一文理解分布式服务架构下的混沌工程实践(含PPT)
导读:近日,在 GIAC(全球互联网架构大会)上,来自阿里巴巴高可用架构团队的高级开发工程师肖长军(花名穹谷)做了《分布式服务架构下的混沌工程实践》主题分享。本次分享包含三部分,第一部分从定义、价值、原则、流程全方位的介绍混沌工程,第二部分讲述混沌工程如何在企业中落地,并穿插介绍开源项目 ChaosBlade 和混沌实验平台 AHAS Chaos 架构设计,最后一部分结合两个具体案例介绍了分布式服务下的混沌工程实践。
 肖长军,花名穹谷,阿里巴巴高可用架构部门高级开发工程师,多年分布式服务、应用性能监控和混沌工程领域研发经验。ChaosBlade 开源项目负责人,阿里云产品 AHAS 核心开发,故障演练平台 MonkeyKing 核心开发。
肖长军,花名穹谷,阿里巴巴高可用架构部门高级开发工程师,多年分布式服务、应用性能监控和混沌工程领域研发经验。ChaosBlade 开源项目负责人,阿里云产品 AHAS 核心开发,故障演练平台 MonkeyKing 核心开发。
演讲全文
大家好,我是来自阿里的肖长军,今天给大家分享混沌工程在分布式服务架构下的具体实践。
 先做个自我介绍,我来自于阿里高可用架构团队,花名穹谷,做过分布式系统设计和 APM 研发相关工作,现在专注于高可用架构和混沌工程领域,是阿里云产品 AHAS 底层技术负责人和开源项目 ChaosBlade 负责人,并且承担集团内故障演练、突袭演练、攻防演练相关的研发工作。今天分享的内容包含以下三个方面。
先做个自我介绍,我来自于阿里高可用架构团队,花名穹谷,做过分布式系统设计和 APM 研发相关工作,现在专注于高可用架构和混沌工程领域,是阿里云产品 AHAS 底层技术负责人和开源项目 ChaosBlade 负责人,并且承担集团内故障演练、突袭演练、攻防演练相关的研发工作。今天分享的内容包含以下三个方面。
 先从混沌工程的定义、价值、原则和实施步骤介绍混沌工程,然后分享混沌工程如何在企业中落地,最后介绍分布式服务下混沌工程实践案例。我们先来看一下什么是混沌工程。
先从混沌工程的定义、价值、原则和实施步骤介绍混沌工程,然后分享混沌工程如何在企业中落地,最后介绍分布式服务下混沌工程实践案例。我们先来看一下什么是混沌工程。
 混沌工程理论一文中提到,其是在分布式系统上进行实验的学科,核心目的是提高生产环境中系统的容错性和可恢复性。尼采的这句话: "打不倒我的必使我强大",也很好的诠释了混沌工程反脆弱的思想。除了这里提到的目的,实施混沌工程还有哪些价值呢?
混沌工程理论一文中提到,其是在分布式系统上进行实验的学科,核心目的是提高生产环境中系统的容错性和可恢复性。尼采的这句话: "打不倒我的必使我强大",也很好的诠释了混沌工程反脆弱的思想。除了这里提到的目的,实施混沌工程还有哪些价值呢?
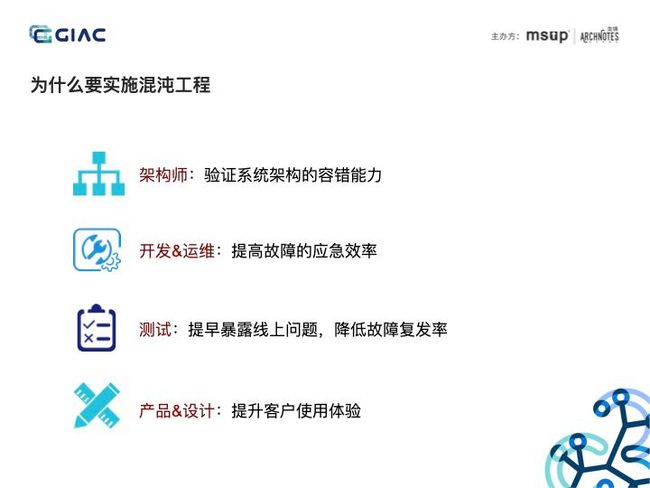 这里我从四个角色来说明,对于架构师来说,可以验证系统架构的容错能力,比如验证现在提倡的面向失败设计的系统;对于开发和运维,可以提高故障的应急效率,实现故障告警、定位、恢复的有效和高效性。对于测试来说,可以弥补传统测试方法留下的空白,之前的测试方法基本上是从用户的角度去做,而混沌工程是从系统的角度进行测试,降低故障复发率。对于产品和设计,通过混沌事件查看产品的表现,提升客户使用体验。所以说混沌工程面向的不仅仅是开发、测试,拥有最好的客户体验是每个人的目标。我们知道,系统发生故障的那一刻不是由你来选择的,而是那一刻选择你,你所能做,只能是为之做好准备。了解了混沌工程的价值,我们再来看一下实施混沌工程的一些原则。
这里我从四个角色来说明,对于架构师来说,可以验证系统架构的容错能力,比如验证现在提倡的面向失败设计的系统;对于开发和运维,可以提高故障的应急效率,实现故障告警、定位、恢复的有效和高效性。对于测试来说,可以弥补传统测试方法留下的空白,之前的测试方法基本上是从用户的角度去做,而混沌工程是从系统的角度进行测试,降低故障复发率。对于产品和设计,通过混沌事件查看产品的表现,提升客户使用体验。所以说混沌工程面向的不仅仅是开发、测试,拥有最好的客户体验是每个人的目标。我们知道,系统发生故障的那一刻不是由你来选择的,而是那一刻选择你,你所能做,只能是为之做好准备。了解了混沌工程的价值,我们再来看一下实施混沌工程的一些原则。
 前面 Vilas 老师也提到了,我这里重点来介绍一下这五项原则。第一条:”建立一个围绕稳定状态行为的假说“,其包含两个含义,一个是定义能直接反应业务服务的监控指标,需要注意的是这里的监控指标并不是系统资源指标,比如CPU、内存等,这里的监控指标是能直接衡量系统服务质量的业务监控。举个例子,一个调用延迟故障,请求的 RT 会变长,对上层交易量造成下跌的影响,那么这里交易量就可以作为一个监控指标。这条原则的另一个含义是故障触发时,对系统行为作出假设以及监控指标的预期变化。第二个指模拟生产环境中真实的或有理论依据的故障,第三个建议在生产环境中运行实验,但也不是说必须在生产环境中执行,只是实验环境越真实,混沌工程越有价值。持续的执行才能持续的降低故障复发率和提前发现故障,所以需要持续的自动化运行试验,最后一个,混沌工程很重要的一点是控制爆炸半径,也就是试验影响面,防止预期外的资损发生,后面会介绍控制爆炸半径的方式。依据这些指导原则可以更有效实施混沌工程,那么混沌工程的实施步骤是什么?
前面 Vilas 老师也提到了,我这里重点来介绍一下这五项原则。第一条:”建立一个围绕稳定状态行为的假说“,其包含两个含义,一个是定义能直接反应业务服务的监控指标,需要注意的是这里的监控指标并不是系统资源指标,比如CPU、内存等,这里的监控指标是能直接衡量系统服务质量的业务监控。举个例子,一个调用延迟故障,请求的 RT 会变长,对上层交易量造成下跌的影响,那么这里交易量就可以作为一个监控指标。这条原则的另一个含义是故障触发时,对系统行为作出假设以及监控指标的预期变化。第二个指模拟生产环境中真实的或有理论依据的故障,第三个建议在生产环境中运行实验,但也不是说必须在生产环境中执行,只是实验环境越真实,混沌工程越有价值。持续的执行才能持续的降低故障复发率和提前发现故障,所以需要持续的自动化运行试验,最后一个,混沌工程很重要的一点是控制爆炸半径,也就是试验影响面,防止预期外的资损发生,后面会介绍控制爆炸半径的方式。依据这些指导原则可以更有效实施混沌工程,那么混沌工程的实施步骤是什么?
 主要细分为这 8 步,指定试验计划,定义稳态指标,做出系统容错假设,执行实验,检查稳态指标,记录、恢复 实验,修复发现的问题,然后做持续验证。以上是对混沌工程理论相关的介绍,那么如何在企业中落地混沌工程呢?
主要细分为这 8 步,指定试验计划,定义稳态指标,做出系统容错假设,执行实验,检查稳态指标,记录、恢复 实验,修复发现的问题,然后做持续验证。以上是对混沌工程理论相关的介绍,那么如何在企业中落地混沌工程呢?
 我这里分为三个阶段,首先要坚定价值,因为你会受到来自多方面的挑战,其次引入混沌工程技术,最后在企业中推广混沌工程文化。在实施混沌工程之前,必须能说清楚混沌工程的价值,而且当受到挑战时,意志要坚定。
我这里分为三个阶段,首先要坚定价值,因为你会受到来自多方面的挑战,其次引入混沌工程技术,最后在企业中推广混沌工程文化。在实施混沌工程之前,必须能说清楚混沌工程的价值,而且当受到挑战时,意志要坚定。
 比如来自老板的挑战,”如何衡量混沌工程的价值?“,可以向老板表达出,”从故障的应急效率、故障复发率、线上故障发现数来衡量“等等。所以这些问题自己要想清楚。有了坚定的意志,就要开始落地,首先要先了解自己的系统。
比如来自老板的挑战,”如何衡量混沌工程的价值?“,可以向老板表达出,”从故障的应急效率、故障复发率、线上故障发现数来衡量“等等。所以这些问题自己要想清楚。有了坚定的意志,就要开始落地,首先要先了解自己的系统。
 这里系统成熟度分 5 个等级,也可以说是业务系统所处的阶段,列出了每个阶段适合什么故障场景。刚才也有听众问,”我的服务就是单点的,还有没有实施混沌工程的必要?“,有必要,可以实施简单的实验场景,比如 CPU 满载等,来验证监控告警,如果发现没有监控告警,就要去推动完善它,然后再推动服务多实例部署,通过混沌工程一级一级的去推动系统的演进,最终实现具有韧性的系统。根据系统成熟度了解自己系统所适合的场景,接下来就要选择一款合适的混沌实验工具。
这里系统成熟度分 5 个等级,也可以说是业务系统所处的阶段,列出了每个阶段适合什么故障场景。刚才也有听众问,”我的服务就是单点的,还有没有实施混沌工程的必要?“,有必要,可以实施简单的实验场景,比如 CPU 满载等,来验证监控告警,如果发现没有监控告警,就要去推动完善它,然后再推动服务多实例部署,通过混沌工程一级一级的去推动系统的演进,最终实现具有韧性的系统。根据系统成熟度了解自己系统所适合的场景,接下来就要选择一款合适的混沌实验工具。
 这里列举了五个维度:场景丰富度、工具类型、易用性等。可以从 awesome-chaos-engineering github 项目查找或者从 CNCF Landscpage 中查看混沌实验工具。阿里今年开源的 ChaosBlade 也已经加入到 CNCF Landscape 中,后面会对此项目做重点介绍,先来看阿里混沌工程技术的演进。
这里列举了五个维度:场景丰富度、工具类型、易用性等。可以从 awesome-chaos-engineering github 项目查找或者从 CNCF Landscpage 中查看混沌实验工具。阿里今年开源的 ChaosBlade 也已经加入到 CNCF Landscape 中,后面会对此项目做重点介绍,先来看阿里混沌工程技术的演进。
 2012 年阿里内部就上线了 EOS 项目,用于梳理分布式服务强弱依赖问题,同年进行了同城容灾的断网演练。15 年 实现异地多活,16 年内部推出故障演练平台 MonkeyKing,开始在线上环境实施混沌实验,然后 18 年输出了 ACP 专有云产品 和 AHAS 公有云产品,其中 AHAS 旨在将阿里的高可用架构经验以产品的形式对外输出,服务于外部。19 年推出 ChaosBlade 项目,将底层的故障注入能力对外开源,同年也推出混沌实验平台专有云版本 AHAS Chaos,接下来重点介绍一下 ChaosBlade 项目。
2012 年阿里内部就上线了 EOS 项目,用于梳理分布式服务强弱依赖问题,同年进行了同城容灾的断网演练。15 年 实现异地多活,16 年内部推出故障演练平台 MonkeyKing,开始在线上环境实施混沌实验,然后 18 年输出了 ACP 专有云产品 和 AHAS 公有云产品,其中 AHAS 旨在将阿里的高可用架构经验以产品的形式对外输出,服务于外部。19 年推出 ChaosBlade 项目,将底层的故障注入能力对外开源,同年也推出混沌实验平台专有云版本 AHAS Chaos,接下来重点介绍一下 ChaosBlade 项目。
 ChaosBlade 中文名混沌之刃,是一款混沌实验实施工具,支持丰富的实验场景,比如应用、容器、基础资源等。工具使用简单,扩展方便,其遵循社区提出的混沌实验模型。
ChaosBlade 中文名混沌之刃,是一款混沌实验实施工具,支持丰富的实验场景,比如应用、容器、基础资源等。工具使用简单,扩展方便,其遵循社区提出的混沌实验模型。
 该模型分四次,层层递进,很清晰的表达出对什么组件做实验,实验范围是什么,实验触发的匹配规则有哪些,执行什么实验。该模型简洁、通用,语言领域无关、易于实现。阿里集团内的 C++、NodeJS、Dart 应用以及容器平台的实验场景都基于此模型实现。此模型具有很重要的意义,依据此模型可以更精准的描述、更好的理解、更方便沉淀实验场景以及发掘更多的场景。依据此模型实现的工具更加规范、简洁,我们具体看下 ChaosBlade 基于此模型的架构设计。
该模型分四次,层层递进,很清晰的表达出对什么组件做实验,实验范围是什么,实验触发的匹配规则有哪些,执行什么实验。该模型简洁、通用,语言领域无关、易于实现。阿里集团内的 C++、NodeJS、Dart 应用以及容器平台的实验场景都基于此模型实现。此模型具有很重要的意义,依据此模型可以更精准的描述、更好的理解、更方便沉淀实验场景以及发掘更多的场景。依据此模型实现的工具更加规范、简洁,我们具体看下 ChaosBlade 基于此模型的架构设计。
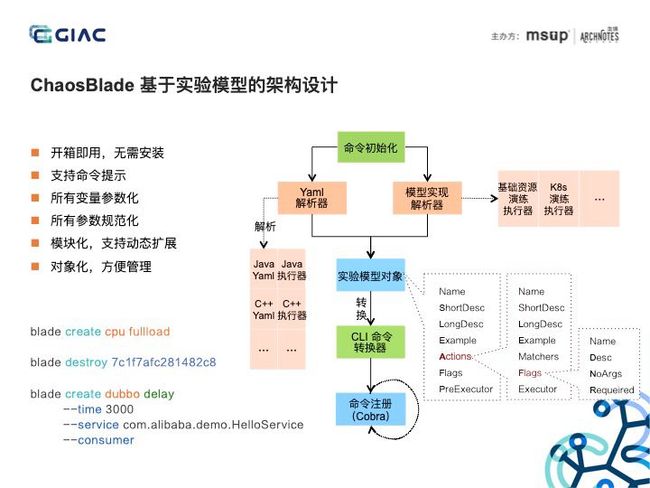 我将 ChaosBlade 的设计总结为这六点。使用 Golang 构建,实现跨平台,并且解压即用;工具使用采用 CLI 的方式,使用简单,具备完善的命令提示;遵循混沌实验模型定义场景接口,所有场景基于此接口实现,将模型转换为 cobra 框架所支持的命令参数,实现变量参数化、参数规范化,并且通过实验模型 Yaml 描述,可以很方便的实现多语言、多领域的场景扩展。而且将整个实验对象化,每个实验对象都会有个 UID,方便管理。左下角是 chaosblade 工具的使用事例,可以看出使用简洁、清晰。介绍完工具设计,我们再来谈实施混沌工程很重要的一点,如何控制爆炸半径,减小实施风险。
我将 ChaosBlade 的设计总结为这六点。使用 Golang 构建,实现跨平台,并且解压即用;工具使用采用 CLI 的方式,使用简单,具备完善的命令提示;遵循混沌实验模型定义场景接口,所有场景基于此接口实现,将模型转换为 cobra 框架所支持的命令参数,实现变量参数化、参数规范化,并且通过实验模型 Yaml 描述,可以很方便的实现多语言、多领域的场景扩展。而且将整个实验对象化,每个实验对象都会有个 UID,方便管理。左下角是 chaosblade 工具的使用事例,可以看出使用简洁、清晰。介绍完工具设计,我们再来谈实施混沌工程很重要的一点,如何控制爆炸半径,减小实施风险。
 环境越往下,实施风险越高,实验越真实,越具有价值。我们通过两种方式来控制爆炸半径,一是实验场景粒度,从 IDC 到用户,影响范围越来越低,另一个是从生产环境隔离出一部分机器,通过录制流量,对线上流量重放,进行请求打标,实现流量路由到隔离出的环境,对这些机器和请求做实验,这样可控制的爆炸半径更大。
环境越往下,实施风险越高,实验越真实,越具有价值。我们通过两种方式来控制爆炸半径,一是实验场景粒度,从 IDC 到用户,影响范围越来越低,另一个是从生产环境隔离出一部分机器,通过录制流量,对线上流量重放,进行请求打标,实现流量路由到隔离出的环境,对这些机器和请求做实验,这样可控制的爆炸半径更大。
 具备了控制爆炸半径的能力,我们可以通过平台,标准化实验流程,实现自动化执行。中间部分的图片是阿里云产品 AHAS Chaos 混沌实验平台的截图,该平台将实施混沌工程分为四个阶段。首先是准备阶段,此阶段可以定义监控指标,准备实验环境等,比如 ChaosBlade 执行 Java 应用实验,必须先执行 Prepare 操作挂载 Agent,则可放到此阶段执行。第二个阶段是执行阶段,此阶段用于执行混沌实验。第三个检查阶段,用于检查监控指标,记录问题等,第四阶段是还原阶段。此四个阶段囊括了前面提到的混沌工程实施的八个步骤,大家看到每个阶段下的每项都是一个小程序,大家可以基于规范开发自己的小程序来扩展自身实验所需要的能力,比如对接自己的业务监控,做实验前通知等。接下来看一下该平台的架构设计。
具备了控制爆炸半径的能力,我们可以通过平台,标准化实验流程,实现自动化执行。中间部分的图片是阿里云产品 AHAS Chaos 混沌实验平台的截图,该平台将实施混沌工程分为四个阶段。首先是准备阶段,此阶段可以定义监控指标,准备实验环境等,比如 ChaosBlade 执行 Java 应用实验,必须先执行 Prepare 操作挂载 Agent,则可放到此阶段执行。第二个阶段是执行阶段,此阶段用于执行混沌实验。第三个检查阶段,用于检查监控指标,记录问题等,第四阶段是还原阶段。此四个阶段囊括了前面提到的混沌工程实施的八个步骤,大家看到每个阶段下的每项都是一个小程序,大家可以基于规范开发自己的小程序来扩展自身实验所需要的能力,比如对接自己的业务监控,做实验前通知等。接下来看一下该平台的架构设计。
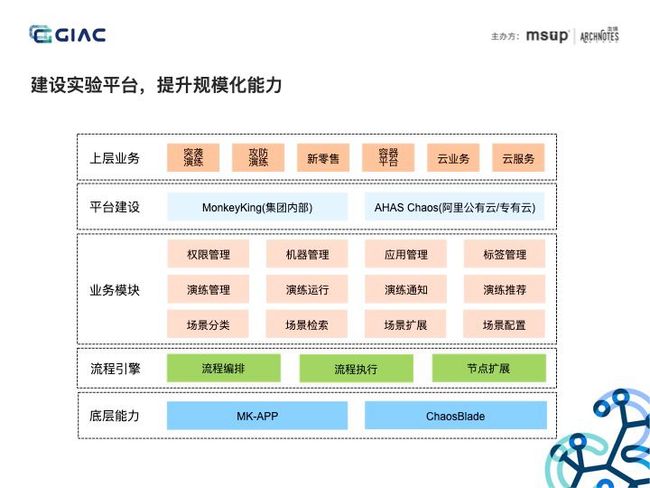 这是集团和云上混沌实验平台的架构图,通过流程引擎规范混沌工程实施步骤,对外开放平台 OpenAPI,便于上层业务建设,并且提供小程序的机制,可以对接监控平台或做一些实验前的准备操作等,将故障注入能力收敛到 ChaosBlade。基于此混沌实验平台承载了集团突袭演练、攻防演练、新零售演练等业务。此平台已经对外输出,包含公有云和专有云版本,阿里云网站搜索 AHAS 即可。具备了完善的混沌实验平台,可以在企业中推广混沌工程文化。
这是集团和云上混沌实验平台的架构图,通过流程引擎规范混沌工程实施步骤,对外开放平台 OpenAPI,便于上层业务建设,并且提供小程序的机制,可以对接监控平台或做一些实验前的准备操作等,将故障注入能力收敛到 ChaosBlade。基于此混沌实验平台承载了集团突袭演练、攻防演练、新零售演练等业务。此平台已经对外输出,包含公有云和专有云版本,阿里云网站搜索 AHAS 即可。具备了完善的混沌实验平台,可以在企业中推广混沌工程文化。 比如建立门户网站,宣传好的架构,并且推送演练红黑榜。制订攻防制度,如故障分、演练分来推动并量化演练。可以设定固定的攻防日,全企业参与,以战养战,培养混沌文化。介绍完混沌工程在企业落地的流程,我们最后分享下分布式服务下的混沌工程实践,先来看一下分布式服务所面临的问题。
比如建立门户网站,宣传好的架构,并且推送演练红黑榜。制订攻防制度,如故障分、演练分来推动并量化演练。可以设定固定的攻防日,全企业参与,以战养战,培养混沌文化。介绍完混沌工程在企业落地的流程,我们最后分享下分布式服务下的混沌工程实践,先来看一下分布式服务所面临的问题。
 系统日益庞大,服务间的依赖错综复杂,很难评估单个服务故障对整个系统的影响,并且请求链路长,监控告警不完善,导致发现问题、定位问题难度增大,同时业务和技术迭代快,如何持续保障系统的稳定性受到很大的挑战。那么一个高可用的分布式服务应该具备哪些能力呢?
系统日益庞大,服务间的依赖错综复杂,很难评估单个服务故障对整个系统的影响,并且请求链路长,监控告警不完善,导致发现问题、定位问题难度增大,同时业务和技术迭代快,如何持续保障系统的稳定性受到很大的挑战。那么一个高可用的分布式服务应该具备哪些能力呢?
 这里列举了分布式系统的高可用原则,前面的讲师伍道长提到系统的好模式和坏模式,我这里列举出的都是好模式。比如入口请求负载均衡,对异常的节点进行流量调度,通过请求限流来控制访问量,防止打垮系统,提供超时重试,当单个服务实例访问超时时,可以将请求路由到其他服务实例进行重试,梳理强弱依赖,对占用资源高的弱依赖服务进行降级,对下游出问题的服务进行熔断等等。还有系统运维方面,系统要做到可监控、可灰度、可回滚,具备弹性伸缩的能力,能快速扩容或者线下有问题的节点。这些高可用原则都可以作为混沌实验场景,从中挑选两个来讲下具体的混沌工程实践。先来看一下 Demo 拓扑图。
这里列举了分布式系统的高可用原则,前面的讲师伍道长提到系统的好模式和坏模式,我这里列举出的都是好模式。比如入口请求负载均衡,对异常的节点进行流量调度,通过请求限流来控制访问量,防止打垮系统,提供超时重试,当单个服务实例访问超时时,可以将请求路由到其他服务实例进行重试,梳理强弱依赖,对占用资源高的弱依赖服务进行降级,对下游出问题的服务进行熔断等等。还有系统运维方面,系统要做到可监控、可灰度、可回滚,具备弹性伸缩的能力,能快速扩容或者线下有问题的节点。这些高可用原则都可以作为混沌实验场景,从中挑选两个来讲下具体的混沌工程实践。先来看一下 Demo 拓扑图。
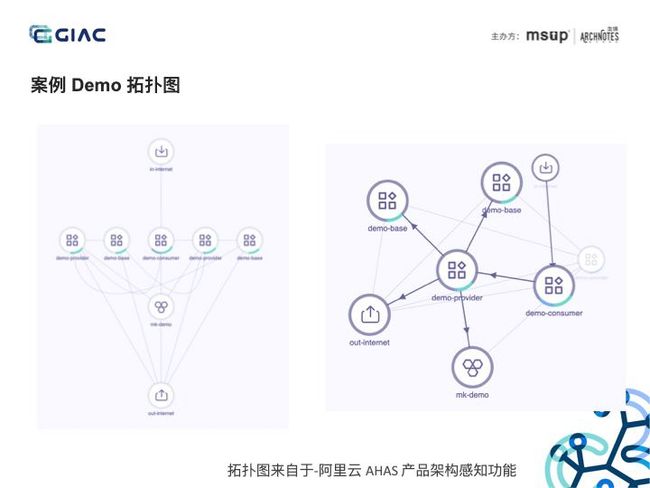 此拓扑图来自于阿里云 AHAS 产品架构感知功能,可自动感知架构拓扑,并且可以展示进程、网络、节点等数据。这个分布式服务 Demo 分三级调用,consumer 调用 provider,provider 调用 base,同时 provider 还调用 mk-demo 数据库,provider 和 base 服务具有两个实例,在 AHAS 架构拓扑图上,我们点击一个实例节点,可以到非常清晰的调用关系。我们后面结合这个 Demo 去讲解案例。
此拓扑图来自于阿里云 AHAS 产品架构感知功能,可自动感知架构拓扑,并且可以展示进程、网络、节点等数据。这个分布式服务 Demo 分三级调用,consumer 调用 provider,provider 调用 base,同时 provider 还调用 mk-demo 数据库,provider 和 base 服务具有两个实例,在 AHAS 架构拓扑图上,我们点击一个实例节点,可以到非常清晰的调用关系。我们后面结合这个 Demo 去讲解案例。

 案例一,我们验证系统的监控告警性有效性。按照前面提到的混沌工程实施步骤,那么这个案例执行的实验场景是数据库调用延迟,我们先定义监控指标:慢 SQL 数和告警信息,做出期望假设:慢 SQL 数增加,钉钉群收到慢 SQL 告警。接下来执行实验。我们直接使用 ChaosBlade 工具执行,可以看下左下角,我们对 demo-provider 注入调用 mysql 查询时,若数据库是 demo 且表名是 d_discount,则对 50% 的查询操作延迟 600 毫秒。我们使用阿里云产品 ARMS 做监控告警。大家可以看到,当执行完混沌实验后,很快钉钉群里就收到了报警。所以我们对比下之前定义的监控指标,是符合预期的。但需要注意的是这次符合预期并不代表以后也符合,所以需要通过混沌工程持续性的验证。出现慢 SQL,可通过 ARMS 的链路根据来排查定位,可以很清楚的看出哪条语句执行慢。
案例一,我们验证系统的监控告警性有效性。按照前面提到的混沌工程实施步骤,那么这个案例执行的实验场景是数据库调用延迟,我们先定义监控指标:慢 SQL 数和告警信息,做出期望假设:慢 SQL 数增加,钉钉群收到慢 SQL 告警。接下来执行实验。我们直接使用 ChaosBlade 工具执行,可以看下左下角,我们对 demo-provider 注入调用 mysql 查询时,若数据库是 demo 且表名是 d_discount,则对 50% 的查询操作延迟 600 毫秒。我们使用阿里云产品 ARMS 做监控告警。大家可以看到,当执行完混沌实验后,很快钉钉群里就收到了报警。所以我们对比下之前定义的监控指标,是符合预期的。但需要注意的是这次符合预期并不代表以后也符合,所以需要通过混沌工程持续性的验证。出现慢 SQL,可通过 ARMS 的链路根据来排查定位,可以很清楚的看出哪条语句执行慢。
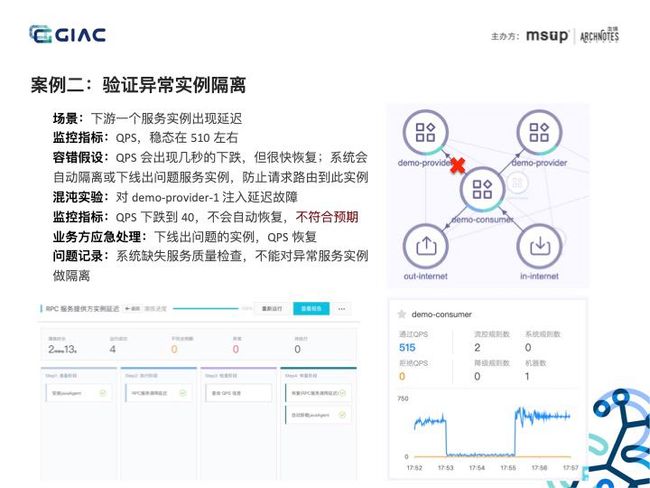 前面讲了一个符合预期的案例,我们再来看一个不符合预期的。此案例是验证系统异常实例隔离的能力,我们的 Demo 中 consumer 调用 provider 服务,provider 服务具有两个实例,我们对其中一个注入延迟故障,监控指标是 consumer 的 QPS,稳态在 510 左右。我们做的容错假设是系统会自动隔离或下线出问题的服务实例,防止请求路由的此实例,所有 QPS 会有短暂的下跌,但很快会恢复。这个案例,我们使用阿里云 AHAS 混沌实验平台来执行,我们对 demo-provider-1 注入延迟故障,基于此平台可以很方便的执行混沌实验。执行混沌实验后,QPS 下跌到 40 左右,很长时间没有自动恢复,所以不符合预期,我们通过人工的方式对该异常的实例做下线处理,很快就看到,consumer 的 QPS 恢复正常。所以我们通过混沌工程发现了系统问题,我们后面需要做就是记录此问题,并且推动修复,后续做持续性的验证。
前面讲了一个符合预期的案例,我们再来看一个不符合预期的。此案例是验证系统异常实例隔离的能力,我们的 Demo 中 consumer 调用 provider 服务,provider 服务具有两个实例,我们对其中一个注入延迟故障,监控指标是 consumer 的 QPS,稳态在 510 左右。我们做的容错假设是系统会自动隔离或下线出问题的服务实例,防止请求路由的此实例,所有 QPS 会有短暂的下跌,但很快会恢复。这个案例,我们使用阿里云 AHAS 混沌实验平台来执行,我们对 demo-provider-1 注入延迟故障,基于此平台可以很方便的执行混沌实验。执行混沌实验后,QPS 下跌到 40 左右,很长时间没有自动恢复,所以不符合预期,我们通过人工的方式对该异常的实例做下线处理,很快就看到,consumer 的 QPS 恢复正常。所以我们通过混沌工程发现了系统问题,我们后面需要做就是记录此问题,并且推动修复,后续做持续性的验证。
 我这次分享从介绍混沌工程到如何在企业中落地,并且通过具体的分布式服务的例子介绍混沌工程的实践。我们做一下回顾总结。一是混沌工程是一种主动防御的稳定性手段,体现了反脆弱的思想;二,落地混沌工程会遇到很多挑战,坚持原则不能退让;很重要的一点是实施混沌工程不能只是把故障制造出来,需要有明确的驱动目标;最后选择合适的工具和平台,控制演练风险,实现常态化演练。
我这次分享从介绍混沌工程到如何在企业中落地,并且通过具体的分布式服务的例子介绍混沌工程的实践。我们做一下回顾总结。一是混沌工程是一种主动防御的稳定性手段,体现了反脆弱的思想;二,落地混沌工程会遇到很多挑战,坚持原则不能退让;很重要的一点是实施混沌工程不能只是把故障制造出来,需要有明确的驱动目标;最后选择合适的工具和平台,控制演练风险,实现常态化演练。
 这个是部门内部部分高可用架构相关的产品图,以及对应的对外输出的阿里云产品,如包含架构感知、故障演练、限流降级的 AHAS,具备监控告警和链路跟踪的 ARMS,以及性能测试服务 PTS,欢迎大家使用。我的分享到此结束,谢谢大家。
这个是部门内部部分高可用架构相关的产品图,以及对应的对外输出的阿里云产品,如包含架构感知、故障演练、限流降级的 AHAS,具备监控告警和链路跟踪的 ARMS,以及性能测试服务 PTS,欢迎大家使用。我的分享到此结束,谢谢大家。
ChaosBlade 项目地址:https://github.com/chaosblade-io/chaosblade
参考阅读:
Service mesh时代,Dubbo架构该怎么跟进?
Java 的过去,现在与未来
从工具到社区,美图秀秀大规模性能优化实践
调研Redis高可用两种方案
一文读懂Java 11的ZGC为何如此高效
技术原创及架构实践文章,欢迎通过公众号菜单「联系我们」进行投稿。转载请注明来自高可用架构「ArchNotes」微信公众号及包含以下二维码。
高可用架构
改变互联网的构建方式

长按二维码 关注「高可用架构」公众号