编译原理:C语言词法分析器
编译原理的实验:完成对C语言的词法分析
先说一下整体框架:
基类:Base 封装了一些基础的字符判断函数,如下:
int charkind(char c);//判断字符类型
int spaces(char c); //当前空格是否可以消除
int characters(char c);//是否是字母
int keyword(char str[]);//是否是关键字
int signwords(char str[]);//是否是标识符
int numbers(char c);//是否是数字
int integers(char str[]);//是否是整数
int floats(char str[]);//是否是浮点型派生类 LexAn 继承Base并且封装了对行和单词处理的函数,如下:
void scanwords(); //处理每一行
void clearnotes();//清除注释和多余的空格
void getwords(int state);//处理出单词
void wordkind(char str[]);//判断单词类型并且输出函数之间调用关系如下:
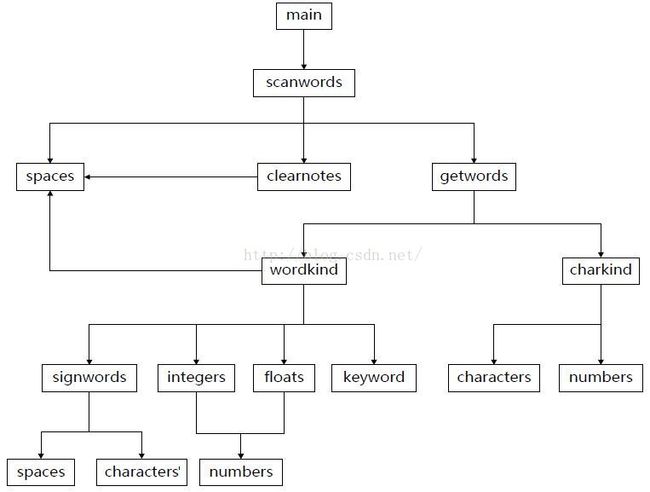
好了,整体框架说完了,我们来说具体的实现:
(一)清除注释和多余的空格
(1)C语言的注释有//和/* 两种形式,所以如果当前读进的是 / 只需分情况判断下一个:
如果是/ 那么本行 //之后的肯定都是注释,只需要保存注释,更新当前行即可;
如果是* ,那么接着寻找直至 */位置,保存注释,更新当前行,然后继续这个操作(有可能有本行有多个 /* */).
不足:不能处理跨行注释。
(2)处理多余的空格这里较为草率,只处理了形如if ( a >= b ),即特殊符号和字母(数字)之间的空格;只要空格两端有特殊符号,那么去掉当前空格便不会造成错误。
void LexAn::clearnotes()
{
int i, j, k;
int noteCount = 0;
int flag = 0;
char note[100];
/*注释*/
for (i = 0; bufferin[buffernum][i] != '\0'; i++)
{
if (bufferin[buffernum][i] == '"')
{
flag = 1 - flag;
continue;
}
if (bufferin[buffernum][i] == '/' && flag == 0)
{
if (bufferin[buffernum][i + 1] == '/')
{
for (j = i; bufferin[buffernum][j] != '\0'; j++)
{
note[noteCount++] = bufferin[buffernum][j];
}
note[noteCount] = '\0';
noteCount = 0;
fprintf(fout, " [ %s ] ---- [ 注释 ]\n", note);
bufferin[buffernum][i] = '\0';
break;
}
if (bufferin[buffernum][i + 1] == '*')
{
note[noteCount++] = '/';
note[noteCount++] = '*';
for (j = i + 2; bufferin[buffernum][j] != '\0'; j++)
{
note[noteCount++] = bufferin[buffernum][j];
if (bufferin[buffernum][j] == '*' && bufferin[buffernum][j + 1] == '/')
{
j += 2;
note[noteCount++] = bufferin[buffernum][j];
note[noteCount] = '\0';
noteCount = 0;
fprintf(fout, " [ %s ] ---- [ 注释 ]\n", note);
break;
}
}
for (; bufferin[buffernum][j] != '\0'; j++, i++)
{
bufferin[buffernum][i] = bufferin[buffernum][j];
}
if (bufferin[buffernum][j] == '\0')
{
bufferin[buffernum][i] = '\0';
}
}
}
}
//空格
for (i = 0, flag = 0; bufferin[buffernum][i] != '\0'; i++)
{
if (bufferin[buffernum][i] == '"')
{
flag = 1 - flag;
continue;
}
if (bufferin[buffernum][i] == ' ' && flag == 0)
{
for (j = i + 1; bufferin[buffernum][j] != '\0' && bufferin[buffernum][j] == ' '; j++)
{
}
if (bufferin[buffernum][j] == '\0')
{
bufferin[buffernum][i] = '\0';
break;
}
if (bufferin[buffernum][j] != '\0' && ((spaces(bufferin[buffernum][j]) == 1) || (i > 0 && spaces(bufferin[buffernum][i - 1]) == 1)))
{
for (k = i; bufferin[buffernum][j] != '\0'; j++, k++)
{
bufferin[buffernum][k] = bufferin[buffernum][j];
}
bufferin[buffernum][k] = '\0';
i--;
}
}
}
//制表符
for (i = 0, flag = 0; bufferin[buffernum][i] != '\0'; i++)
{
if (bufferin[buffernum][i] == '\t')
{
for (j = i; bufferin[buffernum][j] != '\0'; j++)
{
bufferin[buffernum][j] = bufferin[buffernum][j + 1];
}
i = -1;
}
}
}(二)最重要的状态机的转化
画图不是很好话,我尽量用语言清除地描述,大家还需结合源码分析:
主要分为 <字母, 1> <数字, 2> <$ _ , 3> <4 ,/ >(转义) < = ,5> <0,else >
state初始值设为0:
(1)如果首位字符是字母,那么只可能是标识符和关键字,之后遇到除 数字,字母,$,_,之外的字符结束,取出单词。
(2)如果首位字符是数字,那么只能是数字,即八进制,十六进制,. ,数字,$ ,之后遇到除上述之外的字符结束,取出单词。
(3)如果首位是$ _ ,那么只能是标识符,即字母,数字,$,之后遇到除上述之外的字符结束,取出单词。
(4)如果首位是特殊字符(" . () = 等),那么再分开处理,流程和上述的一致,遇到不可能的组合结束;这部分看代码吧。
//状态机
void LexAn::getwords(int state)
{
char word[100];
int charCount = 0;
int finish = 0;
int num;
int i, j, k;
for (i = 0; bufferscan[i] != '\0'; i++)
{
switch (state / 10)
{
case 0:
switch (charkind(bufferscan[i]))
{
case 1:
word[charCount++] = bufferscan[i];
state = 10;
break;
case 2:
word[charCount++] = bufferscan[i];
state = 20;
break;
case 3:
word[charCount++] = bufferscan[i];
state = 30;
break;
case 0: case 5:
word[charCount++] = bufferscan[i];
switch (bufferscan[i])
{
case '"':
state = 41;
break;
case '\'':
state = 42;
break;
case '(': case ')': case '{': case '}': case '[': case ']': case ';': case ',': case '.':
state = 50;
word[charCount] = '\0';
finish = 1;
break;
case '=':
state = 43;
break;
default:
state = 40;
break;
}
break;
default: word[charCount++] = bufferscan[i]; break;
}
break;
case 1:
switch (charkind(bufferscan[i]))
{
case 1:
word[charCount++] = bufferscan[i];
state = 10;
break;
case 2:
word[charCount++] = bufferscan[i];
state = 20;
break;
case 3:
word[charCount++] = bufferscan[i];
state = 30;
break;
case 0:case 5:
word[charCount] = '\0';
num = 0;
while (word[num] != '\0')
num++;
//长度的处理 !!
if (num>7)
word[7] = '\0';
i--;
finish = 1;
state = 50;
break;
default: word[charCount++] = bufferscan[i]; break;
}
break;
case 2:
switch (charkind(bufferscan[i]))
{
case 1:
word[charCount++] = bufferscan[i];
state = 20;
break;
case 2:
word[charCount++] = bufferscan[i];
state = 20;
break;
case 3:
word[charCount++] = bufferscan[i];
state = 30;
break;
case 0:
if (bufferscan[i] == '.')
{
word[charCount++] = bufferscan[i];
state = 20;
break;
}
word[charCount] = '\0';
i--;
finish = 1;
state = 50;
break;
default: word[charCount++] = bufferscan[i]; break;
}
break;
case 3:
switch (charkind(bufferscan[i]))
{
case 1:
word[charCount++] = bufferscan[i];
state = 30;
break;
case 2:
word[charCount++] = bufferscan[i];
state = 30;
break;
case 3:
word[charCount++] = bufferscan[i];
state = 30;
break;
case 0:
word[charCount] = '\0';
i--;
finish = 1;
state = 50;
break;
default: word[charCount++] = bufferscan[i]; break;
}
break;
case 4:
switch (state)
{
case 40:
switch (charkind(bufferscan[i]))
{
case 1:
word[charCount] = '\0';
i--;
finish = 1;
state = 50;
break;
case 2:
word[charCount] = '\0';
i--;
finish = 1;
state = 50;
break;
case 3:
word[charCount] = '\0';
i--;
finish = 1;
state = 50;
break;
case 0:
word[charCount++] = bufferscan[i];
state = 40;
break;
default: word[charCount++] = bufferscan[i]; break;
}
break;
case 41:
word[charCount++] = bufferscan[i];
if (bufferscan[i] == '"')
{
if (charkind(bufferscan[i - 1]) == 4)
{
}
else
{
word[charCount] = '\0';
finish = 1;
state = 50;
}
}
break;
case 42:
word[charCount++] = bufferscan[i];
if (bufferscan[i] == '\'')
{
word[charCount] = '\0';
finish = 1;
state = 50;
}
break;
case 43:
if (bufferscan[i] == '=')
{
word[charCount++] = bufferscan[i];
state = 43;
}
else
{
word[charCount] = '\0';
finish = 1;
i--;
state = 50;
}
break;
default: word[charCount++] = bufferscan[i]; break;
}
break;
case 5:
finish = 0;
state = 0;
charCount = 0;
i--;
wordkind(word);
break;
default:break;
}
if (bufferscan[i + 1] == '\0')
{
word[charCount] = '\0';
wordkind(word);
}
}
}另外注意:应实验要求,对长度超过7的标识符直接截断。如果需要正常处理的话删掉代码中红色标注的部分即可。
(三)效果截图:

本项目全部源码放在个人 Github 上,欢迎大家star和fork学习哈。