kaggle 猫狗数据集二分类 系列(2)采用数据增强再次训练
系列(1)构建模型进行二分类,保存模型,画出走势图
系列(2)采用数据增强再次训练
系列(3)采用预训练网络再次训练
系列(4)使用神经网络可视化 去看网络中间层提取的特征是什么样子
可视化卷积核 Visualizing convnet filters
可视化类激活的热力图
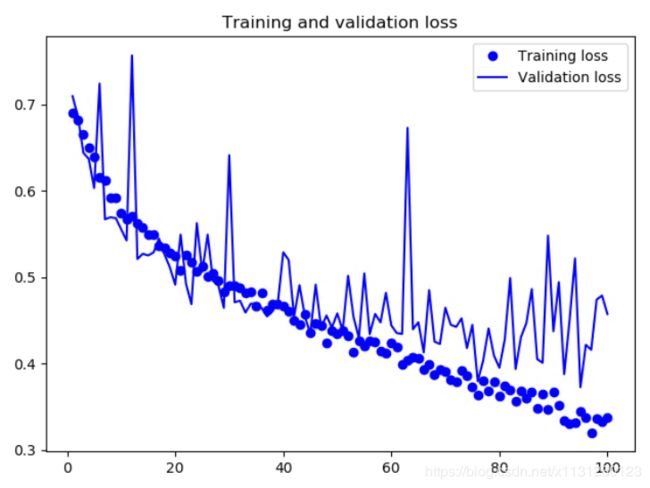
1、系列1给出了一个网络训练了100轮 ,但是过拟合了。模型足够大,能够表示出训练数据到labels的映射;
2、这次的训练也是训练100轮,但是每一轮32*100=3200张数据增强的图;
3、这一次训练训练了大约一个小时。GTX1060 6G;
4、这次训练的结果没有出现过拟合;
5、如果继续增加模型的层数和每一层卷积核个数,精度会更高,可以达到86%或87%;
6、但是根本原因还是训练数据过少,信息不够用;
7、训练模型cats_and_dogs_small_2.h5大小为26.3MB;
8、训练参数3,453,121个;
这一次我们给出过拟合解决方法:
使用数据增强和添加Dropout层防止过拟合!
Dropout层用在Flatten层后
数据增强使用:
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True, )
# 添加路径 图片尺寸 batch_size class_mode
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
代码:
import os, shutil
original_dataset_dir = r'F:\kaggle\train'
base_dir = 'F:/kaggle/cats_and_dogs_small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
test_dir = os.path.join(base_dir, 'test')
train_cats_dir = os.path.join(train_dir, 'cats')
train_dogs_dir = os.path.join(train_dir, 'dogs')
validation_cats_dir = os.path.join(validation_dir, 'cats')
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
test_cats_dir = os.path.join(test_dir, 'cats')
test_dogs_dir = os.path.join(test_dir, 'dogs')
from keras import layers
from keras import models
from keras import optimizers
# 数据增强带来的多余信息并不是那么够,模型还是会过拟合
# 所以这个模型在Flatten层后加了Dropout防止过拟合
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
# 数据预处理
from keras.preprocessing.image import ImageDataGenerator
# 数据增强
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True, )
# 测试数据不需要数据增强
test_datagen = ImageDataGenerator(rescale=1. / 255)
# 添加路径 图片尺寸 batch_size class_mode
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
# 添加路径 图片尺寸 batch_size class_mode
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
# 带了数据增强,每一张都不会一样,
# steps_per_epoch大小就不用算了,差不多就行
# 但是一轮大小,这个值也不能太大
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
# 保存模型 以后用
model.save('cats_and_dogs_small_2.h5')
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
结果