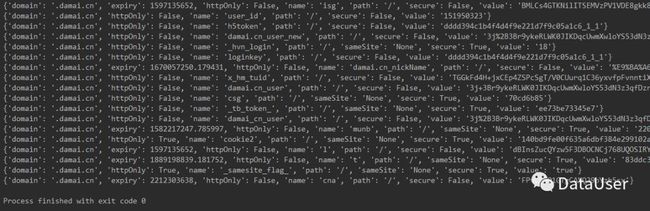 图5 cookies内容
图5 cookies内容
所以我们只需按照上表里的字段方式往浏览器里修改并添加就好啦。
2、淘宝网
淘宝网是大家爬的比较多的,但是使用过requests库请求爬的人都知道,先不说Ajax的加密,就连进行登录界面与验证码都难住了好多人。今天我试着利用selenium携带cookies方式登录成功了,操作与上面的大麦大体相似。
淘宝网的厉害之处在于能在使用账号密码方式登录时识别出你的selenium,然后拒绝你登陆。不过我尝试使用了二维码方式登录然后保存cookies再进行免登陆,成功了!
2.1 脚本一 获取cookies并保存本地
from selenium import webdriver
import os
import time
import json
def browser_initial():
""""
进行浏览器初始化
"""
os.chdir('E:\\pythonwork')
browser = webdriver.Chrome()
log_url = 'https://www.taobao.com/'
return log_url,browser
def get_cookies(log_url,browser):
"""
获取cookies保存至本地
"""
browser.get(log_url)
time.sleep(20) # 进行扫码
dictCookies = browser.get_cookies()
jsonCookies = json.dumps(dictCookies) # 转换成字符串保存
with open('taobao_cookies.txt', 'w') as f:
f.write(jsonCookies)
print('cookies保存成功!')
if __name__ == "__main__":
tur = browser_initial()
get_cookies(tur[0], tur[1])因为打开淘宝任何网页都先是登录页面,只有登录了才能访问内容,所以log_url设置淘宝的任何网页都是可以的。
2.2 脚本二 读取cookies登录目标网站
from selenium import webdriver
import os
import json
import time
def browser_initial():
""""
进行浏览器初始化
"""
os.chdir('E:\\pythonwork')
browser = webdriver.Chrome()
goal_url = 'https://s.taobao.com/search?q=%E5%8D%AB%E8%A1%A3&imgfile=&commend=all&ssid=s5-e&search_type=item&sourceId=tb.index&spm=a21bo.2017.201856-taobao-item.1&ie=utf8&initiative_id=tbindexz_20170306'
# 未携带cookies打开网页
browser.get('https://www.taobao.com/')
return goal_url,browser
def log_taobao(goal_url,browser):
"""
从本地读取cookies并登录目标网页
"""
# 从本地读取cookies
with open('taobao_cookies.txt', 'r', encoding='utf8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
cookie_dict = {
'domain': '.taobao.com',
'name': cookie.get('name'),
'value': cookie.get('value'),
'path': '/',
"expires": '',
'sameSite': 'None',
'secure': cookie.get('secure')
}
browser.add_cookie(cookie_dict)
# 更新cookies后进入目标网页
browser.get(goal_url)
if __name__ == '__main__':
tur = browser_initial()
log_taobao(tur[0],tur[1])淘宝网的代码跟大麦的大致相同,唯一不同的就是大麦网在登录页面刷新操作后就显示已登录状态了,而淘宝网刷新没用,必须新打开网页才行。所以淘宝网必须先打开一次用于登录,然后再打开目标网页。
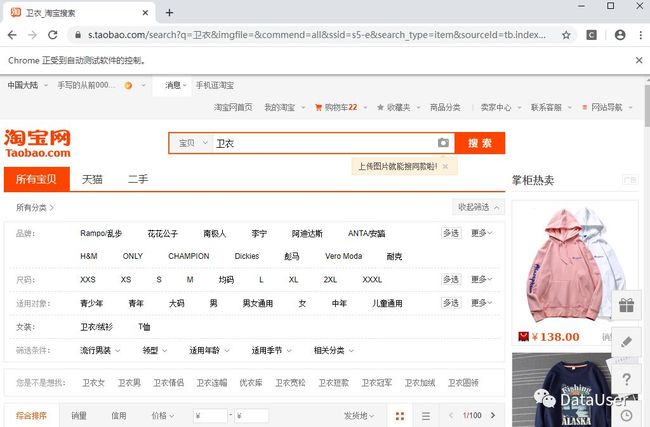 图6 登录成功
图6 登录成功
如图,登录成功。不要觉得这简单,以为直接进入目标网址就完事了,如果不进行登录操作,你打开图6页面时将会跳转图7页面并且你的selenium已经被检测到!无法进行账号密码登录。

更多原创文章请关注我的公众号:DataUser
一枚数据分析的爱好者~
