【语义分割】全卷积网络-FCN
什么是语义分割:
图像语义分割的意思就是机器自动分割并识别出图像中的内容,比如给出一个人骑摩托车的照片,机器判断后应当能够生成右侧图,红色标注为人,绿色是车(黑色表示 back ground)。

两种传统图像语义分割:
在 Deeplearning 技术快速发展之前,就已经有了很多做图像分割的技术,其中比较著名的是一种叫做 “Normalized cut” 的图划分方法,简称 “N-cut”。N-cut 的计算有一些连接权重的公式,它的思想主要是通过像素和像素之间的关系权重来综合考虑,根据给出的阈值,将图像一分为二。
这种需要人机交互的技术叫 Grab Cut。给定一张图片,然后人工在想要抠图(也就是我们说的分割)的区域画一个红框,然后机器会对略小于这个框的内容进行 “主体计算”,嗯,这个 “主体计算” 是我起的名字,为了你们更好的理解背后复杂的设计和公式,因为机器会默认红框中部是用户期望得到的结果,所以将中部作为主体参考,然后剔除和主体差异较大的部分,留下结果。

抠出来的部分叫 “前景”,剔除的部分叫 “背景”。有时候还挺好用的,但是稍微复杂一点的时候就难以处理了。Grab Cut 的缺点很明显,首先,它同 N-cut 一样也只能做二类语义分割,说人话就是一次只能分割一类,非黑即白,多个目标图像就要多次运算。其次,它需要人工干预,这个弱点在将来批量化处理和智能时代简直就是死穴。
人类的智慧是无止境的,DeepLearning(深度学习)终于开始大行其道了。想了解更多传统语义分割算法的可以再去百度。
FCN(Fully convolutional networks):
今天重点是:Fully convolutional networks for semantic segmentation。
下图是该文章网络结构:
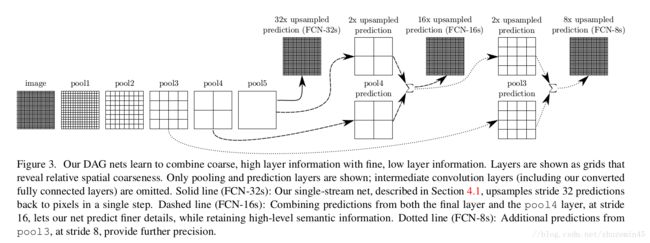
如上图,在 FCN 网络模型中,每一个卷积层,都包含了 [卷积 + 池化] 处理,处理之后的结果是:图像的像素信息变小了,每一层的像素信息都是前一层的 1/2 大小,到第五层的时候,图像大小为原始图像的 1/32。
传统 CNN 算法里,这并没有什么要紧的,因为 CNN 最终只输出一个分类结果或者说特征,但是 FCN 不同,FCN 是像素级别的识别,也就是输入有多少像素,输出就要多少像素,像素之间完全映射,并且在输出图像上有信息标注,指明每一个像素可能是什么物体 / 类别。所以就必须对这 1/32 的图像进行还原。
这里用到个纯数学的方法,叫“反卷积”,对第 5 层进行反卷积,可以将图像扩充至原来的大小(严格说是近似原始大小,一般会大一点,但是会裁剪掉,具体裁剪多大合适得根据网络和数据集不同而定。
我们可以对任一层卷积层做反卷积处理,得到最后的图像,比如用第三层 (8s-8 倍放大),第四层 (16s-16 倍放大),第五层 (32s-32 倍放大) 得到的分割结果。

对比可以很明显看到:在 16 倍还原和 8 倍还原时,能够看到更好的细节,32 倍还原出来的图,在边缘分割和识别上,虽然大致的意思都出来了,但细节部分(边缘)真的很粗糙,甚至无法看出物体形状。
参考博客:http://blog.csdn.net/shenxiaolu1984/article/details/51348149
论文亮点:
不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
网络结构:
网络结构如下。输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21。
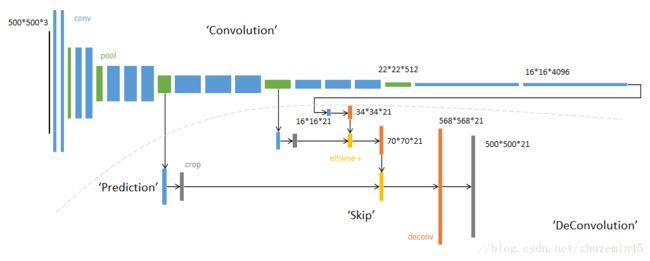
全卷积-提取特征
虚线上半部分为全卷积网络。(蓝:卷积,绿:max pooling)。对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变。
这部分由深度学习分类问题中经典网络AlexNet1修改而来。只不过,把最后两个全连接层(fc)改成了卷积层。
论文中,达到最高精度的分类网络是VGG16,但提供的模型基于AlexNet。此处使用AlexNet便于绘图。
逐像素预测
虚线下半部分中,分别从卷积网络的不同阶段,以卷积层(蓝色×3)预测深度为21的分类结果。
例:第一个预测模块
输入16*16*4096,卷积模板尺寸1*1,输出16*16*21。
相当于对每个像素施加一个全连接层,从4096维特征,预测21类结果。
反卷积-升采样
下半部分,反卷积层(橙色×3)可以把输入数据尺寸放大。和卷积层一样,升采样的具体参数经过训练确定。
例:反卷积2
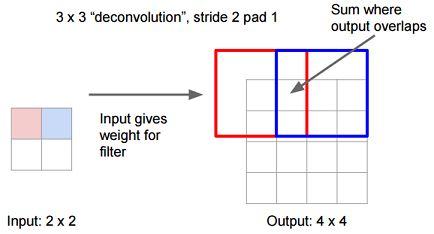
输入:每个像素值等于filter的权重
输出:步长为stride,截取的宽度为pad。
跳级结构
下半部分,使用逐数据相加(黄色×2),把三个不同深度的预测结果进行融合:较浅的结果更为精细,较深的结果更为鲁棒。
在融合之前,使用裁剪层(灰色×2)统一两者大小。最后裁剪成和输入相同尺寸输出。
训练
训练过程分为四个阶段,也体现了作者的设计思路,值得研究。
第1阶段
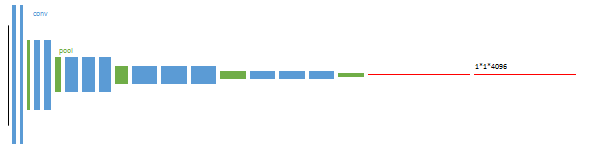
以经典的分类网络为初始化。最后两级是全连接(红色),参数弃去不用。
第2阶段
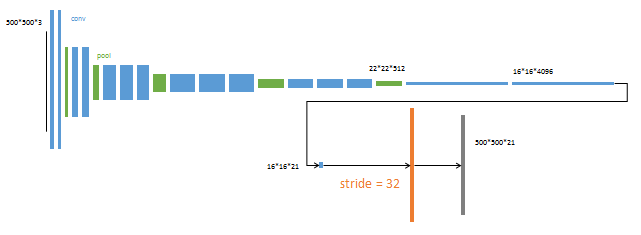
从特征小图(16*16*4096)预测分割小图(16*16*21),之后直接升采样为大图。
反卷积(橙色)的步长为32,这个网络称为FCN-32s。
这一阶段使用单GPU训练约需3天。
第3阶段
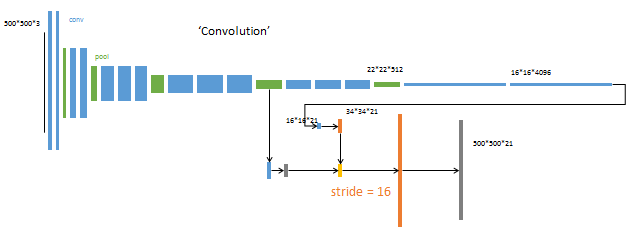
升采样分为两次完成(橙色×2)。
在第二次升采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。
第二次反卷积步长为16,这个网络称为FCN-16s。
这一阶段使用单GPU训练约需1天。
第4阶段
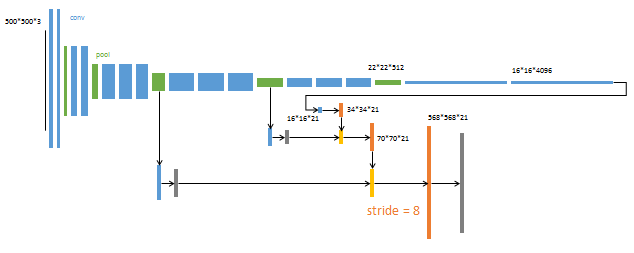
升采样分为三次完成(橙色×3)。
进一步融合了第3个pooling层的预测结果。
第三次反卷积步长为8,记为FCN-8s。
这一阶段使用单GPU训练约需1天。
较浅层的预测结果包含了更多细节信息。比较2,3,4阶段可以看出,跳级结构利用浅层信息辅助逐步升采样,有更精细的结果。
结论
总体来说,本文的逻辑如下:
- 想要精确预测每个像素的分割结果
- 必须经历从大到小,再从小到大的两个过程
- 在升采样过程中,分阶段增大比一步到位效果更好
- 在升采样的每个阶段,使用降采样对应层的特征进行辅助
类似思想在后续许多论文中都有应用,例如用于姿态分析的。