SIMD指令初学
参考自:http://blog.csdn.net/gengshenghong/article/details/7008704(。。。。)
SIMD
即 single instruction multiple data,单指令流多数据流,也就是说一次运算指令可以执行多个数据流,这样在很多时候可以提高程序的运算速度。
SIMD是CPU实现DLP(Data Level Parallelism)的关键,DLP就是按照SIMD模式完成计算的。
1)SSE指令简介
SSE(为Streaming SIMD Extensions的缩写)是由 Intel公司,在1999年推出Pentium III处理器时,同时推出的新指令集。如同其名称所表示的,SSE是一种SIMD指令集。
SSE有8个128位寄存器,XMM0 ~XMM7。这些128位元的寄存器,可以用来存放四个32位的单精确度浮点数。SSE的浮点数运算指令就是使用这些寄存器。
SSE寄存器结构如下:

2)SSE浮点运算指令分类
SSE的浮点运算指令分为两大类:Packed 和Scalar。
Packed指令是一次对XMM寄存器中的四个浮点数(即DATA0 ~ DATA3)均进行计算,而Scalar则只对XMM暂存器中的DATA0进行计算。如下图所示:
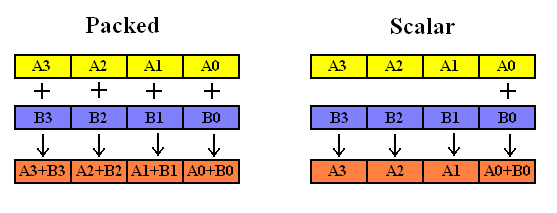
下面是SSE指令的一般格式,由三部分组成,第一部分是表示指令的作用,比如加法add等,第二部分是s或者p分别表示scalar或packed,第三部分为s,表示单精度浮点数(single precision floating point data)。

3)SSE新的数据类型
根据上面知道,SSE的寄存器是128bit的,那么SSE就需要使用128bit的数据类型,SSE使用4个浮点数(4*32bit)组合成一个新的数据类型,用于表示128bit类型,SSE指令的返回结果也是128bit的。
4)SSE定址/寻址方式
SSE 指令和一般的x86 指令很类似,基本上包括两种定址方式:寄存器-寄存器方式(reg-reg)和寄存器-内存方式(reg-mem):
addps xmm0, xmm1 ; reg-reg
addps xmm0, [ebx] ; reg-mem
5)SSE指令的内存对齐要求
SSE中大部分指令要求地址是16byte对齐的。要理解这个问题,以_mm_load_ps函数来解释,这个函数对应于loadps的SSE指令。
其原型为:extern __m128 _mm_load_ps(float const*_A);
可以看到,它的输入是一个指向float的指针,返回的就是一个__m128类型的数据,从函数的角度理解,就是把一个float数组的四个元素依次读取,返回一个组合的__m128类型的SSE数据类型,从而可以使用这个返回的结果传递给其它的SSE指令进行运算,比如加法等;从汇编的角度理解,它对应的就是读取内存中连续四个地址的float数据,将其放入SSE新的暂存器(XMM0~8)中,从而给其他的指令准备好数据进行计算。其使用示例如下:
float input[4] = { 1.0f, 2.0f, 3.0f, 4.0f };
__m128 a = _mm_load_ps(input); 6)大小端问题
这个只是使用SSE指令的时候要注意一下,我们知道,x86的little-endian特性,位址较低的byte会放在暂存器的右边。也就是说,若以上面的input为例,在载入到XMM暂存器后,暂存器中的DATA0会是1.0,而DATA1是2.0,DATA2是3.0,DATA3是4.0。如果需要以相反的顺序载入的话,可以用_mm_loadr_ps 这个intrinsic,根据需要进行选择。
7)计算机硬件支持与编译器支持
要能够使用 Intel 的 SIMD 指令集,不仅需要当前 Intel 处理器的硬件支持,还需要编译器的支持。
cat /proc/cpuinfo //查看当前处理器是否支持
可以看出支持MMX,SEE,SSE2,SSE3,SSE4_1,SSE4_2, AVX 这些指令,但不支持最新的 AVX2。
man icc //查看当前编译器是否支持8)常用的 Intrinsic 指令
在理解了最基础的指令后,可以到 Intel Intrinsic Guide 查询到所有指令。
1、 load系列,用于加载数据,从内存到暂存器。
__m128 _mm_load_ss (float *p)
__m128 _mm_load_ps (float *p)
__m128 _mm_load1_ps (float *p)
__m128 _mm_loadh_pi (__m128 a, __m64 *p)
__m128 _mm_loadl_pi (__m128 a, __m64 *p)
__m128 _mm_loadr_ps (float *p)
__m128 _mm_loadu_ps (float *p)上面是从手册查询到的load系列的函数。其中,
_mm_load_ss用于scalar的加载,所以,加载一个单精度浮点数到暂存器的低字节,其它三个字节清0,(r0 := *p, r1 := r2 := r3 := 0.0)。
_mm_load_ps用于packed的加载(下面的都是用于packed的),要求p的地址是16字节对齐,否则读取的结果会出错,(r0 := p[0], r1 := p[1], r2 := p[2], r3 := p[3])。
_mm_load1_ps表示将p地址的值,加载到暂存器的四个字节,需要多条指令完成,所以,从性能考虑,在内层循环不要使用这类指令。(r0 := r1 := r2 := r3 := *p)。
_mm_loadh_pi和_mm_loadl_pi分别用于从两个参数高底字节等组合加载。具体参考手册。
_mm_loadr_ps表示以_mm_load_ps反向的顺序加载,需要多条指令完成,当然,也要求地址是16字节对齐。(r0 := p[3], r1 := p[2], r2 := p[1], r3 := p[0])。
_mm_loadu_ps和_mm_load_ps一样的加载,但是不要求地址是16字节对齐,对应指令为movups。
2、set系列,用于加载数据,大部分需要多条指令完成,但是可能不需要16字节对齐。
__m128 _mm_set_ss (float w)
__m128 _mm_set_ps (float z, float y, float x, float w)
__m128 _mm_set1_ps (float w)
__m128 _mm_setr_ps (float z, float y, float x, float w)
__m128 _mm_setzero_ps () _mm_set_ss对应于_mm_load_ss的功能,不需要字节对齐,需要多条指令。(r0 = w, r1 = r2 = r3 = 0.0)
_mm_set_ps对应于_mm_load_ps的功能,参数是四个单独的单精度浮点数,所以也不需要字节对齐,需要多条指令。(r0=w, r1 = x, r2 = y, r3 = z,注意顺序)
_mm_set1_ps对应于_mm_load1_ps的功能,不需要字节对齐,需要多条指令。(r0 = r1 = r2 = r3 = w)
_mm_setzero_ps是清0操作,只需要一条指令。(r0 = r1 = r2 = r3 = 0.0)
3、store系列,用于将计算结果等SSE寄存器的数据保存到内存中。
void _mm_store_ss (float *p, __m128 a)
void _mm_store_ps (float *p, __m128 a)
void _mm_store1_ps (float *p, __m128 a)
void _mm_storeh_pi (__m64 *p, __m128 a)
void _mm_storel_pi (__m64 *p, __m128 a)
void _mm_storer_ps (float *p, __m128 a)
void _mm_storeu_ps (float *p, __m128 a)
void _mm_stream_ps (float *p, __m128 a) _mm_store_ss:一条指令,*p = a0
_mm_store_ps:一条指令,p[i] = a[i]。
_mm_store1_ps:多条指令,p[i] = a0。
_mm_storeh_pi,_mm_storel_pi:值保存其高位或低位。
_mm_storer_ps:反向,多条指令。
_mm_storeu_ps:一条指令,p[i] = a[i],不要求16字节对齐。
_mm_stream_ps:直接写入内存,不改变cache的数据。
4、算术指令
SSE提供了大量的浮点运算指令,包括加法、减法、乘法、除法、开方、最大值、最小值、近似求倒数、求开方的倒数等等,可见SSE指令的强大之处。那么在了解了上面的数据加载和数据保存的指令之后,使用这些算术指令就很容易了,下面以加法为例。
SSE中浮点加法的指令有:
__m128 _mm_add_ss (__m128 a, __m128 b)
__m128 _mm_add_ps (__m128 a, __m128 b) 一般而言,使用SSE指令写代码,步骤为:使用load/set函数将数据从内存加载到SSE暂存器;使用相关SSE指令完成计算等;使用store系列函数将结果从暂存器保存到内存,供后面使用。
5、其他指令
除了上面的算术指令之后,SSE还有一些其它浮点处理相关的指令,比如浮点比较、数据转换、逻辑运算等,其使用都是类似的,所以就不一一分析了。重点是要掌握load/set/store系列函数,这样才能很容易的使用其他相关运算处理指令。
6、其他指令集
了解了SSE指令集的这些函数的使用,其它指令集也就能很容易的知道如何使用了,上面提到的Intel Intrinsic Guide就包括了所有的Intel处理器的指令集的Intrinsic函数查询,包括MMX、SSE、SSE2、SSE3、SSSE3、SSE4.1、SSE4.2、AVX等。