java客户端jedis和分布式redis
1.redis的客户端介绍
redis作为一个市场占率极高的常用存储技术,有很多语言支持封装了redis的客户端.
这里我们使用jedis来学习代码操作redis的过程,jedis优势是其中方法名称几乎和使用redis命令一致的.
可以在某个测试系统中,准备jedis的依赖资源
 测试阶段使用的客户端进程必须是redis-server 配置文件启动服务端.不能使用redis-server启动在6379服务端(默认配置中,有一个开启了保护模式,只允许本地访问).所以本案例中的服务端就是启动在9000的redis-server
测试阶段使用的客户端进程必须是redis-server 配置文件启动服务端.不能使用redis-server启动在6379服务端(默认配置中,有一个开启了保护模式,只允许本地访问).所以本案例中的服务端就是启动在9000的redis-server
2.java客户端jedis的测试案例
2.1jedis连接redis创建对象
 2.2redis应用和结构
2.2redis应用和结构
有了jedis对象,使用java代码可以实现访问第三方容器了.基于这个功能,已经可以去解决session共享问题,但是redis结构单节点.
单节点redis缺点:
容量比较小,内存处理
并发能力低,单节点 理论值 万条/秒
引入集群–数据处理的分布式集群
数据分片计算满足一个特点:单调性(当执行数据切分计算时,保证往哪存的数据,读取从哪取),保证单调性,看hash取余的计算逻辑;
为什么hash取余,第一算法经典,很多分布式计算都用到,第二为了引出一致性hash算法做对比.
启动一个redis三个节点集群
都是提前准备好的配置文件,分别占用了6379 6380 6381端口
调用redis根目录一个shell脚本start-redis.sh(在运行shell脚本之前不要启动redis-server默认命令,否则脚本里6379端口redis无法启动)
hash取余
核心是hash散列计算,保证单调性的基础.这里使用Object类型的方法hashCode()对key值做hash取余计算,计算公式是:
(key.hashCode()&Integer.MAX_VALUE)%n,其中这个n的值是个正整数表示分片计算的个数.这里是3.
key.hashCode(): key值不变总能得到一个对应不变的整数,可正可负
key.hashCode()&Integer.MAX_VALUE: 对key得到的hash整数做31位保真运算,结果是,key不变最终总会对应一个不变的正整数.
31位保真的运算: 任意一个整数,取二进制与最大正整数31位个1做位的与运算,保留原值的31位数字,结果永远是正的
 (key.hashCode()&Integer.MAX_VALUE)%n:结果是[0,1,2,3,…,n-1]区间中一个值,取余算法的特点.
(key.hashCode()&Integer.MAX_VALUE)%n:结果是[0,1,2,3,…,n-1]区间中一个值,取余算法的特点.
n是分片个数,现在结构中就是redis节点个数,人为定义
key值hash取余得到0时,对应6379这个节点
key值hash取余得到1时,对应6380这个节点
key值hash取余得到2时,对应6381这个节点
无论key到底是什么样的值,最终都可以保证单调性情况下对应到一个redis节点,从而将大量key-value进行切分计算.
hash取余计算结论:经过公示的计算,对应关系定义,总是可以得到key值不变,总能对应到同一个redis节点实现数据的读和写.
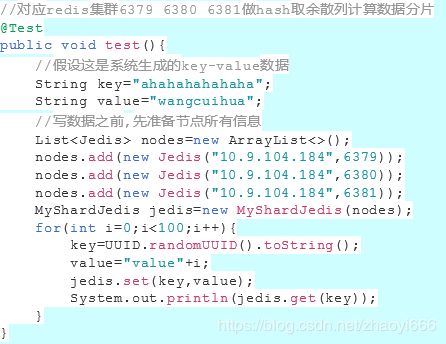
利用hash取余做一个测试
MyShardJedis:封装hash取余计算

使用MyShardJedis测试分片
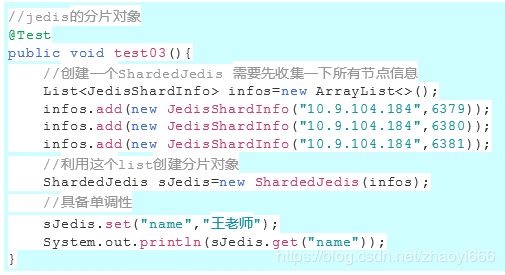
 2.3jedis的分片对象
2.3jedis的分片对象
在jedis客户端中,已经实现了一个封装数据分片计算逻辑的分片对象ShardedJedis,底层使用一致性hash计算.
 2.4一致性hash
2.4一致性hash
hash取余算法,在redis集群做扩容,缩容导致分片个数(取余n)发生变化,这种结构的集群,不适合使用hash取余,会造成单调性大量失效.
 一致性hash
一致性hash
介绍:
1997年麻省理工大学团队创造的数学模型.
基础:散列映射
对应计算机中任意一个内存数据,都能实现hash散列计算得到对应一个0—2^32-1的整数区间中(32位环结构)–hash环
数据映射:
节点收集信息时,提供了host:port,可以使用散列计算对应到hash环中某一个整数值,而且只要节点不变化对应的整数值也不变
key值也要做散列映射,对应hash环中某个整数值