从Web of Science 爬取文章作者邮箱小记
最近因为课题组任务需要承接某国际会议,需要查阅给定文献作者的邮箱,因为数量较多,所以决定采用爬虫的方式来完成。
本文章主要在《Web of Science爬虫实战(Post方法)》(https://blog.csdn.net/jgzquanquan/article/details/78827413),此文的基础上进行改编。
如有错误请尽情指出,欢迎友好交流。
一、搜索关键词
搜索界面部分提交数据依照上文所述博客中的方法,采用post提交。这一步请参阅该博客文章,在此不进行详细阐述
对于得到的搜索页面进行分析
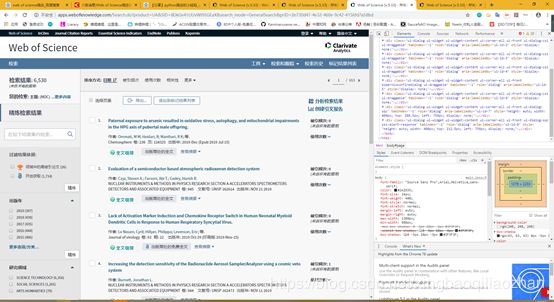
在假设标题足够精确的情况下,第一篇文章即为所求。
因此只需在页面中分析得到第一篇文章的地址即可。
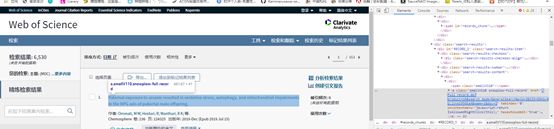
于是找到如下结构。
图中蓝色url即为所求链接。
因此书写以下XPath:
“//div[@class=‘search-results’]/div[1]/div[3]/div[1]/div/a/@href”
在此说明一点,页面不尽相同,所以上述Xpath可能并不合适,建议在该搜寻语句处设置断点,对etree中储存的xml页面进行实时的分析来获得恰当的xpath。

二、访问url
这一步较为简单,只需再次访问得到的url即可,
但是要注意以下几个问题:
1、url地址可能有问题
这一部分目前无明确结论,仍需进行进一步的实验,但是有证据表明得到的url可能并不能使用在访问上,在笔者的实际测试中,如下的url在点击访问时无法成功
http://apps.webofknowledge.com/full_record.do?product=UA&search_mode=GeneralSearch&qid=1&SID=5D7OHW9tDJiNZctsZJP&page=1&doc=1
而将qid=1改为qid=4后即可成功,但在最新的测试中发现可能并不需要改变,上述情况只是因为获取url到访问url间隔时间较长导致。
但是可以明确的一点是,随着时间的推移(根据目前的测试来看是一小时),webofscience会改变链接中的qid值,但具体变化范围尚不明确,笔者测试中有出现qid=1,qid=2,qid=4,qid=457等情况出现,此部分仍需后续讨论。
2、请求头与cookie
根据对网页的分析表明,请求方式是get
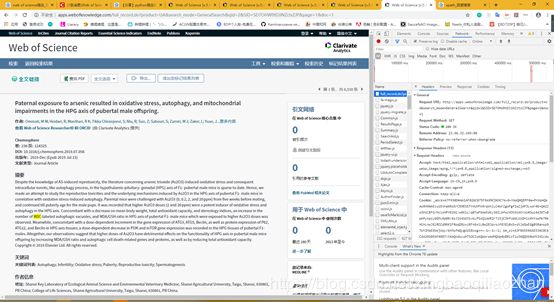
因此理论上来说采用get方法访问即可。
但是在实际测试中发现,直接使用get方法web of Science会拒绝访问,出现以下界面
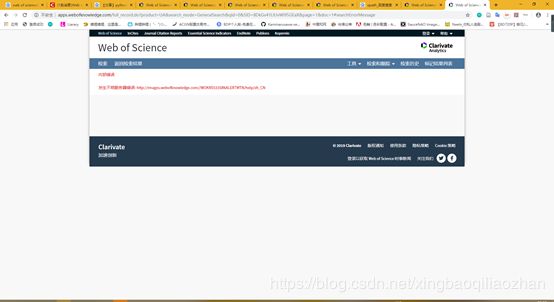
在研究后发现,应为Request header和Cookie的问题,分析表明web of science对于每一次给定的搜索请求都会产生一个固定的cookie用以追踪,因此需要在get方法中加入第一次请求中得到的cookie。因此实际get请求如下:

三、分析结果页面
因为此次是搜索作者邮箱,因此定位到作者邮箱位置
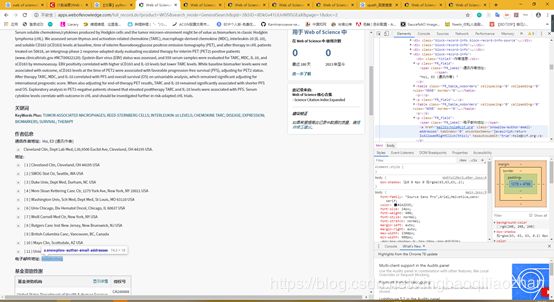
对html进行分析,得到xpath如下:
mail=newTree.xpath("//a[@class=‘snowplow-author-email-addresses’]/text()")
保存结果即可。
附结果如下:
Self-Driven Desalination and Advanced Treatment of Wastewater in a Modularized Filtration Air Cathode Microbial Desalination Cell
main init
Csv:
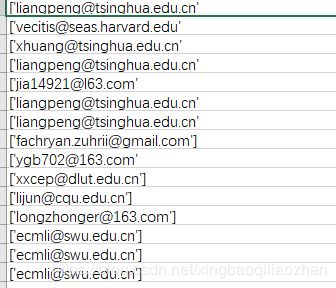
附完整代码:
注意:大部分代码来自于博客《Web of Science爬虫实战(Post方法)》(https://blog.csdn.net/jgzquanquan/article/details/78827413)
import re
from multiprocessing import Process
from multiprocessing import Manager
import requests
import time
import xlrd
from bs4 import BeautifulSoup
from lxml import etree
class SpiderMain(object):
def __init__(self, sid, kanming):
print(kanming)
self.hearders = {
'Origin': 'https://apps.webofknowledge.com',
'Referer': 'https://apps.webofknowledge.com/UA_GeneralSearch_input.do?product=UA&search_mode=GeneralSearch&SID=R1ZsJrXOFAcTqsL6uqh&preferencesSaved=',
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36",
'Content-Type': 'application/x-www-form-urlencoded'
}
self.form_data = {
'fieldCount': 1,
'action': 'search',
'product': 'WOS',
'search_mode': 'GeneralSearch',
'SID': sid,
'max_field_count': 25,
'formUpdated': 'true',
'value(input1)': kanming,
'value(select1)': 'TS',
'value(hidInput1)': '',
'limitStatus': 'collapsed',
'ss_lemmatization': 'On',
'ss_spellchecking': 'Suggest',
'SinceLastVisit_UTC': '',
'SinceLastVisit_DATE': '',
'period': 'Range Selection',
'range': 'ALL',
'startYear': '1985',
'endYear': '2019',
'update_back2search_link_param': 'yes',
'ssStatus': 'display:none',
'ss_showsuggestions': 'ON',
'ss_query_language': 'auto',
'ss_numDefaultGeneralSearchFields': 1,
'rs_sort_by': 'PY.D;LD.D;SO.A;VL.D;PG.A;AU.A'
}
self.form_data2 = {
'product': 'WOS',
'prev_search_mode': 'CombineSearches',
'search_mode': 'CombineSearches',
'SID': sid,
'action': 'remove',
'goToPageLoc': 'SearchHistoryTableBanner',
'currUrl': 'https://apps.webofknowledge.com/WOS_CombineSearches_input.do?SID=' + sid + '&product=WOS&search_mode=CombineSearches',
'x': 48,
'y': 9,
'dSet': 1
}
print("main init")
def craw(self, root_url,i):
try:
s = requests.Session()
r = s.post(root_url, data=self.form_data, headers=self.hearders)
print(r.cookies)
r.encoding = r.apparent_encoding
tree = etree.HTML(r.text)
cited=tree.xpath("//div[@class='search-results']/div[1]/div[3]/div[1]/div/a/@href")
extraAddress="http://apps.webofknowledge.com"
extrCited=extraAddress+cited[0]
extraNewAddress=extrCited.replace("qid=1","qid=1")
print(extraNewAddress)
headers1= {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36',
'Host': 'apps.webofknowledge.com',
'Upgrade-Insecure-Requests': '1',
}
#extraPage=s1.post(extraNewAddress,headers=headers1)
#cook={'Cookie':'_abck=A7F930D44A1AF026C075F9A99CD69C7A~0~YAAQHQEPF0a+PnVpAQAAoXH9mAEzuiEnhaXRsXrCR9ESSTYnUVFK4rqVnlLC4WrZgsPgfIwZjAP3Lxor4G+Q42Zo3HzCBFO/HclsHPY81Ni/wRK1c/q07wPXAetdKy36ILbfocVOt9zAtrxU4Ouz4d3XTxBpbPynpzy6GMv4p0R/6sJ1t41631vkLPSsQlwWR2r7i5jC3XfUddLUzGHlxXhYsoMk7RKHihLnwJGlROZd9NX1FRoqDBz+zRFn6xiL0w2BJpvszf0JGl0xS+stlkGwEGg0SRansp97WY2MoEXbkjVpy/bhMufmQygUUS8xxg==~-1~-1~-1; SID="6C6aTYEWpCkEnge5Vhl"; CUSTOMER="Harbin Institute of Technology"; E_GROUP_NAME="Harbin Institute of Technology"; dotmatics.elementalKey=SLsLWlMhrHnTjDerSrlG; ak_bmsc=BBAE5EA6D4AFA798839E6AFE7442D6DDB81CDA9D001000007271BE5D317DB564~pl11ISUEBtDHIuThK6/GCw3UXAj57T3oJi9yPhdVvh9Esy5erYJqa6ly1qgaCauiQlIYbD/y4Nx4oiV616jXe3mGtDqajMa2gfDzBvyyA1/hviRXzpt7DsBmjnkBnZgS8UfAK3WxFifyjozwKayxmRvrz5lW2/bapypIoPVFGg3TmAv8wsouOmzC/qyU1/KQtdptD5VEOmHT5kCn7icX84pm6IMEvqvhQEQ/6EM9ZW/2E=; bm_sz=895DC105D2395C4BDF1C5598D824526A~YAAQndocuFuJNyZuAQAAeijrLwVQWiLTECREBfMqtkmMfwSSgAITAgwjDJXQSm7Dd2+Em438tXfvT9MvFMIgxbAriP+DWFffj7h1WKJOUfuXnoQPaIwrvdH6ecY6um4pPEFTBXH8cxPZqePBUp85ksHuF37Uk6bE0v+I5RXpln+Zb+7ySMxz6dxX+AVMLOoRrzGzDsBgVL0=; _sp_ses.630e=*; JSESSIONID=43E79638A407BF40F3E32407BD1A25C1; bm_sv=F8232EFC4977145D429FAF69D3B9B33B~O44K8KhvyPqYzr54ZpVXGpu3/dWgDW1QvS/lpaFBTyxlTM5rwNGtfRTenAtTTjQeagSa7jZ1DKQNxwwAqOK2c2IWHYa6fP8u5O9TDFZXDFSmHjUCNcC11Xx984zq4037FAOvaIRZhsqnJUL01hV0RJomm3pOKNEhkVXhh8dUlpk=; _sp_id.630e=e300f5c6-7915-4bee-8414-0e2af220bdbd.1551543908.31.1572762145.1572750866.b5d66175-470b-4f69-92e6-2b5560bf048c'}
#extraPage=s.get(extraNewAddress,headers=headers1,cookies=cook)
extraPage=s.get(extraNewAddress,headers=headers1,cookies=r.cookies)
print(2)
#extraPage=requests.get(extraNewAddress)
extraPage.encoding=extraPage.apparent_encoding
newTree=etree.HTML(extraPage.text)
f=open("2.txt","w", encoding='UTF-8')
f.write(extraPage.text)
f.close()
print("close")
mail=newTree.xpath("//a[@class='snowplow-author-email-addresses']/text()")
print(mail,extraPage.url)
#download = tree.xpath(".//div[@class='alum_text']/span/text()")
flag = 0
#print(i,cited, download,r.url)
flag=0
return mail, flag
except Exception as e:
if i == 0:
print(e)
print(i)
flag = 1
mail=-1
return mail, flag
else:
print("error")
return -1,1
def delete_history(self):
murl = 'https://apps.webofknowledge.com/WOS_CombineSearches.do'
s = requests.Session()
s.post(murl, data=self.form_data2, headers=self.hearders)
root_url = 'https://apps.webofknowledge.com/WOS_GeneralSearch.do'
if __name__ == "__main__":
# sid='6AYLQ8ZFGGVXDTaCTV9'
root = 'http://www.webofknowledge.com/'
#s = requests.get(root)
#sid = re.findall(r'SID=\w+&', s.url)[0].replace('SID=', '').replace('&', '')
#print(sid)
#kanming="Cell"
print("if")
data = xlrd.open_workbook('1.xlsx')
table = data.sheets()[0]#具体是取哪个表格
nrows = table.nrows
ncols = table.ncols
ctype = 1
xf = 0
csv = open('1.csv', 'a')
fail = open('fail.txt', 'a')
for i in range(0, nrows):
if i % 100 == 0:
# 每一百次更换sid
s = requests.get(root)
sid = re.findall(r'SID=\w+&', s.url)[0].replace('SID=', '').replace('&', '')
kanming = table.cell(i, 0).value
obj_spider = SpiderMain(sid, kanming)
mail,flag = obj_spider.craw(root_url,i)
if flag==1:
fail.write(str(i)+'\n')
else:
if len(mail)==0:
mail.append(0)
print(mail)
csv.write(str(mail)+ ',' + '\n')
csv.close()