语义分析(词义消歧,语义角色标注)
在词的层次上,语义分析的基本任务是进行词义消歧(WSD),在句子层面上是语义角色标注(SRL),在篇章层面上是指代消歧,也称共指消解。
词义消歧(WSD)
词义消歧有时也称为词义标注,其任务就是确定一个多义词在给定上下文语境中的具体含义。
词义消歧的方法也分为有监督的消歧方法和无监督的消歧方法,在有监督的消歧方法中,训练数据是已知的,即每个词的词义是被标注了的;而在无监督的消歧方法中,训练数据是未经标注的。有监督词义消歧通过建立分类器根据上下文和标注结果完成分类任务,用划分多义词上下文类别的方法来区分多义词的词义。而无监督词义消歧通常被称为聚类任务,使用聚类算法对同一个多义词的所有上下文进行等价类划分,在词义识别的时候,将该词的上下文与各个词义对应上下文的等价类进行比较,通过上下文对应的等价类来确定词的词义。
基于贝叶斯分类器的WSD
计算给定上下文语境下,取哪一个义项的可能性最高。P(当前词语所存在的上下文|某一义项)P(某一义项),是某一义项和上下文的联合分布概率,再除以分母P(当前词语所存在的上下文),计算出来的结果就是P(某一义项|当前词语所存在的上下文),就能根据上下文去求得概率最大的义项。






基于互信息的WSD
Flip-flop算法

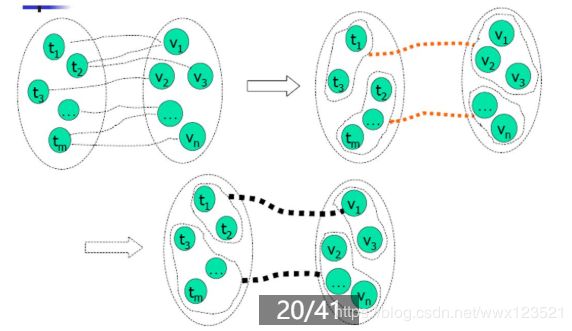
想象一下,地上有两个圈,代表两个义项;这两个圈里,分别有若干个球,代表了每个义项对应的词翻译;然后这两个圈里还有若干个方块,代表了每个义项在该语言中对应的上下文。然后球和方块之间有线连着(球与球,方块与方块之间没有),随便连接,球可以连多个方块,方块也可以连多个球。然后,圈没了,两个圈里的球和方块都混在了一起,乱七八糟的,你该怎么把属于这两个圈的球和方块分开。
Flip-Flop算法给出的方法是,试试。把方块分成两个集合,球也分成两个集合,然后看看情况怎么样,如果情况不好就继续试,找到最好的划分。然后需要解决的问题就是,怎么判定分的好不好?用互信息。如果两个上下文集(方块集)和两个词翻译集(球集)之间的互信息大,那我们就认为他们的之间相关关系大,也就与原来两个义项完美划分更接近。



基于最大熵的WSD
利用最大熵模型进行词义消歧的基本思想也是把词义消歧看做一个分类问题,即对于某个多义词根据其特定的上下文条件(用特征表示)确定该词的义项。
基于词典释义的WSD


基于义类词典的WSD


基于实例的WSD

无监督WSD
完全无监督词义消歧不可能,没有标注无法定义词义,可通过无监督方法做词义辨识。无监督词义辨识,一种贝叶斯分类器,参数估计不是基于有标注训练语料,是先随机初始化参数p(v|s),根据EM算法重新估计概率值,对w每一个上下文c计算p(c|s),得到真实数据似然值,重新估计p(v|s),重新计算似然值,不断迭代不断更新模型参数,最终得到分类模型,可对词分类,有歧义词在不同语境会被分到不同类别。
语义角色标注(SRL)
语义角色标注是一种浅层语义分析技术,它以句子为单位,不对句子所包含的予以信息进行深入分析,而只是分析句子的谓词-论元结构。具体一点讲,语义角色标注的任务就是以句子的谓词为中心,研究句子中各成分与谓词之间的关系,并且用语义角色来描述它们之间的关系。
语义角色标注依赖句法分析结果,句法分析包括短语结构分析、浅层句法分析、依存关系分析,语义角色标注,因此SRL分基于短语结构树SRL、基于浅层句法分析结果SRL、基于依存句法分析结果SRL。
其流程一般都由4个阶段组成:

候选论元剪除的目的就是要从大量的候选项中剪除掉那些不可能成为论元的项,从而减少候选项的数目。
论元辨识阶段的任务是从剪除后的候选项中识别出哪些是真正的论元。论元识别通常被作为一个二值分类问题来解决,即判断一个候选项是否是真正的论元。该阶段不需要对论元的语义角色进行标注。
论元标注阶段要为前一阶段识别出来的论元标注语义角色。论元标注通常被作为一个多值分类问题来解决,其类别集合就是所有的语义角色标签。
最终,后处理阶段的作用是对前面得到的语义角色标注结果进行处理,包括删除语义角色重复的论元等。
基于短语结构树SRL
候选论元剪除:
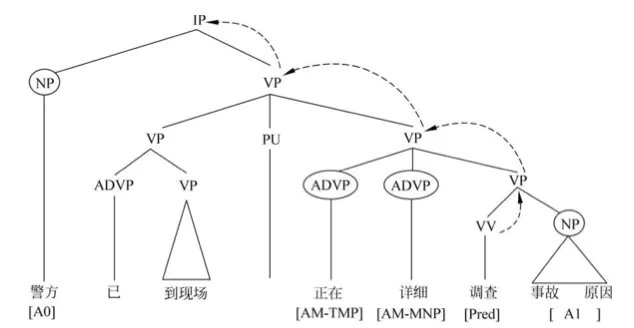
将谓词作为当前结点,依次考察它的兄弟结点:如果一个兄弟结点和当前结点在句法结构上不是并列的关系,则将它作为候选项。如果该兄弟结点的句法标签是介词短语,则将它的所有子节点都作为候选项。将当前结点的父结点设为当前结点,重复上一个步骤,直至当前结点是句法树的根结点。举个例子,候选论元就是图上画圈的:
基于依存关系树(依存句法)SRL
该语义角色标注方法是基于依存分析树进行的。由于短语结构树与依存结构树不同,所以基于二者的语义角色标注方法也有不同。在基于短语结构树的语义角色标方法中,论元被表示为连续的几个词和一个语义角色标签,比如上面图给的『事故 原因』,这两个词一起作为论元A1;而在基于依存关系树的语义角色标注方法中,一个论元被表示为一个中心词和一个语义角色标签,就比如在依存关系树中,『原因』是『事故』的中心词,那只要标注出『原因』是A1论元就可以了,也即谓词-论元关系可以表示为谓词和论元中心词之间的关系。下面给一个例子:句子上方的是原来的依存关系树,句子下方的则是谓词『调查』和它的各个论元之间的关系。

论元剪除:
将谓词作为当前结点,将当前结点的所有子结点都作为候选项,将当前结点的父结点设为当前结点,如果新当前结点是依存句法树的根结点,剪除过程结束,如果不是,执行上一步。
基于语块SRL
浅层语法分析的结果是base NP标注序列,采用的方法之一是IOB表示法,I表示base NP词中,O表示词外,B表示词首。基于语块SRL将语义角色标注作为一个序列标注问题来解决。
基于语块的语义角色标注方法一般没有论元剪除这个过程,因为O相当于已经剪除了大量非base NP,也即不可能为论元的内容。论元辨识通常也不需要了,base NP就可以认为是论元。我们需要做的就是论元标注,为所有的base NP标注好语义角色。与基于短语结构树或依存关系树的语义角色标注方法相比,基于语块的语义角色标注是一个相对简单的过程。
当然,因为没有了树形结构,只是普通序列的话,与前两种结构相比,丢失掉了一部分信息,比如从属关系等。
语义角色标注的融合方法
将多个语义角色标注系统的结果进行融合,利用不同语义角色标注结果之间的差异性和互补性,综合获得一个最好的结果。
在这种方法中,一般首先根据多个不同语义角色标注结果进行语义角色标注,得到多个语义角色标注结果,然后通过融合技术将每个语义角色标注结果中正确的部分组合起来(加权求和,插值),获得一个全部正确的语义角色标注结果。
融合方法这里简单说一种基于整数线性规划模型的语义角色标注融合方法,该方法需要被融合的系统输出每个论元的概率,其基本思想是将融合过程作为一个推断问题处理,建立一个带约束的最优化模型,优化目标一般就是让最终语义角色标注结果中所有论元的概率之和最大了,而模型的约束条件则一般来源于人们根据语言学规律和知识所总结出来的经验。