强化学习视频(一)
Lecture One--RL introduction
David Silver
PPT链接:http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching_files/intro_RL.pdf
视频链接:https://www.youtube.com/watch?v=2pWv7GOvuf0&index=1&list=PL5X3mDkKaJrL42i_jhE4N-p6E2Ol62Ofa
Bilibili中文字幕:https://space.bilibili.com/74997410/#/
强化学习与其它机器学习的区别:
- 没有监督,仅仅只有一个奖励信号,或者说,不直接判定某个状态或动作的好坏,而是给出一个奖励;
- 没有即时的反馈,或者说,反馈是有延迟的。在监督学习中,例如分类问题,类别判断错误与否直接与损失函数挂钩,而在RL中,比如围棋,我们当前的落子并不会直接被赋予奖励,而是整盘棋下完之后才有一个反馈(赢或输);
- 每一时刻发生的事情不是独立同分布的,每一时刻之间是有关联的。所以数据(包括Agent所观察到的信息、Agent接受到的奖励信息等)也是时序化的,数据与数据之间是有关的;
- Agent的行为将影响后续的数据,Agent每一次进行的决策都可能会进入不同的环境,处理不同的数据吗,得到不同的反馈结果。例如在下围棋时,每一步的落子将会影响棋局的走向。
RL中的决策:
- RL的目标是希望选出一系列的Actions,使最终的rewards最大。
- Planning要提前。当前的决策所产生的影响或许是一个长期的过程。
- 决策的目标要长远,不要贪心只顾及眼前的利益。
- Agent 的决策包含两个方面,一是如何处理观测信息,二是应该记住哪些信息,抛弃哪些信息。
Agent与环境:

PPT里的图和视频不太一致,这里用视频中的图。图中大脑就是就是agent,在时刻t ,agent观测到环境信息Ot后得知自己所处的状态,经过算法决定执行动作action At, 周围的环境(地球)接收到此动作At, 反馈一个奖励Rt,并更新环境的状态St。环境所处的状态对Agent而言是未知的,Agent只能感知环境输出给他的observation Ot
符号及意义
history是所有动作、状态、奖赏的序列,Ht=A1,O1,R1,…,At,Ot,Rt
environment state,Set,环境当前的状态,它反应了环境发生什么改变。这里需要明白的一点是环境自身的状态和环境反馈给agent的observation并不一定是相同的。这取决于Agent是完全可以观察(感知)到环境,还是只能观察(感知)到部分环境。例如Agent在社交网络中不可能总览全网的所有信息,这时Agent便处于一种部分可观测的环境中,也就是说Agent这时候不能够总是知道自己所处的环境是如何发生变化的。
agent state,是agent的现在所处状态的表示,它可以是history的任何函数。即状态St = f(Ht),这里的状态是Agent的状态。
information(Markov) state,它包含了history的所有有用信息。一个状态有马尔可夫性质是指下一个时刻的状态仅由当前状态决定,与过去状态无关。Agent state是有马尔可夫性质的,H 1:t ---->St ---->H t+1:无穷
对未来事情的预测取决于状态表征方法。例如下图的示例:
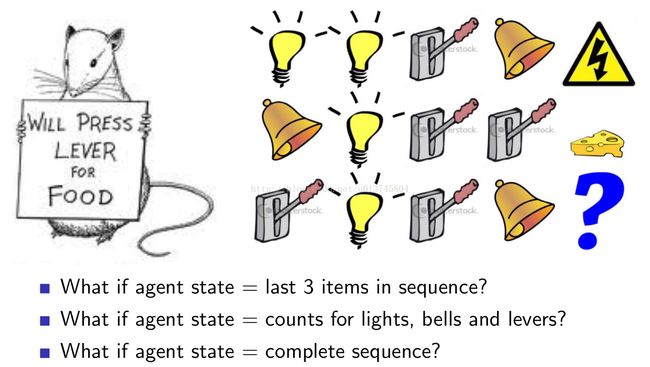
状态表述的不同,会导致预测结果的不同。
当状态表征为标签序列时,从老鼠学习到的前两次的结果,其会预测第三次的时序下会被电。
当状态表征为标签出现频次时,其会预测出第三次会吃到奶酪。
Fully Observable Environment & Partially Observable Environment
环境又分为全面观测环境和局部观测环境,全面观测环境即我们是上帝视角,可以看到整个环境的变化,比如下围棋,环境是整个棋面,我们可以完全观测到,而像人在微博环境中,即是一个部分可观察的环境。
Fully Observable Environment:
- agent能够直接看到环境当前的状态
- agent observation = agent state = environment state
- Ot = t时Agent 的状态 = t时刻环境的状态
上述公式也就是MDP的表示方式。
Partially Observable Environment:
- Agent不能够直接看到环境当前的状态
- Agent必须自己描述状态表示:
- complete history :: Sat = Ht
- 用概率向量表示,根据H中所有状态出现的概率决定
- 由RNN决定
- 上述公式是POMDP的表示方式。
RL agent的主要组成:
Policy :Agent的行为函数,状态S作为输入,行动A作为输出
Value : 用于评价Agent在某种特殊状态下的好坏,或采取某一行动之后的好坏。
Model:用于描述Agent眼中环境是如何变化的。
Policy: 是一个状态-动作的映射函数
有两种形式,一种是确定性的policy,即从历史经验中学习得到:![]() ,
,
另外一种是个随机的policy,以概率决策。概率模型:![]()
Value: 值函数,用于评估某一状态的好坏,预测未来的奖励。
![]() ,其中
,其中 是衰减因子。
是衰减因子。
Model: Agent学习环境中的行为,以预测下一刻的环境。分为两种模型:
![]() 预测下个状态,即转移概率,主要用于动态环境变化的问题。
预测下个状态,即转移概率,主要用于动态环境变化的问题。
![]() 预测下个奖励,也就是即时奖励。
预测下个奖励,也就是即时奖励。
RL agent的分类:
两种分类方式:
第一种方式 分为 Value Based Policy Based 以及Actor Critic(兼有Policy和Value Function)
第二种分类方式分为 Model Free 和 Model Based
RL中的关键问题
有关序列决策的问题分类:
RL 问题:对环境未知,Agent需要与环境不断地进行试错交互,来形成最优决策
Planning问题:已知环境信息,且已知游戏规则,Agent不需要与环境进行交互,只需要进行内部运算便可得知下一步的action,并形成最优决策
RL 中的经典问题:Exploration&Exploitation的平衡问题。
Exploration就是探索,偏向于随机,即发现环境的更多信息。例如在广告投放问题中,选择投放新的广告就是一种exploration。
Exploitation就是利用,尽可能利用已知信息来最大化累积奖励,即按学到的最优解走。选择投放点击率最高的广告来获得更大的利润就是一种exploitation。
这两个不能只顾某一方,需要平衡才是算法的最佳形式。在其他问题中,例如在一个优化问题中,我们需要兼顾多样性和集中性。
预测算法和控制算法:
预测算法:用于评估一个决策所能获得的奖励;
控制算法:用于寻找最优决策。
二者是相辅相成的存在。