推荐算法基础--相似度计算方法汇总
推荐系统中相似度计算可以说是基础中的基础了,因为基本所有的推荐算法都是在计算相似度,用户相似度或者物品相似度,这里罗列一下各种相似度计算方法和适用点
余弦相似度
这个基本上是最常用的,最初用在计算文本相似度效果很好,一般像tf-idf一下然后计算,推荐中在协同过滤以及很多算法中都比其他相似度效果理想。
由于余弦相似度表示方向上的差异,对距离不敏感,所以有时候也关心距离上的差异会先对每个值都减去一个均值,这样称为调整余弦相似度
欧式距离
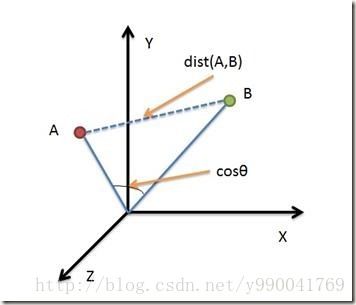
基本上就是两个点的空间距离,下面这个图就能很明显的说明他和余弦相似度区别,欧式距离更多考虑的是空间中两条直线的距离,而余弦相似度关心的是空间夹角。所以
欧氏距离能够体现个体数值特征的绝对差异,所以更多的用于需要从维度的数值大小中体现差异的分析,如使用用户行为指标分析用户价值的相似度或差异。
余弦距离更多的是从方向上区分差异,而对绝对的数值不敏感,更多的用于使用用户对内容评分来区分兴趣的相似度和差异,同时修正了用户间可能存在的度量标准不统一的问题(因为余弦距离对绝对数值不敏感)。
皮尔逊相关性(PC)
上面是总体相关系数,常用希腊小写字母 ρ (rho) 作为代表符号。估算样本的协方差和标准差,可得到样本相关系数(样本皮尔逊系数),常用英文小写字母 r 代表:
其实这个就是前面讲的调整的余弦相似度,因为在推荐系统中均值分为用户的均值和物品的均值,这里相当于是物品的均值。这个也是比较常用的。
斯皮尔曼等级相关系数
斯皮尔曼相关系数(Spearman Rank Correlation)被定义成 等级变量之间的皮尔逊相关系数。[1] 对于样本容量为 n的样本, n个 原始数据 Xi,Yi 被转换成等级数据 xi,yi , 相关系数ρ为
实际应用中, 变量间的连结是无关紧要的, 于是可以通过简单的步骤计算 ρ.[1][2] 被观测的两个变量的等级的差值 di=xi−yi , 则 ρ 为
看一个维基百科的例子:
| 智商, Xi | 每周花在电视上的小时数, Yi | 等级 xi | 等级 yi | di | d2i |
|---|---|---|---|---|---|
| 86 | 0 | 1 | 1 | 0 | 0 |
| 97 | 20 | 2 | 6 | -4 | 16 |
| 99 | 28 | 3 | 8 | -5 | 25 |
| 100 | 27 | 4 | 7 | -3 | 9 |
| 101 | 50 | 5 | 10 | -5 | 25 |
| 103 | 29 | 6 | 9 | -3 | 9 |
| 106 | 7 | 7 | 3 | 4 | 16 |
| 110 | 17 | 8 | 5 | 3 | 9 |
| 112 | 6 | 9 | 2 | 7 | 49 |
| 113 | 12 | 10 | 4 | 6 | 36 |
根据 d2i 计算 ∑d2i=194 。 样本容量n为 10。 将这些值带入方程
得 ρ = −0.175757575…
这个值很小表明上述两个变量的关系很小。 原始数据不能用于此方程中,相应的, 应使用皮尔逊相关系数计算等级。
我们发现这个思路是不考虑数据本身,只考虑变量间的排名顺序,理论上SRC可以避免对rating进行标准化的问题
平均平方差异(MSD)
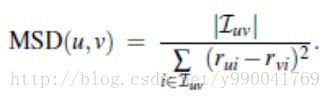
计算两个用户在打分中均方差,表现比PC差,因为它没有考虑到用户偏好或产品的被欣赏程度之间的负相关。
有论文比较过PC的MAE 要优于 MSD 和SRC
Jaccard 距离和Dice系数
意思是两个集合的交集除以并集,比如文本相似度可以用出现相同词个数进行计算。