决定参照这个教程来安装https://blog.csdn.net/zp8126/article/details/78249741
CentOS6.5 +JDK 1.8环境,用MobaXterm_v11.1操作
1.首先检查jdk安装情况
2.下载hadoop(hadoop版本选择?)

使用rz上传命令找不到的话要先下载,下面是成功了

MobaXterm使用rzhttps://blog.csdn.net/kq1983/article/details/95262378
貌似上传还是不行,但直接进入目录这样上传就可以了,如下:

你看,两种方式都能看到这个安装包



这里已经有了感觉![]()
格式化后



配置一直有点小问题,之前start-all.sh然后jps查看到的进程列表都只有DateNode和Jps
不懈努力地理解修改配置文件后,看下图都好了,但我不记得最后到底改的哪里弄好了。。。

hadoop web管理页面打不开,先试试https://blog.csdn.net/wang7807564/article/details/74528711

我说我怎么一直打不开web管理页面,太傻了,是要用虚拟机中centos6.5的浏览器打开,我一本正经在那儿用Window浏览器打开。。。
我先把两文件这里改成了这样匹配的样子
![]()

![]()
![]()
瞧!



开启yarn,这里的意思是已经开启了,要再开启得先关闭,所以现在直接浏览器打开就行


结束!(那个ssh免密码登录再弄吧)
关于hadoop集群启动后datanode没有启动问题,即jps后没有DataNodehttps://blog.csdn.net/huguihua2002/article/details/100079564
先保证hadoop集群是正确启动的,然后运行WordCount程序 https://blog.csdn.net/u012366219/article/details/78781382

上面警告的处理https://www.cnblogs.com/likui360/p/6558749.html


![]()

查看到结果

现在用IntelliJ Idea打包wordcount的mapreduce程序,然后传到装有hadoop的虚拟机系统上运行
参照此教程https://www.cnblogs.com/airnew/p/9540982.html,到要创建shell文件那里我开始有点迷糊了
然后到运行的时候又有这个问题
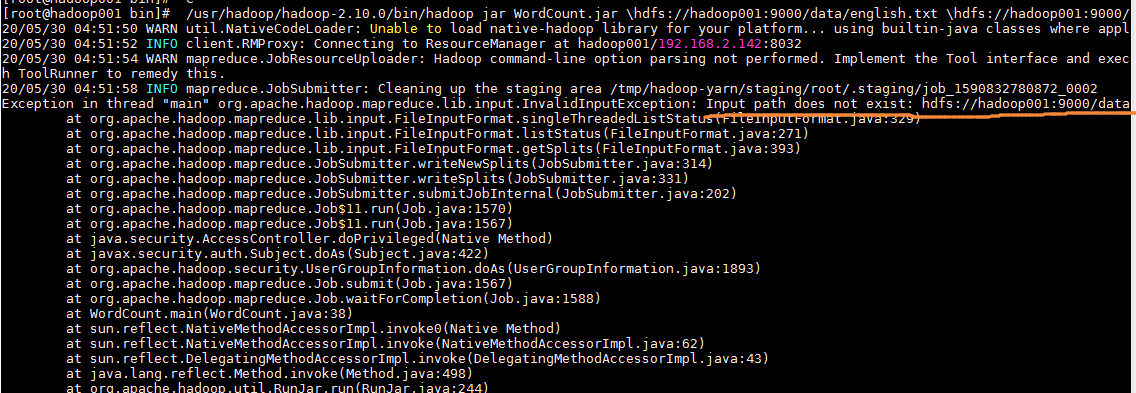
尝试用这个方法解决https://blog.csdn.net/weixin_34194317/article/details/86360351又有新问题

根据网友的问题解决方案,hadoop fs -rm -r /input删除这个文件夹,将执行命令反复再尝试了好几遍也不行,我执行的命令如下
hadoop fs -mkdir /input hadoop fs -put test.txt /input hadoop jar /usr/hadoop/hadoop-2.10.0/bin/WordCount.jar WordCount /input /output
放弃后继续查找经验https://blog.csdn.net/ASN_forever/article/details/81066282看到这里突然灵感一现:路径一致+输入输出改名

确保WordCount.jar包与输入输出文件在同一层次路径下后,然后我只输入下面代码,便成功了
hadoop jar WordCount.jar /input/test.txt /output4






代码改了下,又跑了下,感觉理解更深了些。
我把改后生成的WordCount.jar上传到了linux 的/wcdata文件夹中,本来这里面还又建了一个test.txt文档,但通过[root@hadoop001 wcdata]# hadoop jar WordCount.jar /input/test.txt /output命令后发现jar包虽然是使用的wcdata该文件夹中的,但是使用的输入文本却还是/usr/hadoop/hadoop-2.10.0/test.txt这里的,而不是/wcdata/test.txt这个,有点纳闷。




