Netty解读:高性能无锁队列Jctools源码分析
1. JDK BlockingQueue队列概述
在Java中用的最多队列的也就是BlockingQueue,所谓的Blocking就是入队或者出队时可能会产生阻塞,即没有元素或者容量已满。之所以是可能产生,是因为它支持多种操作,如add、offer等
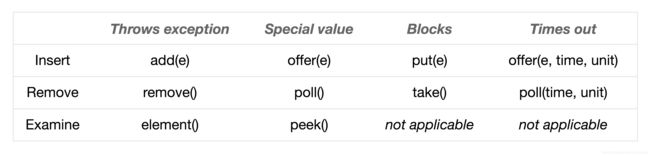
基本所有的实现类都遵循这种规则。支持多个生产者和消费者,并且是线程安全的。
ArrayBlockingQueue 是 BlockingQueue 接口的有界队列实现类,底层采用数组来实现。同步机制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。同时它是定长的,构造函数中必须传入容量。通过出队索引和入队索引的决定出入的元素。下面看下出队的take操作。
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
}
private E dequeue() {
final Object[] items = this.items;
E x = (E) items[takeIndex];
items[takeIndex] = null;
if (++takeIndex == items.length)
takeIndex = 0;
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal();
return x;
}
take操作会一直阻塞,直到队列中有元素或者线程被中断。取出元素之后通知加入元素的等待队列,put操作也类似。不同的是他们通过不同的Condition
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
}
private void enqueue(E x) {
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
同样加入元素之后,通知取元素的等待队列。
LinkedBlockingQueue底层基于单向链表实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用。如果构造函数中不传入容量则最大容量默认为int的最大值。内部通过对头和队尾的两个锁来控制并发。并且造执行构造函数的时候会初始化一个空节点,赋值给head和last,该节点不会计入容量。这里就不展开代码了。
JDK提供的队列都是比较通用的,适用于大多数的场景。但是能否支持高并发的环境,后面我们会给出测试的结果。早在96年就有论文提出了无锁队列的概念,再到后来Disruptor,高性能已得到生产的验证。此处介绍的将会是Jctools中的高性能队列,其性能丝毫不输于Disruptor。这里明确一点类名的前缀:Mpsc、Mpmc等,表示Multiple Producer Single/Multiple Producer consumer。并且任意一类队列在jctools中都有多种实现方式。
2. MpscArrayQueue
看名字也知道,它是通过数组来实现的,没错!更准确的说是环形数组,Jctools中的代码使用了大量的填充行,阅读源码体验较差。

这里可以忽略pad结尾的类,它的目的就是为了解决伪共享的问题。关于伪共享此处不再展开Java并发编程系列:漫谈伪共享。为了方便理解,笔者把属性放在一起
// 为了&计算下标,初始化值为:容量-1
protected final long mask;
// 存放数据的数组
protected final E[] buffer;
// 生产者的索引,可能大于数组的长度
private volatile long producerIndex;
// 生产者的下标的最大值,动态变化,用来判断队列是否已满
private volatile long producerLimit;
// 消费者的索引,可能大于数组的长度
protected long consumerIndex;
这五个变量都很容易理解,生产者的索引是指只有生产者会修改此值,每添加一个元素都会递增。消费者的索引也相同,可能会大于数组的长度是因为它是环形数组。下面代码大量的应用了CAS操作,不清楚的同学自觉去补课。除了这五个变量,还有三个静态变量,分别是producerIndex、producerLimit、consumerIndex的相对地址。
所谓的相对地址,是对象内存布局的说法。JVM系列:二、虚拟机中的对象布局。unsafe中的objectFieldOffset(Field f)方法可以获取相对地址。
2.1 offer
说到底终究是个队列,离不开offer和poll
public boolean offer(final E e) {
final long mask = this.mask;
long producerLimit = lvProducerLimit();
long pIndex;
do {
pIndex = lvProducerIndex();
if (pIndex >= producerLimit) {
final long cIndex = lvConsumerIndex();
producerLimit = cIndex + mask + 1;
if (pIndex >= producerLimit){
return false;
} else {
soProducerLimit(producerLimit);
}
}
}
while (!casProducerIndex(pIndex, pIndex + 1));
final long offset = calcElementOffset(pIndex, mask);
soElement(buffer, offset, e);
return true;
}
- 获取producerLimit,进入循环再次获取生产者的索引,如果队列没有满,则通过CAS修改递增producerIndex的值。
- 如果修改成功,表明当前线程抢到了pIndex对应数组中的槽,接着可以把元素放入其中。calcElementOffset是计算该索引对应数组元素的下标。
REF_ARRAY_BASE + ((index & mask) << REF_ELEMENT_SHIFT),REF_ARRAY_BASE是数组buffer的相对偏移地址。index & mask是计算数组的下标,
<< 位移运算符表示左移,REF_ELEMENT_SHIFT大小为2,左移2位相当于乘4。接着对指定的下标进行赋值,soElement方法内部是unsafe的putOrderedObject方法。简单的说这个赋值动作非常有讲究
它比putObjectVolatile的性能高近三倍。代价是其线程(包括当前线程)在几纳秒之后才能看到。值就是传说中的lazyset操作。细节在后面再说。 - 如果生产者索引大于或者等于producerLimit,则说明生产者已经走到数组的尾部,需要从头开始生产。接着重新计算producerLimit,并且更新producerLimit。注意此更新操作也是lazyset
2.2 poll
public E poll() {
final long cIndex = lpConsumerIndex();
final long offset = calcElementOffset(cIndex);
final E[] buffer = this.buffer;
// If we can't see the next available element we can't poll
E e = lvElement(buffer, offset); // LoadLoad
if (null == e) {
/*
* NOTE: Queue may not actually be empty in the case of a producer (P1) being interrupted after
* winning the CAS on offer but before storing the element in the queue. Other producers may go on
* to fill up the queue after this element.
*/
if (cIndex != lvProducerIndex()){
do {
e = lvElement(buffer, offset);
} while (e == null);
} else {
return null;
}
}
spElement(buffer, offset, null);
soConsumerIndex(cIndex + 1);
return e;
}
消费者线程因为只有一各,因此在这里看不到CAS操作。注意lvElement是获取节点,内部是getObjectVolatile,此操作具有Volatile语意。
MpscArrayQueue就分析到此,至于其他的队列相关的操作也同样精彩。此处就不再展开。
3. MpscCompoundQueue
与MpscArrayQueue的思路不同,设计者认为单个数组在生产端竞争还是太激烈。因此将一个数组分为多个数组,也就是其内部是多个MpscArrayQueue,就是为了减少冲突带来的CAS消耗。
// 并行数,也就是内部的队列数
protected final int parallelQueues;
// 用于计算生产者将元素放入那个队列,初始值为数组的最大下标
protected final int parallelQueuesMask;
// 内部多个队列
protected final MpscArrayQueue<E>[] queues;
// 消费者的索引
int consumerQueueIndex;
进入父类的构造方法
MpscCompoundQueueColdFields(int capacity, int queueParallelism) {
parallelQueues = isPowerOfTwo(queueParallelism) ? queueParallelism
: roundToPowerOfTwo(queueParallelism) / 2;
parallelQueuesMask = parallelQueues - 1;
queues = new MpscArrayQueue[parallelQueues];
int fullCapacity = roundToPowerOfTwo(capacity);
RangeUtil.checkGreaterThanOrEqual(fullCapacity, parallelQueues, "fullCapacity");
for (int i = 0; i < parallelQueues; i++) {
queues[i] = new MpscArrayQueue<E>(fullCapacity / parallelQueues);
}
}
首先是计算并行队列数,计算逻辑为n的下一个2的幂除以2,比如n=3,结果为2,如果n=7,结果为8,接着初始化MpscArrayQueue数组。
3.1 offer
生产策略如下
public boolean offer(final E e) {
final int parallelQueuesMask = this.parallelQueuesMask;
int start = (int) (Thread.currentThread().getId() & parallelQueuesMask);
final MpscArrayQueue<E>[] queues = this.queues;
if (queues[start].offer(e)){
return true;
} else {
return slowOffer(queues, parallelQueuesMask, start + 1, e);
}
}
简单出乎我们的意料,线程Id决定将生产的元素放入那个内部队列,如果加入MpscArrayQueue失败,表明那个队列已满。那么进入slowOffer
private boolean slowOffer(MpscArrayQueue<E>[] queues, int parallelQueuesMask, int start, E e){
final int queueCount = parallelQueuesMask + 1;
final int end = start + queueCount;
while (true) {
int status = 0;
for (int i = start; i < end; i++) {
int s = queues[i & parallelQueuesMask].failFastOffer(e);
if (s == 0) {
return true;
}
status += s;
}
if (status == queueCount) {
return false;
}
}
}
所谓的slow offer,也容易理解,其实就是便利内部的队列,尝试在每一条队列中加入。failFastOffer是MpscArrayQueue内部的方法。只进行一次CAS操作,如果失败则返回,尝试加入下一条队列。
3.2 poll
因为是单线程消费不会产生竞争,因此我们可以猜到,遍历内部队列,直到取出元素为止。
public E poll() {
int qIndex = consumerQueueIndex & parallelQueuesMask;
int limit = qIndex + parallelQueues;
E e = null;
for (; qIndex < limit; qIndex++) {
e = queues[qIndex & parallelQueuesMask].poll();
if (e != null) {
break;
}
}
consumerQueueIndex = qIndex;
return e;
}
4. MpscChunkedArrayQueue
前面锁提到的两种Mpsc队列都是定长的,但是有些场景无法预测队列的长度,如果初始值过大则Array实现的队列可能存在浪费空间的问题。是否存在灵活的队列动态的调整队列的长度。
MpscChunkedArrayQueue根据名字可以看出它是基于数组实现,跟准确的说是数组链表。这点可从它的父类BaseMpscLinkedArrayQueue看出。它融合了链表和数组,既可以动态变化长度,同时不会像链表频繁分配Node。并且吞吐量优于传统的链表。
同样将属性放在一块介绍
protected long consumerMask;
protected E[] consumerBuffer;
protected long consumerIndex;
protected long producerMask;
protected long producerIndex;
private volatile long producerLimit;
protected E[] producerBuffer;
这里有两个数组的引用,分别是用于生产者和消费者,当容量不足时,新建一个数组,通过旧数组的最后一个元素指向新的数组。并且每个数组的长度是相同的。
构造方法如下
public BaseMpscLinkedArrayQueue(final int initialCapacity) {
int p2capacity = Pow2.roundToPowerOfTwo(initialCapacity);
// leave lower bit of mask clear
long mask = (p2capacity - 1) << 1;
// need extra element to point at next array
E[] buffer = allocate(p2capacity + 1);
producerBuffer = buffer;
producerMask = mask;
consumerBuffer = buffer;
consumerMask = mask;
soProducerLimit(mask);
}
首先计算每个数组的长度,根据入参initialCapacity计算出下一个2的幂次方。然后新建一个数组,注意容量,+1表示最后一个元素存放下一个数组的地址。
4.1 offer
public boolean offer(final E e) {
long mask;
E[] buffer;
long pIndex;
while (true) {
long producerLimit = lvProducerLimit(); // 获取当前数据Limit的阈值
pIndex = lvProducerIndex(); // 获取当前生产者指针位置
if ((pIndex & 1) == 1) {
continue;
}
mask = this.producerMask;
buffer = this.producerBuffer;
// 当阈值小于等于生产者指针位置时,则需要扩容,否则直接通过CAS操作对pIndex做加2处理
if (producerLimit <= pIndex) {
// 通过offerSlowPath返回状态值,来查看怎么来处理这个待添加的元素
int result = offerSlowPath(mask, pIndex, producerLimit);
switch (result) {
case CONTINUE_TO_P_INDEX_CAS:
break;
case RETRY: // 可能由于并发原因导致CAS失败,那么则再次重新尝试添加元素
continue;
case QUEUE_FULL: // 队列已满,直接返回false操作
return false;
case QUEUE_RESIZE: // 队列需要扩容操作
resize(mask, buffer, pIndex, e); // 对队列进行直接扩容操作
return true;
}
}
// 能走到这里,则说明当前的生产者指针位置还没有超过阈值,因此直接通过CAS操作做加2处理
if (casProducerIndex(pIndex, pIndex + 2)) {
break;
}
}
// 获取计算需要添加元素的位置
final long offset = modifiedCalcElementOffset(pIndex, mask);
// 在buffer的offset位置添加e元素
soElement(buffer, offset, e); // release element e
return true;
}
当pIndex指针超过阈值producerLimit时则扩容处理,否则直接通过CAS操作添加记录pIndex位置,resize代码
private void resize(long oldMask, E[] oldBuffer, long pIndex, E e) {
// 获取oldBuffer的长度值
int newBufferLength = getNextBufferSize(oldBuffer);
// 重新创建新的缓冲区
final E[] newBuffer = allocate(newBufferLength);
producerBuffer = newBuffer; // 将新创建的缓冲区赋值到生产者缓冲区对象上
final int newMask = (newBufferLength - 2) << 1;
producerMask = newMask;
// 根据oldMask获取偏移位置值
final long offsetInOld = modifiedCalcElementOffset(pIndex, oldMask);
// 根据newMask获取偏移位置值
final long offsetInNew = modifiedCalcElementOffset(pIndex, newMask);
// 将元素e设置到新的缓冲区newBuffer的offsetInNew位置处
soElement(newBuffer, offsetInNew, e);
// 主要是将oldBuffer中最后一个元素的位置指向新的缓冲区newBuffer
soElement(oldBuffer, nextArrayOffset(oldMask), newBuffer);
final long cIndex = lvConsumerIndex();
final long availableInQueue = availableInQueue(pIndex, cIndex);
RangeUtil.checkPositive(availableInQueue, "availableInQueue");
// 重新计算阈值,因为availableInQueue反正都是Integer.MAX_VALUE值,所以自然就取mask值啦
soProducerLimit(pIndex + Math.min(newMask, availableInQueue));
// 设置生产者指针加2处理
soProducerIndex(pIndex + 2);
// 用一个空对象来衔接新老缓冲区,凡是在缓冲区中碰到JUMP对象的话,那么就得琢磨着准备着获取下一个缓冲区的数据元素了
soElement(oldBuffer, offsetInOld, JUMP);
}
该方法主要完成新的元素的放置,同时也完成了扩容操作,采用单向链表指针关系,将原缓冲区和新创建的缓冲区衔接起来;
4.2 poll
public E poll() {
final E[] buffer = consumerBuffer; // 获取缓冲区的数据
final long index = consumerIndex;
final long mask = consumerMask;
// 根据消费指针与mask来获取当前需要从哪个位置开始来移除元素
final long offset = modifiedCalcElementOffset(index, mask);
// 从buffer缓冲区的offset位置获取元素内容
Object e = lvElement(buffer, offset);// LoadLoad
if (e == null) {
// 则再探讨看看消费指针是不是和生产指针是不是相同
if (index != lvProducerIndex()) {
// 若不相同的话,则先尝试从buffer缓冲区的offset位置获取元素先,若获取元素为null则结束while处理
do
{
e = lvElement(buffer, offset);
} while (e == null);
}else { // 说明消费指针是不是和生产指针是相等的,那么则缓冲区的数据已经被消费完了,直接返回null即可
return null;
}
}
// 如果元素为JUMP空对象的话,那么意味着我们就得获取下一缓冲区进行读取数据了
if (e == JUMP) {
final E[] nextBuffer = getNextBuffer(buffer, mask);
return newBufferPoll(nextBuffer, index);
}
// 能执行到这里,说明需要移除的元素既不是空的,也不是JUMP空对象,那么则就按照正常处理置空即可
// 移除元素时,则将buffer缓冲区的offset位置的元素置为空即可
soElement(buffer, offset, null);
// 同时也通过CAS操作增加消费指针的关系,加2操作
soConsumerIndex(index + 2);
return (E) e;
}
该方法主要阐述了该队列是如何的移除数据的;取出的数据如果为JUMP空对象的话,那么则准备从下一个缓冲区获取数据元素,否则还是从当前的缓冲区对象中移除元素,并且更新消费指针。
5. 优化总结
Jctools中还有很多亮点数据结构,比如ConcurrentAutoTable NonBlockingHashMa等等,目前自己也在不断的探索。以下是对Mscp的亮点操作总结。
- lazy set
lazy set是使用Unsafe.putOrderedXXX方法,会前置一个store-store屏障,也许你会为问不用putOrderedXXX那之前用什么?答案是putXXXVolitaile方法,这个方法具有Volatile语意,也就是store-load屏障。收益是修改后其他线程回立即看到修改的值,但代价是store-store接近2-3倍的耗时,store-store的劣势是纳秒级的延迟。 - 大量的位运算
在前面中也看到了,通过&运算得到数组的下标,<< 计算数组的偏移地址,再利用unsafe进行设置等操作。举个例子%运算耗时是&的两倍。 - 伪共享
在本文中列出的代码已经去除掉了大量的long类型变量。笔者不理解Jctool的作者为什么不使用@Contended来提升代码的可阅读性。关于伪共享这里不再解释。扩展阅读中可以找到伪共享的相关文章。 - 无锁
这里说的无锁是感叹单消费的思想,符合场景才是王道。
测试代码地址
https://github.com/TheLudlows/jmhdemo/blob/master/src/main/java/io/four/MpscBenchmark.java
扩展阅读
- Java中的指针:Unsafe类
- Java并发编程系列:漫谈伪共享
- Java并发编程系列:CAS 详解
- JVM系列:二、虚拟机中的对象布局