优化Jenkins在云端构建性能
Jenkins在云端构建性能优化分析
- 问题背景
- NodeProvisionerStragetegy
- Jenkins Kubernates Plugin
- 优化方案
- 方案验证
问题背景
目前我们的PaaS平台使用了Jenkins对作为分布式构建调度平台,目前每天大概有5000左右的业务构建在上面运行,并且这些构建80%的执行是在高峰时段的几个小时内,执行包含单元测试,静态代码检查,打包,烘焙镜像,自动化测试以及部署等任务。为了保证构建的性能,提高构建资源的使用率,我们使用了Kubernates 对Jenkins的构建的节点Jenkins-slave进行动态管理,CI系统的整体架构如下图:

- Jenkins Master总共有5台,构建管理组件负责将流水线任务相对平均地分布在这5台机器,同时也是为了避免单点失败
- 每个Jenkins master安装了一个基于开源社区的jenkins-kubernates plugin,同时做了一些定制化的逻辑,用于在k8s集群上创建不同构建类型的jenkins-slave
- 为保证干净的Runtime环境,每个Jenkins slave只运行一个构建任务,构建结束后slave会从Master删除,同时对应的K8s pod也会回收
用户使用PaaS平台的流水线进行构建时,都希望自己的构建任务尽快地开始。由于所有的构建最终都将运行于Jenkins的工作节点:Jenkins-slave, 只有当前的Jenkins Master有可用的slave(executor)时,构建任务才会被调度到该slave上并马上执行,否则构建将呆在队列里,因此为了让用户体验到构建的零时延,不能在用户点击构建后才在K8s集群上创建一个Jenkins Slave, 因为创建流程包含了以下的流程:
- 调用K8s API 创建容器
- 启动Jenkins agent
- 通过JNLP注册该agent为Jenkin slave
这个流程至少得20-25秒,无法保证构建的实时性,因此我们在jenkins-kubernates-plugin上做了一些定制化的修改,增加Jenkins Slave Pool:
- 每个Jenkins Master预热各种类型的构建slave,比如Jdk, Node, 这样当Master有构建任务时可以直接使用,避免上面创建Slave的流程
- 每个构建结束后,需保证有足够数量的slave正在运行,即Busy slave + available slave >= Pool size, 不足时需要provision足够数量的slave
- 每个构建结束后,如果队列有任务的在等待,需要批量provision一定数量的slave (length of queue)
到此似乎可以很乐观地期望用户会很满意我们系统的构建体验,但事实是经常有用户反馈为什么我的构建一直没动静,为什么等了几分钟了还没开始。
通过分钟级的构建时延数据进行了监控,如下图,11点,13点附近都发生了类似的情况:
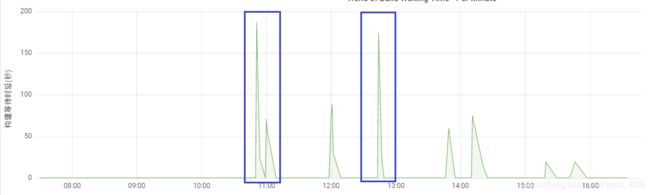
通过分析,是由于Pool里面所有的slave都处于busy状态,导致构建被queue住。只有快速拉起新的slave才会消费掉queue里面的任务, 目前Jenkins有两处地方会重新provision新的slave:
- JenkinsNodeProvisionStrategy
- Jenkins kubernates plugin
NodeProvisionerStragetegy
这个类提供了一个默认的Strategy,采用了一种“指数加权平均(EMA)“的算法,这是一种通常应用在机器学习领域算法,用于加快梯度下降算法的收敛,避免受到训练样本的抖动而带来的影响。它用这里主要是为了避免突发构建请求增多而导致拉起太多的slave,同时要保证拉起的这些slave的被用到而不会闲置。由于是滑动平均,它并不会受到构建数量抖动的影响,即不会因为构建多了而立即拉起同等数量的slave。
但目前由于PaaS的很多构建请求都发生在上班高峰时段, 以上的算法并不能保证Jenkins对构建请求及时处理,也即是说即使构建被Queue住了,默认的NodeProvisionStrategy也并不会立刻响应,从而导致了构建的等待时延。
这个算法的初衷可能是为了减少在云端构建的成本,保证slave被最大限度的使用,因为如果拉起的slave不运行构建,资源是会按分钟或者秒来计费的。
关于该算法的描述可以参考这个页面:https://support.cloudbees.com/hc/en-us/articles/115000060512-New-Shared-Agents-Clouds-are-not-being-provisioned-for-my-jobs-in-the-queue-when-I-have-agents-that-are-suspended
Jenkins Kubernates Plugin
如果slave pool没有被用完,这个策略并不会对构建产生时延,但假如所有slave都已经被job占用,依赖于该策略会导致构建被queue住。因为它必须等现在的某个构建slave终止后,才会才拉起一定数量的slave(=length of queue or pool num), 这个时延取决于当前正在执行的最快的那个构建,比如最快的构建需要3分钟来完成,则必需3分钟后才会有新的slave被创建,这个3分钟时间就是当前队列中构建的等待时延。
优化方案
基于以上分析,现在的这两种方案都会导致构建的时延(queue住较长的时间),但又各有优点:
Pros:
- NodeProvisionStrategy提供了一种扩展机制在构建等待时可以provision新的jenkins slave
- Jenkins k8s plugin可以增量地维护构建Pool的size, 使得Jenkins时刻有一定数量的slave可供调度任务,Jenkins k8s plugin在pool的数量足够,构建请求数平滑的情况下表现较好
Cons:
- NodeProvisionStrategy目前的算法无法满足我们的构建流量特点,对于构建高峰时段,无法保证构建的快速调度
- Jenkins k8s plugin在Pool都耗尽的情况下,如果有再有新的构建请求,会导致构建被queue住很长的时间(取决于最快完成的构建),因此对突发构建请求表现不足
因此我们期望新的方案可以在以下几个方面有较好的表现:
- Jenkins pool占用满后(avaiable = 0),立即创建slave容器,不需要等待现在构建结束后再拉起slave
- 预热足够数量的pool:pool使用完成后,为避免后续构建流量持续进来导致#1的再次调度,除了拉起跟当前queue同等数量的slave, 亦需要保证available的数量等于pool的数量,这样pool里面总是有空闲的slave,预热之后,新拉起的slave的数量=len of queue + num of pool。这样之后,接下来几分钟如果还有构建流量,就可以直接使用多余的空闲的slave。从统计数据看,这样基本可以保证#1情况被多次调度
- 动态维护online的slave的数量,保证至少有># of pool的slave正在运行(busy + available),避免出现slave全部被占用的情况,即避免#1情况的发生
我们计划结合现有两种方案的优点,设计新的NodeProvisioner Strategy,采用较为简单的计算方式而不是EMA,目前社区的kubernates plugin其实也是采用了一叫NoDelayProvisionStrategy(参考:https://github.com/jenkinsci/kubernetes-plugin/pull/598/commits/9e5ac6ccb02dd6cd8cf543f864e7410cd7ffc2bd),通过计算当前available/connection/planned的slave的数量,查看当前队列的长度,从而推导出需要拉起的slave的数量。
期望结果:构建的等待时延=~容器的启动时间 + connect到Jenkins master的时间, 正常情况下为20-25s
方案验证
下图是在其中一台Jenkins master上采集的数据,通过对比前后两种slave的调度算法,可以看到采用新算法后,每分钟的构建时延出现明显的下降。
- 原有算法在构建的高峰时段,经常出现很多构建的时延,范围大约为[40 - 180]秒
- 新算法构建没有出现过很大的构建时延,偶而的几个峰值也是25秒以下,是由于即刻拉起Slave时的启动时延,跟设计初衷吻合,构建响应速度提高将近8倍
- 新算法的大部分时间构建时延~0,证明通过动态维护算法+预热策略,保证一直有空闲的slave可供调度构建任务
