回顾一下暑期在Future camp学习的推荐算法(二)——基于图的随机游走算法
一、Day1 图的基础知识+SNAP初体验
1、图的基础知识
1.图的表示:
对于图G=(V, E),V为结点,E为边,一般可以用邻接链表和邻接矩阵表示。
邻接链表是每个结点相邻的节点链接而成链表的集合;邻接矩阵中用1表示结点之间相邻,用0表示不相邻。
图可以分为有向图和无向图,无向图如下所示:

(a)图为一个含有5个节点,7条边的无向图G;(b)为G的邻接链表表示;(c)为G的邻接矩阵表示
有向图如下所示:

(a)图为一个含有6个节点,8条边的有向图G;(b)为G的邻接链表表示;(c)为G的邻接矩阵表示
2.图的遍历--DFS(深度优先搜索)、BFS(广度优先搜索)
DFS:从图的某一个结点出发,找一个相邻的结点,以这个相邻的结点为准,再找下一个未被遍历的相邻的结点,直到结点没有未被遍历的相邻结点时,返回上一个结点,继续寻找未被遍历的相邻的结点,直到所有的结点被遍历。
BFS:从图的某一个结点出发,找距离该结点距离为1的结点,然后找与该结点距离为2的结点,直到遍历所有的结点。
3.二分图(Bipartite graph)
二分图简单来说是一种将节点分为两组,并且图中所有的边都跨越这两组的图。
具体定义为:把一个图的顶点划分为两个不相交集和,并且使得每一条边都分别连接这两个集合中的顶点。如果存在这样的划分,则此图为一个二分图。

2、配置python2.7环境+SNAP的初体验
使用anaconda的命令行工具重新创建了一个名为SNAP_ENV的虚拟环境,但是在下载的相应的python包的时候,有些包总是下不下来,解决办法是,在出了提示后,按照提示的网址去手动下载相应的包,然后通过conda install手动安装即可。还有一种解决办法是换conda的channel,换成清华大学的镜像网站即可。
SNAP为一个.py的文件,直接将其拷贝到项目目录下,使用import snap导入即可。
向量的表示:
v = snap.TIntV()
v.Add(15)
v.SetVal(0,100)
图的表示:
G1 = snap.TNGraph.New()
G1.AddNode(1)
G1.AddNode(5)
G1.AddEdge(1,5)
SNAP为我们设计好了相应的图的结构,我们只需要学会操作,就能很方便地通过图来进行我们的推荐算法的研究了,感觉很棒哦。
分享一下的《算法导论》第三版中文版的PDF:
https://pan.baidu.com/s/15wfaX9tb2P63PylGu_QdKg 密码:bzzf
二、Day2-Day4 随机游走算法的认识+对SNAP的困惑
1、随机游走算法
随机游走顾名思义就是指一种完全随机地游走,而通过随机游走能够得到图里各顶点之间的相关度。
具体的思路如下:

假如有上图A、B、C代表用户,而a、b、c、d代表商品,连线代表用户喜欢该商品。
如果我们想通过随机游走,算出用户A和别的商品之间的关联度时,即用户可能喜欢的商品时,我们的随机游走每次都应该从A出发,经过多次随机在ABCabcd顶点之间的游走,找到游走次数多的顶点,则说明该顶点与A关联度很强。
但是如果要通过算法实现出来的话,又会遇到一些困难,我们怎么样把这个关联度算出来呢?这里又得通过迭代的方法了:
1.设定关联度的初始值为PR(A)=1,其余都为0。
2.从A点开始向外游走,假设从A点走出去的概率为α,则停留在A点的概率为1-α,a点会得到来自A的关联度1*α*1/2,此时因为其他点的关联度都为0,所以a点就是1*α*1/2。同理可得c点最后的关联度也为1*α*1/2,此时A点自身的关联度为1-a。第一次迭代结束。
3.第二次迭代的时候,除了A点以外,a和c也有了关联度,从这几个点出发,继续游走,计算出其他点的关联度。重复以上过程。因为每次都是从A点出发,因此结束的时候A点要加上1-a。
4.迭代到一定次数的时候,各点的对A的关联度会趋于一个定值,通过这个定值可以找出和A最相关的商品,进而进行推荐。
迭代公式概括如下:
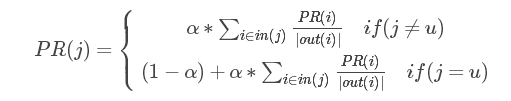
u为用户顶点,即上例中的用户A,PR(i)为i顶点当前的关联度,out(i)为与i顶点相连的顶点个数,α为不停留在当前顶点的概率。
2、对SNAP的困惑
在刚开始使用的SNAP的时候,感觉这个东西真的很难用,并且想要对相应的图和网结构进行迭代确实很困哪。这个时候又看到论坛里面有人开始使用networkx,感觉绘出来的图像挺不错的,操作也简单,所以就开始纠结该用SNAP还是networkx了,后来觉得SANP既然是用来做相应的研究的,应该有它自己的过人之处,所以还是硬着头皮将SNAP学了下来。
对SNAP的图结构来说,它有GRAPH和NETWORK,即图和网络。图是只有结点和边,并且结点和边上都不能够添加属性的,而网络除了结点和边以外,还能够给边和结点附上属性。
一开始我考虑的是应该在边上加上权重,所以我选择了TUndirNet 无向网络这个类,但是这个类有一个坑爹的地方,就是他的边没有ID,所以取边权重的时候就很麻烦,需要相应的两个的结点,并且取出来的值是放在SNAP专有的TInt类的Val里面,十分地复杂,而且到了最后我也没把边的权重给拿出来(一直报错)。
后来我干脆放弃了无向网络,改成用有向网络TNEANet这个类,这个类的边能够通过ID直接将边的权重取出来,但是每次取边的权重的时候,我需要判断边的方向,不能将边取反了,但是通过这个类还是能将有权重的关联图给算出来了。
总结:SNAP真的好难用呀!
三、Day5 考虑对算出来的关联度进行评估
在week1做推荐算法的时候,到了最后都能够将相应的预测评分算出来,可是到了这一周,算出来的是关联度,我直接就懵比了,这应该怎么评估呢?
1、关联图评估
无权重的评估可以将最后得到的关联度TopN算出来,和测试集里的N个数据进行比较。
召回率 = (TopN∩N) / N
准确率 = (TopN∩N) / TopN
在这里得感谢群里大神的帮助,不然对无权重的图怎么评估我都是懵比的
2、有权重的关联图评估
有权重的图真的不知道应该怎么评估,算出来的关联度即不能像week1里面做评分预测对比测试集,也不能像无权重关联图一样做TopN召回率和准确率预测。真的头大了。
到最后我放弃了对有权重的关联图的评估 \掀桌(╯—﹏—)╯(┷━━━┷
四、Day6 跑算法+算法评估
1、算法
不得不说随机游走算法真的很费时间。
这里我使用的是MovieLen的数据,因为最后进行的没有权重的推荐,所以我将用户评分过的电影都当成是用户喜欢的电影。然后测试跑过之后TopN的召回率和准确率,这里的N选择为10。
代码的大概思路如下:
1.将每个用户喜欢的电影抽出10个当成测试集,剩下的为训练集
2.分别取迭代次数10次、15次、20次进行随机游走,将所有用户的关联度算出来
3.取关联度最高的进行前10个items进行top10的召回率与准确率评估
2、算法评估
MovieLen数据集里有943位用户,1682部电影,共100000条评分数据。
说明:
1.有权重的图:权重即为用户评分;
2.无权重的图,将用户评过分的电影当成用户喜欢的电影,没有评分则不喜欢。
1.有权图与无权图的迭代时间
下表为有权重图与无权重图迭代时间对比:
(计算单个用户的关联度所需时间)
|
|
迭代10次 |
迭代15次 |
迭代20次 |
| 无权重图 |
1.623s |
2.386s |
3.291s |
| 有权重图 |
21.188s |
32.039s |
42.791s |
计算有权重的图所需时间真的不是盖的,贼长。速度慢的问题可以通过矩阵改进算法加快,但是没有来得及看相应的改进算法 \捂脸
2.无权图的召回率与精度
|
|
值 |
| 召回率(TopN∩N) / N |
≈0 |
| 准确度(TopN∩N) / TopN |
≈0 |
这个结果我都惊呆了,测评了所有的943个用户,只有4个用户的Top10召回率和准确率为0.1,其他都为0。不过后来我细想了一下发现了问题的所在,问题其实很简单,其实一开始就不应该把用户评过分的电影当成是用户喜欢的电影,因为用户看过的电影和用户喜欢的电影本来就没有任何关联。
3.有权图的召回率和精度
吸取了上面的错误,我想有权图应该能将用户喜欢的电影top10推荐出来,但是我想不到应该怎么评测。\哭哭
总结:这一周学的东西也很多,但是最后跑出来的结果却是这样子,虽然结果不好,但是我觉得过程还是很有意义的,知道了随机游走算法,处理数据集的能力大大地提升,不过也清楚地认识到了自己能力也是非常不足的,同志还需要努力!感谢FutureCamp给了我这么一个提升能力的机会,祝你们未来的路越走越好!
这两篇日志都是我在FutureCamp训练营里面写的,现在回来看看,发现第一周比较努力,基本上一整周除了吃饭睡觉就都在写代码,到了第二周可能就有点吃不消了,最后也没有尝试使用除了snap以外别的库,在第二周也只得了良(第一周是优,捂脸),算是比较遗憾吧。