参考图书:《高性能MYSQL》
1.数据库索引的特点
1.1 索引的有效范围
因为索引一般使用BTree做数据存储结构,索引查询的有效范围为:
1.全值匹配;
2.匹配最左前缀;
3.匹配列前缀
4.匹配范围值;
5.精确匹配一列并范围匹配另外一列;
6.只访问索引的查询;
2.聚簇索引 和非聚簇索引
2.1 什么是聚簇索引
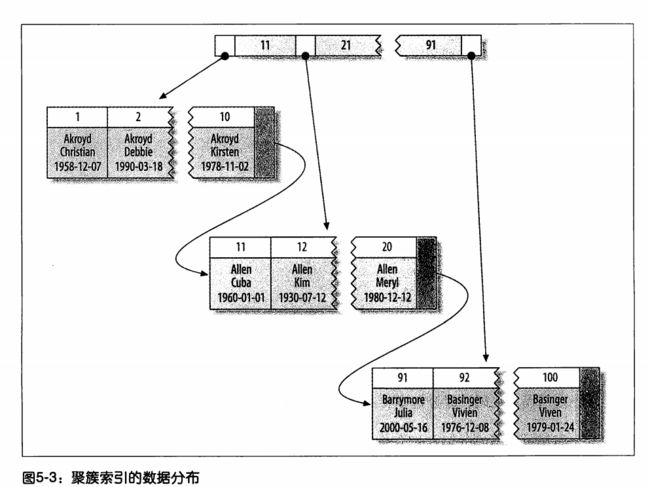
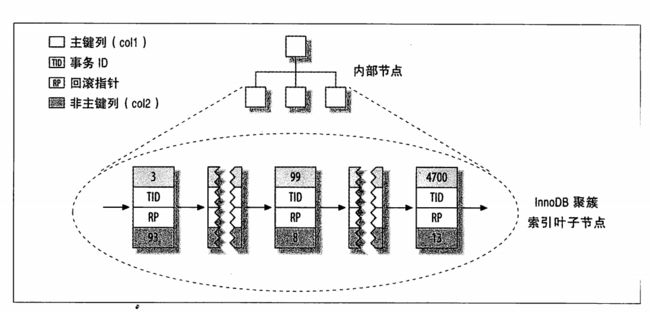
聚簇索引是一种数据存储方式。聚簇索引的所有数据都放在它的叶子节点。一个表只有一个聚簇索引。
innodb默认是主键为聚簇索引,如果没有主键,innodb会隐式的创建一个主键作为聚簇索引。
如下图所示:
优点:
1.数据存储在一个位置;查询速度比较快,提高了I/O密集型应用的性能;
缺点:
1.不适合做内存存储。
2.插入速度依赖于插入的顺序。
3.插入新行或者主键新增移动行时,面临页分裂的情况。
2.2 聚簇索引二级索引(非聚簇索引)
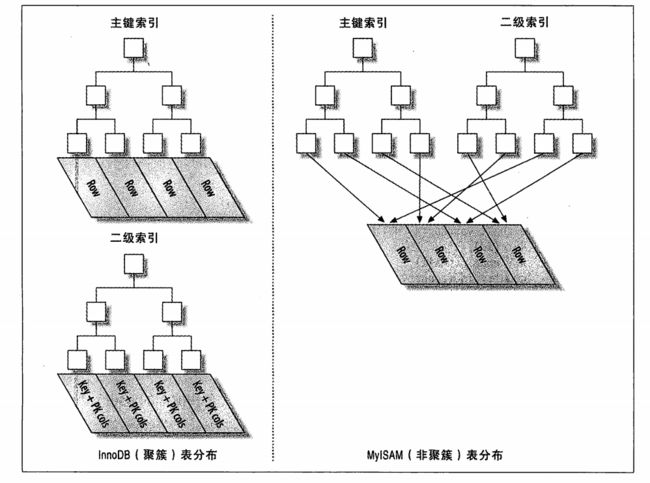
Innodb和Myism的二级索引存储数据会有很大的差别。
Innodb是叶子节点存储的是主键,作为指向行的指针,好处在于减少行移动,或者数据页分裂的二级索引的维护工作。
非聚簇索引和聚簇索引不同的是,非聚簇索引的子叶节点存储的是主键,和索引列的值。(图中的 key + pk cols)
2.组合索引
2.1 要注意的点
1.索引的最左匹配原则
假如创建了索引(ABC)三列
| 索引组合 | 是否有效 | 备注 |
|---|---|---|
| (ABC)、(AB)、(AC) | 有效 | |
| (BC) | 无效 |
2.范围查询后的列无法使用索引
create index produ_index on produ(type,sub_name,sub_id);
select type,num from produ where type='fruit' and sub_name like 'ap%' and sub_id='235948'
2.2 索引顺序的选择
1.通常情况,选择性高(重复度低)的放在前面。
- 如何判断多个索引列重复度?
select count(distinct type)/count(1) as type_selectity,
count(distinct sub_name)/count(1) as name_selectity,
count(distinct sub_id)/count as sub_id_selectity
from produ
查询出来的数值越小,就在前面
3.创建索引注意的问题
3.1避免创建重复索引
重复索引,是指创建列和列顺序相同的索引。这样会造成MYSQL索引进行筛选,降低性能。
3.2避免创建冗余索引
冗余索引,例如创建了一个索引(A,B),根据索引的最左原则,再创建索引(A)就属于冗余索引。