Mask RCNN源码的使用(测试+训练)
参考:
mask rcnn训练自己的数据集:https://blog.csdn.net/qq_29462849/article/details/81037343
mask rcnn实现教程:https://blog.csdn.net/wjd1994/article/details/79326088
Mask RCNN 实战(一)--代码详细解析:https://blog.csdn.net/ghw15221836342/article/details/80084984
本文为本人对较多介绍Mask RCNN源码使用博客的总结,添加了自己在实践中遇到的问题与解决方案。
写在最前面:测试与训练的图像都必须为3通道24位图像!否则训练时会报IndexError,测试时会报ValueError。(说多了都是泪!)
这里附上本人略微修改过的源码与“mask_rcnn_coco.h5”文件的百度云链接:
链接:https://pan.baidu.com/s/1zxL2Hy4SdUYwalyxNgOUhg
提取码:4jjr
文件说明 :在源码中添加了如下文件:1、test.py为测试代码,基于coco数据集上训练好的模型,选取images文件夹下任意文件进行预测(亦可直接调用摄像头获取图像并进行预测);2、test2.py为测试代码,使用自己训练所得权重预测指定图像;3、mrcnn文件夹下,添加了visualize2.py文件,里边改写了display_instances函数,将其改为save_result函数,用于保存预测所得图像结果,函数输入的参数与display_instances函数相同;4、train_model.py为模型训练代码。
下文会根据这些文件进行说明!
一、环境配置
- Mask R-CNN是基于Python3,Keras,TensorFlow。
- Python 3.4+
- TensorFlow 1.3+
- Keras 2.0.8+
- Jupyter Notebook
- Numpy, skimage, scipy, Pillow, cython, h5py
方法一:(我没试过,不过好像更方便)
1、下载完源码后,安装依赖关系:
pip3 install -r requirements.txt
2、克隆这个存储库
3、从存储库根目录运行安装程序
python3 setup.py install
方法二:(我用的这种方法)
运行如下代码,根据提示安装相应的库
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
import coco
import utils
import model as modellib
import visualize
其中,对于pycocotools库安装方法如下:
git clone https://github.com/pdollar/coco
cd coco/PythonAPI
将makefile中的python 改为python3
然后先运行安装python3-dev
然后命令行输入
make -j8
然后将pycocotools文件夹复制到mask-rcnn下
最后再sudo pip3 install h5py
二、测试
环境配置完成后,直接运行测试文件python test.py进行测试。
在进行测试自己的图像或权重时,需修改test2.py文件。首先需注意对根目录路径ROOT_DIR、模型路径MODEL_DIR的修改,其次需修改test.py中部分代码:
# 若使用自己训练的权重,需修改权重.h5文件路径
COCO_MODEL_PATH = os.path.join(MODEL_DIR ,"mask_rcnn_coco.h5")
class ShapesConfig(Config):
# Give the configuration a recognizable name
NAME = "shapes"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # background + 类别数
# 根据不同的训练任务,将 NUM_CLASSES设为 1+训练类别数,1表示背景,不可删去!
class_names = ['BG','car'] # 设置自己的类别;'BG'表示背景类,不可删除;
预测图像的路径修改如下:
# 测试时可用该行代码,表示从imags文件夹中任意读取一张图像进行预测
#file_names = next(os.walk(IMAGE_DIR))[2]
#image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))
# 若需指定预测图像,可用该行代码
image = skimage.io.imread(os.path.join(IMAGE_DIR, '1.jpg'))
若需保存所得结果,在测试代码最后添加:
from mrcnn import visualize2
visualize2.save_result(image, r['rois'], r['masks'], r['class_ids'],
class_names, r['scores'])
三、训练自己的数据集
1、数据集制备
1)利用软件labelme标注数据(标注过程自动生成json文件)
labelme的使用参考:https://blog.csdn.net/shwan_ma/article/details/77823281
注:相同类别的目标,使用‘label+数字’的形式标注,如‘car1’,‘car2’,如下图所示:
否则预测阶段会将预测所得所有mask当成一个目标,如下第一张图为预期测试效果,第二张图为实际测试效果。(此两张图只是示意图,原图已删,说多了还是泪~)


2)利用如下代码,批量处理生成的json文件:
import os
path = '/media/data/json' # 该路径为json文件存放路径
json_file = os.listdir(path)
for file in json_file:
os.system("labelme_json_to_dataset %s"%(path + file))
将所得文件夹保存至labelme_json文件夹下。
3)将labelme_json文件夹中所有文件夹内的label.png图像拷至cv2_mask文件夹下,命名与pic文件夹下图像相同。需保证label.png为8位图像,若为24位图像需进行转换。(查看图像位深度:windows操作系统下,查看图像属性->详细信息->位深度)
最终所得数据集如下:
train_dataset: pic:
pic: json:labelme_json:
json:labelme_json: cv2_mask:
cv2_mask:
2、训练模型
最终所得文件夹设置如下:
开始训练前,需注意train_model.py中根目录路径ROOT_DIR、模型路径MODEL_DIR的修改。
将作为初始权重的.h5文件放在logs文件夹下,最终训练所得的训练误差与权重也会保存在logs文件夹下(即模型路径MODEL_DIR,最终保存的文件较多较大,建议将此路径另设在一个剩余空间较大的盘中)。
另外,针对不同的训练任务,需对train_model.py文件修改如下(此处并未列出完整代码):
#设置使用的初始权重
COCO_MODEL_PATH = os.path.join(MODEL_DIR, "mask_rcnn_coco.h5")
class ShapesConfig(Config):
# Give the configuration a recognizable name
NAME = "shapes"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # background + 类别数
# 根据不同的训练任务,将 NUM_CLASSES设为 1+训练类别数,1表示背景,不可删去!
class DrugDataset(utils.Dataset):
def load_shapes(self, count, img_floder, mask_floder, imglist, dataset_root_path):
# Add classes 根据自己的训练任务,添加或删除 self.add_class( )
self.add_class("shapes", 1, "car")
#self.add_class("shapes", 2, "leg")
#self.add_class("shapes", 3, "well")
def load_mask(self, image_id):
for i in range(len(labels)):
# 同理,根据自己的训练任务,修改如下代码
if labels[i].find("car") != -1:
# print "car"
labels_form.append("car")
'''
elif labels[i].find("leg") != -1:
# print "leg"
labels_form.append("leg")
elif labels[i].find("well") != -1:
# print "well"
labels_form.append("well")
'''
最后在根目录下,运行python train_model.py即可开始训练。训练过程中和训练结束后,都会在模型路径MODEL_DIR下存有训练所得权重.h5文件。
3、观察损失
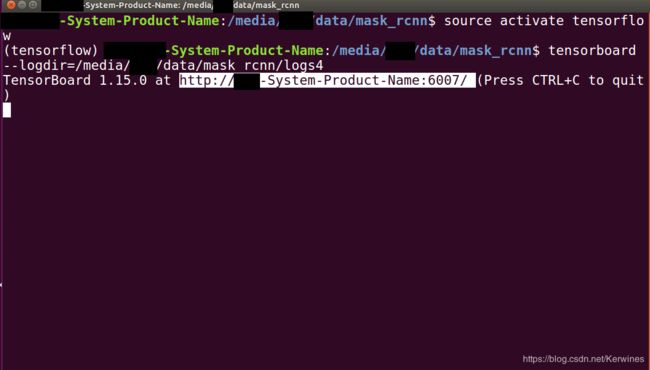
训练过程中,在新的命令行中输入
tensorboard --logdir = 模型路径MODEL_DIR
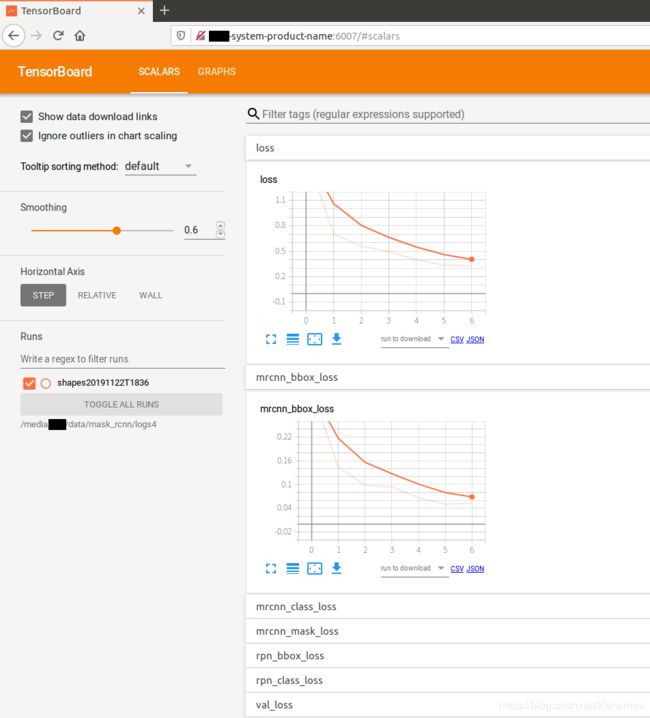
将所得网址粘贴至浏览器中(注意不要按ctrl+c复制!),可观察训练过程中的误差变化。
完结!完结!!撒花!撒花!!