Elasticsearch multi-index join实践
Elasticsearch 多索引 join 实践
注:本文采用的实现语言是python,用到了python中的第三方库。
作者:aideny
前言
博主近期在开发一个解析引擎,把我们定义的json格式查询语言解析成多种数据源的查询语言,然后可以从服务器上的数据源中查询到结果。就类似数据库理论中视图层的工作吧。
这个解析引擎的工作流程就像下面这样:
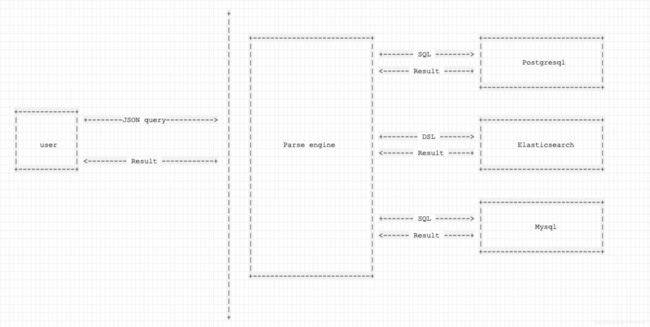
通过这张图就可以理解博主需要做的工作,就是在后台支持一个实时的查询,用户是无法感知到后台不同数据源之间的查询差异的。
要真正实现一个广义的数据查询引擎,join是一个避不开的问题。后台有一个数据源是ES,由于这是一个实时的解析过程,而且只是一个解析的过程,所以不能更改数据源中已有的数据结构,只能想办法支持怎么去查询它。
博主在这里总结一下,是怎么支持ES的join查询。这里采用的一个方案是比较通用的,不依赖于ES特定版本提供的查询API。因为ES不同版本之间的DSL写法也存在一定的差异。
通用方案
经过调研,支持ES join 有这么一些方法:
- 完全不join,把关联表的字段融合到一张表里。当然这会造成数据的冗余
- 录入的时候join:使用 nested documents(nested document和主文档是同segment存储的,对于一个symbol,几千万个quote这样的场景就不适合了)
- 录入的时候join:使用 siren
- 查询时join:使用 parent/child (这个是elasticsearch的特性,要求parent/child同shard存在)
- 查询时join:使用 siren-joins(就是一个在服务端求值的filter,然后把结果发布给每个shard去做二次match)
- 查询时join:在客户端拼装第二个查询(和siren-joins差不多,但是多了一次客户端到服务器的来回)
- 在内存中join
由于我需要做的工作是针对已有的“表”进行一个实时的查询,而且线上的ES还有版本差异,有5.x的,有6.x的。所以就不能采用依赖表结构和ES的语法特性了,最后采用的方案是在内存中join。这也是一个通用的方案,不依赖es版本,不依赖于语法特性,只要单表能查,那么就能够join。
具体做法
观察单表查询结果
首先可以观察一下对单索引查询的一个结果,看看它的结构是什么样子。
单索引查询的DSL:
{
"query": {
"bool":{
"must":[
{
"range":{
"data_time":{
"lte":"2019-11-28T14:07:32.845+0800"
}
}
}
]
}
},
"sort":[
{
"device":{
"order":"asc"
}
}
],
"aggs":{
"groupby":{
"terms":{
"script": {
"source":"'p_id:' + doc['p_id'].value + ';' + 'entrance_time:' + doc['entrance_time'].value"
}
},
"aggs":{
"version__count":{
"value_count": {
"field": "version"
}
}
}
}
}
}
查询结果:
{
"took": 54,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 250,
"max_score": 2,
"hits": [
{
"_index": "index_1",
"_type": "doc",
"_id": "1",
"_score": 2,
"_source": {
"key": "value",
...
}
},
{...}
]
},
"aggregations": {
"groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 140,
"buckets": [
{
"key": "p_id:value;entrance_time:value",
"doc_count": 10,
"version__count": 10
},
{...}
]
}
可以看出结果json格式的,我们需要的数据就包含在 result['hits']['hits'] 或者 result['aggregations']['groupby'][buckets]中(一个列表,列表元素是字典类型)。
收集所需数据:
def manage_es_query_result(raw_result):
if 'aggs' in raw_result or 'aggregation' in raw_result:
if raw_result.get('aggregation') is not None:
result = raw_result['aggregation']['groupby']['buckets']
else:
result = raw_result['agg']['groupby']['buckets']
for it in result:
pair = it['key'].split(';')
for pair_item in pair:
it.update({pair_item.split(':')[0]: pair_item.split(':')[1]})
del it['key']
for key, value in it.items():
if isinstance(value, dict) and 'value' in value:
it[key] = value['value']
elif 'hits' in raw_result and 'hits' in raw_result['hits']:
result = list(map(lambda x: x['_source'], raw_result['hits']['hits']))
return result
选择合适的中间数据结构
经过观察单索引的查询结果,得出以上结论之后,再调研用什么来把这样用json结构存储的数据集合在内存中进行join。有没有什么现有的轮子?(实际开发中能不造轮子就尽量不造轮子,开发成本是有的)
经过调研,发现pandas可以支持这样的需求。
文档中是这样介绍的:
pandas provides various facilities for easily combining together Series or DataFrame with various kinds of set logic for the indexes and relational algebra functionality in the case of join / merge-type operations.
–pandas document
那么现在要做的工作就是把ES的查询结果转换为pandas的Dataframe类型,上面我们经过观察单索引的查询结果,可以看出我们需要的数据是以json的格式组织在一起,那么接下来要做的本质上就是把json格式的数据集合转换为pandas Dataframe。
转换过程
pandas本身就提供一些用于转换json数据集到Dataframe的API:
- pandas.read_json()
- pandas.json_normalize()
我把这两个都试了一下,得出的一些结论:
- 前者的转换效率比后者要高一些
- 前者对json数据集格式的要求比较高,不够灵活,而于我要做的工作而言就更不够灵活了
json_normalize()其实于我心中期望的结果还是有一些差距的,因为它转换后的数据列顺序不可控,这样就给我后期封装查询结果造成了一些负担。
于是继续调研,stackoverflow上有一个说法,可以自己根据json数据集手动构造Dataframe,而且只要算法没有太大问题,效率还挺高的。这里是我之前没有过多接触pandas这个库,不知道还有这个操作~
于是写了构造的代码,测了一下性能,发现性能居然比json_normalize()还要快一些,而且由于是手动构造的,可控性要比pandas提供的这两个API都要好,于是最终就手动来转换了。
手动转换:
def convert_result_to_dataframe(result, fields):
"""
@parm result: 需要转换的json数据集
@parm fields: 查询结果字段列表,控制转换后DataFrame的列顺序
"""
data = []
for item in result:
line = []
for field in fields:
line.append(item[field])
data.append(line)
df = pandas.DataFrame(data, columes=fields)
return df
进行join
到这里,ES的查询结果已经转换为了Dataframe结构,直接调用pandas的API进行join即可。
用到的API说明地址:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html#pandas.DataFrame.merge
最后提一下pandas.merge,其实不说也可以,因为官网的文档已经讲的很清楚了。
关于pandas.merge的how参数:
- inner:inner join(默认是inner)
- left:left join
- outer:full join
结语
失败只是实践过程中的一个部分,只要不气馁,保持最初的信心,不断根据事实调整自己的方向,最终还是会走向自己希望到达的彼岸的。
我在这次实践的过程中也走了一些弯路,比如:
-
最初考虑的是利用ES本身的特性来实现join,调研了大量的资料,进行了很多尝试最后都宣布失败。
-
最初考虑的是直接将ES的查询结果转换为Dataframe,尝试了pandasticsearc 这个库,结果很不理想,可控性太差,性能也有些无法接受。
-
……
不过最后还是达成了目标不是嘛。