穿墙透视算法|MIT华人Team通过墙壁和遮挡物的超强动作检测模型
介绍
了解人们的行为和互动通常取决于看到他们。从视觉数据中自动进行动作识别的过程已成为计算机视觉界众多研究的主题。但是如果太暗,或者人被遮挡或在墙壁后面怎么办?在本文中,我们介绍了一个神经网络该模型可以在光线不足的情况下通过墙壁和遮挡物检测人类的行为。我们的模型将射频(RF)信号作为输入,生成3D人体骨骼作为中间表示,并随着时间的推移识别多个人的动作和互动。通过将输入转换为基于中间骨架的表示形式,我们的模型可以从基于视觉的数据集和基于RF的数据集中学习,并允许这两个任务互相帮助。我们表明,在可见场景中,我们的模型可以达到与基于视觉的动作识别系统相当的准确性,但是在看不见人的情况下,该模型仍可以继续正常工作,因此可以解决超出当今基于视觉的动作识别的局限性的场景。
先来看一组动图
墙后动作可识别
黑暗环境可识别
他们的模型将射频(RF)信号作为输入,生成3D人体骨架作为中间表示,并随着时间的推移识别多个人的动作和互动。
多人模式可识别
在本文中,我们旨在弥合两个世界。我们引入了RF-Action,这是一个端到端的深度神经网络,可以识别无线信号中的人类动作。它的性能可与基于视觉的系统相媲美,但可以穿过墙壁和遮挡物,并且对光照条件不敏感。图1显示了RF-Action在两种情况下的性能。在左侧,两个人握手,但其中一个被遮挡。基于视觉的系统将无法识别动作,而RF-Action轻松将其归类为握手。在右侧,一个人正在打电话,而另一个人将要向他扔东西。由于光线不佳,基于视觉的系统几乎看不到后者。相反,RF-Action可以正确识别两个动作。
RF-Action基于多模式设计,可与无线信号和基于视觉的数据集一起使用。我们利用最近的工作显示即推断人类骨骼(即,姿势)从无线信号的可行性 ,并采用骨架作为适合于RF和基于视觉的系统的中间表示。使用骨架作为中间表示是有利的,
因为:
(1)它使模型与RF和视觉数据来训练,并利用现有的基于视觉的三维骨骼数据集如PKU-MMD和NTU-RGB + d [ 26,31 ];
(2)它允许对中间骨骼进行额外的监督,从而有助于指导学习过程,而不仅仅是过去基于RF的动作识别系统中使用的单纯动作标签;
(3)由于骨架表示受环境或主体身份的影响最小,因此提高了模型推广到新环境和新人的能力。
我们通过两项改进其性能的创新进一步扩展了我们的模型:首先,骨骼,尤其是从RF信号生成的骨骼,可能会出现错误和错误预测。为了解决这个问题,我们的中间表示除了骨架之外还包括每个关节上随时间变化的置信度得分。我们使用自我关注来允许模型随着时间的推移以不同的方式关注不同的关节,具体取决于它们的置信度得分。
其次,过去的动作识别模型可以随时生成单个动作。但是,场景中的不同人可能会采取不同的动作,如图1右图所示,一个人在电话上交谈,而另一个人在扔物体。我们的模型可以使用专门设计用于解决此问题的多提案模块来解决此类情况。
为了评估RF-Action,我们使用无线设备和多摄像头系统收集了来自不同环境的动作检测数据集。该数据集跨越25个小时,包含30个执行各种单人和多人动作的个人。我们的实验表明,RF-Action在可见场景中的性能可与基于视觉的系统相媲美,并且在存在完全遮挡的情况下仍能继续保持良好的性能。具体来说,RF-Action在无遮挡的情况下可达到87.8的平均平均精度(mAP),在穿墙场景中的mAP为83.0。我们的结果还表明,多模式训练可以改善视觉和无线模式的动作检测。使用RF数据集和PKU-MMD数据集训练模型,我们观察到测试集的mAP性能从83.3提高到87。
贡献:本文有以下贡献:
-
它提出了第一个使用无线电信号进行基于骨骼的动作识别的模型;它进一步证明了这种模型可以仅使用RF信号(如图1所示)就可以准确识别穿过墙壁的动作和相互作用,并且在极端恶劣的照明条件下。
-
本文提出了“骨架”作为跨各种形式来传递与动作识别相关的知识的中间表示,并通过经验证明这种知识传递可以提高绩效。
-
本文介绍了一个新的时空注意模块,该模块改进了基于骨骼的动作识别,而不管骨骼是从RF还是基于视觉的数据生成的。
-
它还提出了一种新颖的多提案模块,该模块扩展了基于骨骼的动作识别以检测多个人同时进行的动作和互动。

该图显示了我们系统的两个测试用例。在左侧,两个人握手,而其中一个在墙后。在右边,一个人躲在黑暗中,向另一个正在打电话的人扔东西。底行显示了由我们的模型生成的骨骼表示和动作预测。
相关知识
(a)基于视频的动作识别:
在过去的几年中,从视频中识别动作一直是一个热门话题。早期方法使用手工制作的功能。为实例,像HOG和SIFT图像描述符已经被扩展到3D 来提取视频时间线索。此外,诸如改进的密集轨迹(iDT)之类的描述符是专门设计用来跟踪视频中的运动信息的。
最新的解决方案基于深度学习,分为两大类。
第一类通过利用三维卷积网络提取运动和外观特征共同。
第二类分别通过使用两个流神经网络考虑空间特征和时间特征。
(二)基于骨架行为识别:基于骷髅动作识别最近获得广泛关注。这种方法具有多个优点。
首先,骨骼为人类动态提供了一种强大的表现力来抵抗背景噪声[ 23 ]。
其次,与RGB视频相比,骨骼更为简洁,这减少了计算开销,并允许使用更小的模型来适合移动平台。
基于骨骼的动作识别的先前工作可以分为三类。早期工作使用递归神经网络(RNN)对骨架数据中的时间依赖性进行建模。
然而,最近,文献转向了卷积神经网络(CNN),以学习时空特征并取得了令人印象深刻的性能。
此外,某些文件表示的骨架作为动作识别图形和利用图形神经网络(GNN)。
在我们的工作中,我们采用基于CNN的方法,并通过引入时空注意模块来处理从无线信号生成的骨骼,并在多提案中扩展了分层共现网络(HCN)模型。
模块以同时启用多个动作预测。
(C)无线电的基于动作的识别:
研究在无线系统中已经使用无线电信号探索动作识别,特别是用于家庭应用,其中隐私问题可以排除使用摄像机 。
这些作品可以分为两类:
第一类类似于RF-Action,因为它可以分析从人体反弹的无线电信号。他们用行动标签监督,简单分类。
他们只能识别简单的动作(例如步行,坐着和跑步),最多只能识别10个不同的动作。
而且,它们仅处理单人场景。
第二类依赖于传感器网络。
他们或者部署不同传感器,用于不同的动作,(例如,在冰箱门上的传感器可检测的饮食),或贴在每个主体部的可穿戴式传感器和基于其上的身体部位移动识别被摄体的动作。
这样的系统需要对环境或人的大量检测,这限制了它们的实用性和鲁棒性。
射频信号入门

同时记录RF热图和RGB图像。
我们使用在过去的工作常用于基于RF的动作识别一种类型的无线电的。
无线电会产生一个称为FMCW的波形,并在5.4至7.2 GHz之间工作。
该设备具有垂直和水平排列的两个天线阵列。
因此,我们的输入数据采用二维热图的形式,一个来自水平阵列,一个来自垂直阵列。如图2所示,水平热图是无线电信号在平行于地面的平面上的投影,而垂直热图是信号在垂直于地面的平面上的投影(红色表示大值,蓝色表示小值)。直观地,较高的值对应于来自某个位置的信号反射的强度更高。
无线电以30 FPS的帧速率工作,即每秒产生30对热图。
如图所示,RF信号与视觉数据具有不同的属性,这使基于RF的动作识别成为一个难题。尤其是:
穿过壁的频率中的RF信号的空间分辨率低于视觉数据。在我们的系统中,深度分辨率为10 cm,角度分辨率为10度。如此低的分辨率使得难以区分诸如挥手和梳头等活动。
人体在穿过墙壁的频率范围内镜面反射。RF镜面反射是当波长大于表面粗糙度时发生的物理现象。
在这种情况下,与散射体相反,物体的作用就像反射镜(即镜子)。我们收音机的波长约为5厘米,因此人类可以充当反射器。
根据每个肢体表面的方向,信号可能会反射到我们的传感器或远离我们的传感器。
反射信号远离无线电的肢体对于设备来说是不可见的。即使信号被反射回收音机,但表面较小的肢体(例如手)也会反射较少的信号,因此更难追踪。
尽管RF信号可以穿过墙壁,但它们穿过墙壁时的衰减明显大于通过空气的衰减。结果,当人在墙壁后面时,从人体反射的信号较弱,因此,在存在墙壁和闭塞的情况下,检测动作的准确性降低。

RF-Action架构。RF-Action从无线信号中检测人为行为。它首先从原始无线信号输入(黄色框)中提取每个人的3D骨架。然后,它对提取的骨架序列(绿色框)执行动作检测和识别。动作检测框架还可以将从视觉数据生成的3D骨架作为输入(蓝色框),从而可以使用RF生成的骨架和现有的基于骨架的动作识别数据集进行训练。
方法
RF-Action是一种端到端的神经网络模型,可以通过遮挡和不良照明来检测人类行为。
模型架构如图所示,该模型将无线信号作为输入,生成3D人体骨骼作为中间表示,并随着时间的推移识别多个人的动作和交互。
该图进一步显示,RF-Action还可以获取从视觉数据生成的3D骨架。
这允许RF-Action与现有的基于骨骼的动作识别数据集一起训练。
在本节的其余部分中,我们将描述如何将无线信号转换为3D骨架序列,以及如何从此类骨架序列(即图3中的黄色和绿色框)推断动作。从多相机系统到3D骨架转化可视数据可以通过使用像AlphaPose的算法提取图像的二维骨架,然后进行三角测量的2D关键点,以生成三维骨架来完成。
a.无线信号的骨架生成
为了从无线信号生成人体骨骼,我们采用其中的架构。具体来说,骨架生成网络(图中橙色框)的水平和垂直热图的形式接收无线信号。
,并生成多人3D骨架。网络的输入是水平和垂直热图的3秒窗口(90帧)。该网络由三个通常用于姿势/骨架估计的模块组成。
首先,包括时空卷积的特征网络从输入的RF信号中提取特征。然后,将提取的特征通过区域提议网络(RPN)以获得针对可能的骨架边界框的多个提议。最终,将提取的提案输入3D 姿势估计子网,以从每个提案中提取3D骨架。
b.与模式无关的动作识别
如图所示,与模式无关的动作识别框架使用从RF信号生成的3D骨架来执行动作检测。
输入:我们首先跨时间关联骨骼以获取多个骨骼序列,每个序列都来自一个人。每个骨骼都由关键点(肩膀,手腕,头部等)的3D坐标表示。由于无线电信号的特性,不同的关键点在不同的时间实例反射不同数量的无线电信号,从而导致对关键点位置的置信度发生变化(跨时间和跨关键点)。
因此,我们将骨架生成网络的预测置信度用作每个关键点的另一个输入参数。因此,每个骨架序列都是大小为4 × T × N j的矩阵,其中4表示空间尺寸加上置信度T是序列中的帧数,并且N j对应于骨架中关键点的数量。
模型:我们的动作检测模型(图3中的绿色大框))具有以下三个模块:
1)基于注意力的特征学习网络,该网络从每个骨架序列中提取高级时空特征。
2)然后,我们将这些功能传递给多提案模块以提取提案-即每个与操作的开始和结束相对应的时间窗口。我们的多提案模块包含两个提案子网:一个用于为单人操作生成提案,另一个用于两人互动。
3)最后,我们使用生成的提案对相应的潜在特征进行裁剪和调整大小,并将每个裁剪后的动作段输入到分类网络中。分类网络首先通过执行2-way分类来确定此持续时间是否包含动作,从而改进时间建议。
接下来,我们详细描述注意力模块和多提案模块。
时空注意模块
我们学习使用基于时空注意力的网络进行动作识别的功能。我们的模型基于分层共现网络(HCN)。
HCN使用两种卷积流:对骨架关键点进行操作的空间流,以及随时间变化对骨架关键点的位置进行更改的时间流。HCN连接这两个流的输出,以从输入骨架序列中提取时空特征。然后使用这些功能来预测人类的行为。
但是,从无线信号预测的骨骼可能不如人类标记的骨骼那么准确。同样,不同的关键点可能具有不同的预测误差。为了使我们的动作检测模型专注于具有更高预测置信度的身体关节,我们引入了时空注意力模块。
具体来说,我们定义可学习的掩码权重W m,并在每个步骤将其与潜在的空间特征f s和时间特征f t进行卷积:
M a s k = C o n v (c o n c a t (f s,f t),W m)。
然后,我们将M a s k应用于潜在特征,如图所示。通过这种方式,面罩可以学习为不同的关节提供不同的重量,以获得更好的动作识别性能。我们还添加了一个多头注意力模块。
在特征提取后的时间维度上学习不同时间戳的注意。
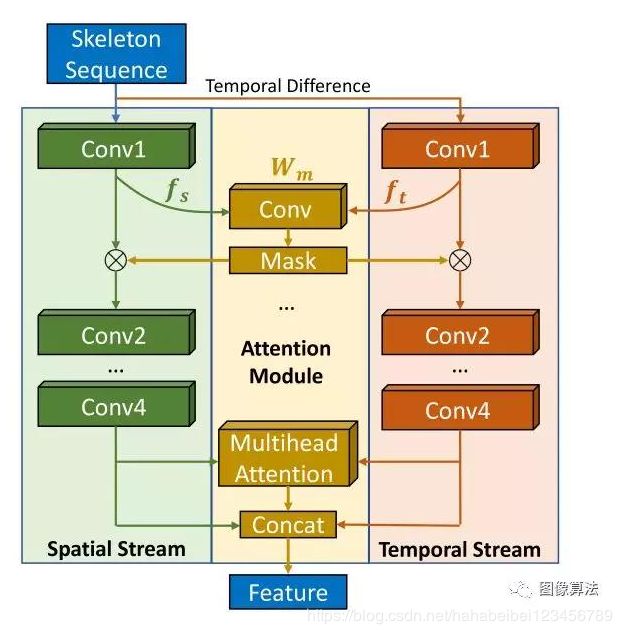
时空注意模块。我们建议的注意力模块(黄色框)学习面具,使模型更专注于身体关节,并具有更高的预测置信度。它还使用多头注意力模块来帮助模型更多地参与有用的时间实例。
多方案模块
以前的大多数动作识别数据集在任何时间都只有一个动作(或交互作用),而不管存在的人数如何。
结果,先前的骨架动作识别方法无法处理多个人同时执行不同动作的情况。
当场景中有多个人时,他们只是简单地对从每个人提取的特征进行最大化,然后转发结果组合的特征以输出一个动作。
因此,他们一次只能预测一个动作。
但是,在我们的数据集中,当场景中有多个人时,他们可以随时执行任何操作或彼此互动。
因此,在许多情况下,多个人同时在做动作和互动。
我们通过多提案模块解决了这个问题。具体来说,表示N是同时出现的人数。而不是执行的MAX-汇集了N个功能,我们的多提案模块输出 N + ( N 2)来自这N个功能的提案,对应于N个可能的单人操作和( N2)每两个人之间可能的互动。
我们的多提案模块使我们能够同时输出多个动作和交互。
最后,我们采用优先级策略,以优先于单人操作进行交互。
例如,如果同时存在“指向某物”(单人)和“指向某人”(互动)的预测,那么我们的最终预测将是“指向某人”。
多模式端到端培训
由于我们想以端到端的方式训练模型,因此我们不再可以使用argmax可以提取3D关键点位置,就像过去基于RF的姿势估计 [45]一样。因此,我们使用回归器来执行 arg的功能max提取每个关键点的3D位置。这使模型具有可区分性,因此动作标签也可以充当对骨架预测模型的监督。
我们的端到端架构使用3D骨架作为中间表示,这使我们能够利用以前基于骨架的动作识别数据集。
我们通过以下方式组合不同的模式来训练我们的模型:对于无线信号数据集,梯度在整个模型中向后传播,并用于调整骨架预测模型和动作识别模型的参数;
对于以前的基于骨骼的动作识别数据集,梯度会向后传播直到骨骼,然后将它们用于调整动作识别模块的参数。
如实验部分所示,这种多模式训练显着增加了数据多样性并改善了模型的性能。

定性结果。该图显示了RF-Action在各种情况下的输出。前两行显示了模型在可见场景中的性能。最下面的两行显示了我们模型在部分/完全遮挡和不良光照条件下的性能。所示的骨架是由我们的模型生成的中间3D骨架的2D投影。
实验
数据集
由于没有可用的动作检测数据集提供RF信号和相应的骨骼,因此我们收集了我们自己的数据集,我们将其称为RF多模态数据集(RF-MMD)。
我们使用无线电设备收集RF信号,并使用具有10个不同视点的摄像头系统收集视频帧。
无线电设备和摄像头系统在10毫秒内同步。
附录A包含对我们的数据收集系统的更详细描述。
我们在10个不同环境中(包括办公室,休息室,走廊,走廊,演讲室等)与30名志愿者收集了25小时的数据。我们从PKU-MMD的行动集中选择了35个行动(29个单一行动和6个互动)。
对于每10分钟的数据,我们要求最多3名志愿者从上述集合中随机执行不同的操作。
平均而言,每个样本包含1.54名志愿者,每个志愿者在10分钟内执行43项操作,每项操作耗时5.4秒。
我们使用20个小时的数据集进行训练,并使用5个小时进行测试。
该数据集还包含2种通透方案,其中一种用于训练,一种用于测试。对于这些穿墙环境,我们将摄像头放在墙壁的每一侧,以便可以使用无线电设备对摄像头系统进行校准,并使用可以看到人员的摄像头来标记动作。
RF-MMD上的所有测试结果仅使用无线电信号,而无需基于视觉的输入。
我们使用多视角相机系统提取3D骨架序列。
我们首先将AlphaPose 应用于我们的相机系统收集的视频,以提取多视图2D骨架。
由于场景中可能有多个人,因此我们将每个视图的2D骨架关联起来,以获得每个人的多视图2D骨架。
之后,由于我们的相机系统已经过校准,因此我们可以对每个人的3D骨骼进行三角剖分。这些3D骨架充当我们模型生成的中间3D骨架的监督。
最后,我们利用PKU-MMD数据集提供其他训练示例。
该数据集允许进行动作检测和识别。它包含由66个主体执行的来自51个类别的近20,000个动作。该数据集使我们能够展示RF-Action如何从基于视觉的示例中学习。
设定
在基于视频的动作检测文献中称为共同和骨架为基础的行动检测,我们评估我们的模型的使用在不同交叉点中值平均精度(MAP)的性能联盟之上(IoU)阈值θ。我们报告了mAP在θ = 0.1和θ = 0.5时的结果。
要对我们提出的RF-Action模型进行端到端训练,我们需要两种类型的地面真相标签:3D人体骨骼来监督我们的中间表示,以及动作开始-结束时间和类别来监督模型的输出。使用AlphaPose和先前描述的多视图相机系统对3D骨骼进行了三角剖分。至于动作的持续时间和类别,我们使用多视角摄像头系统手动对每个人的动作进行分段和标记。
定性结果
显示的定性结果说明了在各种情况下RF-Action的输出。
该图显示,即使不同的人同时执行不同的动作,RF-Action仍可以正确检测动作和交互,并且可以应对遮挡和恶劣的照明条件。因此,它解决了当今动作识别系统的多个挑战
不同型号的比较
我们将RF-Action的性能与基于骨架的动作识别和基于RF的动作识别的最新模型进行了比较。我们将HCN用作计算机视觉中性能最高的基于骨骼的动作检测系统的代表。
当前,它在此任务上达到了最佳准确性。
我们使用Aryokee 作为基于RF的动作识别技术的代表。据我们所知,这是过去唯一基于RF的动作识别系统,除了分类之外还执行动作检测。
原始的Aryokee代码适用于两个类别。因此,我们扩展了支持更多的课程。所有模型都在我们的RF动作识别数据集中进行了训练和测试。由于HCN将骨骼作为输入(与RF信号相反),因此我们为它提供了RF-Action生成的中间骨骼。这使我们可以在基于相同骨架的动作识别方面将RF-Action与HCN进行比较。

RF-MMD数据集上的模型比较。该表显示了在不同IoU阈值θ下可见光和穿墙场景中的mAP 。由于HCN在骨骼上运行,并且为了公平起见,我们向其提供由RF-Action生成的基于RF的骨骼
该表显示了在可见场景和穿墙场景下以无线信号作为输入进行测试的结果。如表所示,在两种测试条件下,RF-Action的性能均优于HCN。这表明了我们提出的模块的有效性。此外,我们还可以看到,在可见光和穿墙场景中,RF-Action的性能都大大优于Aryokee。这表明来自骨骼的额外监督以及RF-Action神经网络设计对于使用RF数据提供准确的性能非常重要。
不同模式的比较
接下来,我们研究在基于RF的骨骼与基于视觉的骨骼上操作时,RF-Action的性能。和以前一样,我们在训练集上训练RF-Action。但是,当进行推理时,我们要么向它提供来自测试集的输入RF信号,要么为它提供使用相机系统获得的可见地面真相骨架。表2显示了不同输入方式的结果。该表显示,对于可见的场景,对摄像机系统中的地面真实骨骼进行操作只会导致精度提高百分之几。这是可以预期的,因为RF骨架是使用基于视觉的骨架作为基本事实来训练的。此外,正如我们在实验设置中所述,基于摄像头的系统使用10个视点来估计3D骨架,而只有一个无线设备用于基于RF的动作识别。该结果表明,基于RF的动作识别可以实现接近经过精心校准的10个视点的摄像头系统的性能。该系统在穿墙场景中仍然可以正常工作,尽管由于信号在穿过墙时会受到一定程度的衰减,因此精度降低了百分之几。

在不同IoU阈值θ下,基于RF的骨骼(RF-MMD)和基于视觉的骨骼(GT骨骼)的RF动作性能(mAP)
动作检测
在图中,我们显示了测试集上动作检测结果的代表性示例。这个实验有两个人参加。他们有时会独立执行动作,或彼此互动。第一行显示第一人称的动作持续时间,第二行显示第二人称的动作持续时间,第三行显示它们之间的交互。我们的模型可以高精度地检测每个人的动作以及他们之间的互动。这清楚地表明,在多个人独立执行某些动作或彼此交互的情况下,我们的多提案模块具有良好的性能

测试集上的动作检测结果示例,其中两个人正在做动作以及彼此交互。实地行动部分以蓝色绘制,而使用我们的模型检测到的部分以红色绘制。水平轴是指帧号。
结论
本文介绍了第一个使用无线电信号进行基于骨骼的动作识别的模型,并证明了该模型可以识别在墙壁和极端恶劣的光照条件下的动作和相互作用。新模型可在由于隐私问题或可见性差而难以使用相机的环境中实现动作识别。因此,它可以将动作识别带入人们的家中,并允许其集成到智能家居系统中。
相关论文源码下载地址:关注“图像算法”微信公众号,回复穿墙术