一次涉及两个大表关联的优化
sql:
select *
from (select fd.analystid,
dr.objid DOCID,
dr.title,
row_number() over(partition by fd.analystid order by dr.doctime desc) rown
from fa_docanalystrela fd
inner join doc_researchreportcore dr
on (fd.docid = dr.objid )
where dr.doctime > sysdate - 90)
where rown = 1
and analystid in ('115880',
'84947',
'114456',
'83715',
'85335',
'84106',
'116090',
'112112',
'112265',
'127614');执行计划:
执行很慢,要12s左右,而只得到7条记录。
这是一个看似很简单的sql,这个sql当时优化了一下午,想了很多方法,也没拿到好的优化方法,晚上请高手帮忙也没搞定。
第三天,没事的时候,好好分析了下这两个表的关联,找到了一点突破口:
(1)、查看量表的记录数:
select count(*) from DOC_RESEARCHREPORTCORE;--832391
select count(*) from FA_DOCANALYSTRELA--699367
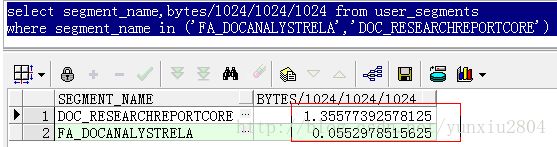
(2)、查看量表存储空间大小:
(3)、根据表关系查看经过过滤条件后量表关联时的记录:
select count(*) from doc_researchreportcore where doctime > sysdate - 90
--73949
select count(*) from fa_docanalystrela where analystid in ('115880',
'84947',
'114456',
'83715',
'85335',
'84106',
'116090',
'112112',
'112265',
'127614');
--2829
分析:
1、由(1)和(2)可看到,量表记录差不过,但是存储空间相差很大,刚刚开始以为是
doc_researchreportcore数据块稀疏或者有过多的空块造成的,处理使块收缩后所占存储空间基本上没有变化;
查看表结构发现该表字段很多的缘故,这里想到把所需要搜索的字段建组合索引,这个消除对大表的回表。
这里建立组合索引(DOCTIME, OBJID, TITLE)。
2、由(3)看出,入股走loop关联的话会是2829和73949的嵌套循环,这个会使开销很大;这里考虑走hashjoin,让小表fa_docanalystrela去驱动大表doc_researchreportcore,这样会极大的减少开销。
下面是修改后的sql和执行计划:执行时间为0.998s,多次请缓存区执行时间都控制在1s以内,基本上满足了需求。
select *
from (select fd.analystid,
dr.objid DOCID,
dr.title,
row_number() over(partition by fd.analystid order by dr.doctime desc) rown
from fa_docanalystrela fd
inner join doc_researchreportcore dr
on (fd.docid = dr.objid )
where dr.doctime > sysdate - 90)
where rown = 1
and analystid in ('115880',
'84947',
'114456',
'83715',
'85335',
'84106',
'116090',
'112112',
'112265',
'127614');
执行计划:
总结:
这里用到了分析表连接关系,走正确的表关联关系和减少回表。
这里执行时间有12s降到0.998s,虽然基本上满足的需求,但是有2189次递归、43次排序、2861次物理读和3368次逻辑读,这些是必须的开销。