Spark之路(1、入门demo)
参考https://blog.csdn.net/u012373815/article/details/53266301
https://blog.csdn.net/lovehuangjiaju/article/details/48580863
一、Spark重要的概念
(1)Spark运行模式
目前最为常用的Spark运行模式有:
- local:本地线程方式运行,主要用于开发调试Spark应用程序
- Standalone:利用Spark自带的资源管理与调度器运行Spark集群,采用Master/Slave结构,为解决单点故障,可以采用ZooKeeper实现高可靠(High Availability,HA)
- Apache Mesos :运行在著名的Mesos资源管理框架基础之上,该集群运行模式将资源管理交给Mesos,Spark只负责进行任务调度和计算
- Hadoop YARN : 集群运行在Yarn资源管理器上,资源管理交给Yarn,Spark只负责进行任务调度和计算
Spark运行模式中Hadoop YARN的集群运行方式最为常用,本课程中的第一节便是采用Hadoop YARN的方式进行Spark集群搭建。如此Spark便与Hadoop生态圈完美搭配,组成强大的集群,可谓无所不能。
(2)Spark组件(Components)
一个完整的Spark应用程序,如前一节当中SparkWordCount程序,在提交集群运行时,它涉及到如下图所示的组件:
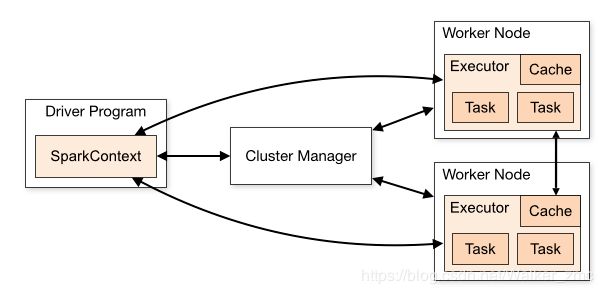
各Spark应用程序以相互独立的进程集合运行于集群之上,由SparkContext对象进行协调,SparkContext对象可以视为Spark应用程序的入口,被称为driver program,SparkContext可以与不同种类的集群资源管理器(Cluster Manager),例如Hadoop Yarn、Mesos等 进行通信,从而分配到程序运行所需的资源,获取到集群运行所需的资源后,SparkContext将得到集群中其它工作节点(Worker Node) 上对应的Executors (不同的Spark应用程序有不同的Executor,它们之间也是独立的进程,Executor为应用程序提供分布式计算及数据存储功能),之后SparkContext将应用程序代码分发到各Executors,最后将任务(Task)分配给executors执行。

二、创建一个scala项目
三、导入依赖
想要运行在spark 上则还需要导入相关依赖。打开pom.xml文件添加如下依赖。
注意:是添加如下依赖;spark 和Scala的版本是对应的。
2.0.2
2.11
org.apache.spark
spark-core_${scala.version}
${spark.version}
org.apache.spark
spark-streaming_${scala.version}
${spark.version}
org.apache.spark
spark-sql_${scala.version}
${spark.version}
org.apache.spark
spark-hive_${scala.version}
${spark.version}
org.apache.spark
spark-mllib_${scala.version}
${spark.version}
org.scala-tools
maven-scala-plugin
2.15.2
compile
testCompile
maven-compiler-plugin
3.6.0
1.8
1.8
org.apache.maven.plugins
maven-surefire-plugin
2.19
true
四、编写Spark代码
依赖添加成功后,新建scala 的object 文件然后填写如下代码
//本案例是新建一个int 型的List数组,对数组中的每个元素乘以3 ,再过滤出来数组中大于10 的元素,然后对数组求和。
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by yangyibo on 16/11/21.
*/
object MySpark {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("mySpark")
//setMaster("local") 本机的spark就用local,远端的就写ip
//如果是打成jar包运行则需要去掉 setMaster("local")因为在参数中会指定。
conf.setMaster("local")
val sc =new SparkContext(conf)
val rdd =sc.parallelize(List(1,2,3,4,5,6)).map(_*3)
val mappedRDD=rdd.filter(_>10).collect()
//对集合求和
println(rdd.reduce(_+_))
//输出大于10的元素
for(arg <- mappedRDD)
print(arg+" ")
println()
println("math is work")
}
}
代码编写好以后,右键 run ‘mySpark’ 运行。
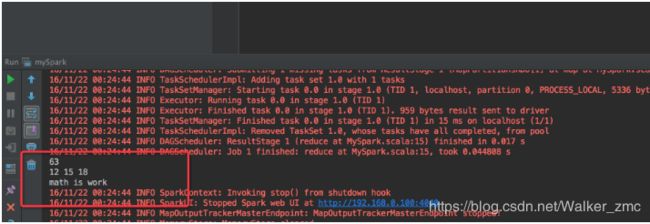
执行结果如下:
五、打包运行
运行成功后,可以讲代码打包成jar 包发送到远端或者本地的spark 集群上运行。打包有以下步骤
点击“File“然后选择“project Structure“
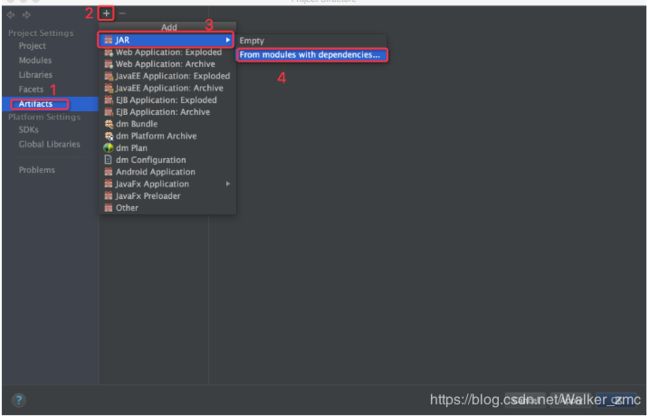
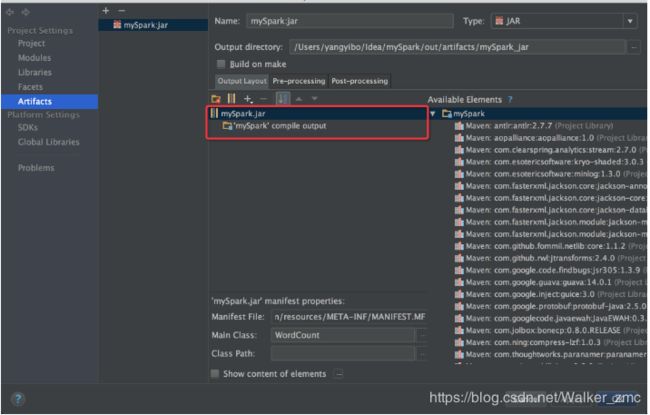
在弹出的对话框中点击按钮,选择主类进行如下4步操作。

由于我们的jar包实在spark 上运行的,所可以删除其他不需要的依赖包,如下图所示,删除其他不需要的包,只留下红色矩形中的两个。
注意:output directory 的路径。此处是你导出 jar 的路径。
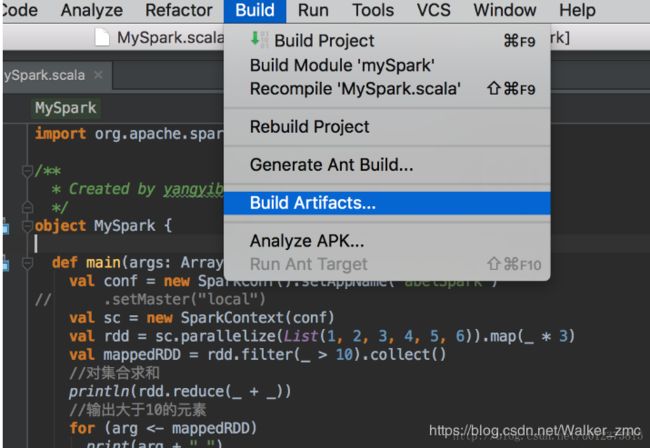
执行 bulid 构建你的jar
jar 包导出以后就可以在spark上运行了。
此时进入终端,进入到spark安装包的 bin 目录下。执行如下命令
MySpark :是启动类的名字,如果有包命,要加包名,(例如 com.edu.MySpark)
spark1:7077 : 是你远端的spark 的地址 ,(可以是 //192.168.200.66:7077) 写spark1 是因为我在/etc/hosts 中配置了环境参数,至于hosts 怎么配,请自行百度。
/Users/yangyibo/Idea/mySpark/out/artifacts/mySpark_jar/mySpark.jar: 是你jar 包的路径。
./bin/spark-submit --class MySpark --master spark://spark1:7077 /Users/yangyibo/Idea/mySpark/out/artifacts/mySpark_jar/mySpark.jar