近年图像翻译先进模型小结

©PaperWeekly 原创 · 作者|武广
学校|合肥工业大学硕士生
研究方向|图像生成
计算机视觉下的任务纷繁庞大,除了熟悉的目标检测、图像识别、图像分类等常见的视觉应用,还有着图像翻译、图像分割和图像超分辨率等十分具有研究和应用价值的方向。本文就近年(2019 和 2020 年)图像翻译下的先进模型进行典型性介绍,一起梳理下图像翻译的发展和未来研究的趋势。

图像翻译的发展
图像翻译旨在通过设计端到端的模型将源域图像转换到目标域图像,通常源域提供图像的内容,目标域提供图像的“风格”(可以是图像属性或图像风格),在源域内容下实现目标域的“风格”化,从而实现源域图像到目标域图像的转换。
说的通俗点图像翻译可以是标签图到场景图的转换、线条轮廓到色彩图像转换、图像的风格转换,春夏场景的变换,人脸的属性变换,也可以是白昼交替的转换。只要符合上述端到端转换的任务,都可以通过图像翻译实现。引用 pix2pix [1] 中的经典插图,一起看下图像翻译的实际应用。

▲ 图1.图像翻译的不同任务场景
图像翻译自深度学习应用下便得到了快速的发展,尤其是随着生成对抗网络(GAN)的提出,大大加速了图像翻译的演进。从早期的 pix2pix、CycleGAN [2]、UNIT [3] 到较为成熟的 StarGAN [4] 都是图像翻译在上几年较为成功和经典的模型。
这些模型实现了从源域图像到目标域图像的转换,但这往往需要一定的标签参与或者需要建立源域和目标域各自的生成器,同时任务往往实现的是单目标域的转换。
随着发展到 MUNIT [5]、DRIT [6] 以及 UGATIT [7] 则进一步实现了由源域到多目标域的转换,也有利用语义 mask 图像实现无条件图像翻译的 SPADE [8]。
StyleGAN [9] 实现了高质量的图像风格转换,这无疑于 StyleGAN 的细致的架构,逐步分辨率的阶段性生成、自适应实例正则化(AdaIN)和风格空间的应用。
StyleGAN2 [10] 在 StyleGAN 的基础上进一步对 AdnIN 进行修正,demodulation 操作应用于每个卷积层相关的权重,并且通过 skip generator 代替 progressive growing,实现了更为细致的图像转换。这些基础性的图像转换架构对于近年来的图像翻译任务提供价值性的指导。
近年来,图像翻译实现了更加细致的任务实现,StarGAN v2 [11] 在 StarGAN 的基础上实现了多源域到多目标域的图像转换;ALAE [12] 将自编码器拓展到高精致的图像转换。
HiDT [13] 提供了多域图像转换下对图像翻译下的网络逻辑和损失函数做了细致的总结;ConSinGAN [14] 代表了一众单幅图像训练的先进模型,实现了单幅图像训练下的图像转换任务。本文将以这 4 篇论文进行介绍,对近年图像翻译模型进行分析和小结。

图像翻译模型
2.1 StarGAN v2

论文标题:StarGAN v2: Diverse Image Synthesis for Multiple Domains
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/1912.01865
代码链接:https://github.com/clovaai/stargan-v2

StarGAN v2 针对 StarGAN 存在的仅能在单目标域下转换和需要标签信息参与的两个问题,提出了目标域下多风格图像的转换。如何实现多目标域的转换呢?StarGAN v2 设计了 Mapping Network 用于生成风格编码,从而为目标域下提供多类型的风格表示而不需要额外的标签,模型的整体结构如图 2 所示。

▲ 图2.StarGAN v2模型整体结构
可以看出 StarGAN v2 由四部分组成,生成器 ,映射网络 ,风格编码器 判别器 。我们先捋一下整个过程,首先映射网络学习到目标域图像的风格编码 ,其中 ,这是映射网络学习到的目标域图像的风格编码。
而作为参照真实目标域图像的风格编码由风格编码器得到 ,得到了风格编码 结合源域输入图像 便可送入到生成器,生成器输出的就是转换后的目标域图像 ,而判别器则为了区分生成的目标域图像是否是真实来源于真实目标域。
StarGAN v2 中映射网络、风格编码器和判别器的输出都是多分支的,因为文章的目的是进行多目标域的转换,这里的多分支就是不同的目标域的表示,对于映射网络和风格编码器,多分支表示的是多个目标域图像的风格表示,对于判别器多分支则是代表不同目标域的判别真假情况,作者在附录中用 表示分支数。
图 3 展示了 StarGAN v2 的较为详细的网络设计。

▲ 图3.StarGAN v2模型设计结构
至于损失函数上,值得一提的是风格表示上的风格重构损失

和映射网络丰富化的

(使得目标风格表示之间边界分明,产生多目标转换结果,最大化 ),还有就是较为熟悉的对抗损失 和循环一致损失 ,在最终的损失优化上:
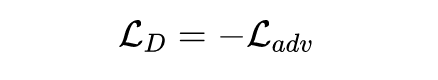

实验上,在图像转换上展示了优越的效果。

▲ 图4.StarGAN v2定性对比结果
2.2 ALAE

论文标题:Adversarial Latent Autoencoders
论文链接:https://arxiv.org/abs/2004.04467
代码链接:https://github.com/podgorskiy/ALAE

自编码器能否具有像 GAN 那样的生成能力呢?ALAE 给出了肯定的答案,ALAE 算是建立在 StyleGAN 基础之上,具备与 GAN 相当的生成能力,且能够学习解耦表征,在人脸属性变换上展示了优越的效果。
ALAE 采用自编码器架构,将 GAN 中的生成器和判别器分解为两个网络,生成器对应着 和 ,判别器对应着 和 ,先从整体架构来看一下 ALAE 模型。

▲ 图5.ALAE模型结构
在训练阶段,随机噪声 经过网络 ,将随机噪声映射到数据的潜在空间 ,网络 则负责将数据潜在空间 和风格变量 映射到数据空间。此时输入的 经过 和 得到图像输出 ,判别部分由网络 和 组成,网络 将数据编码到潜在空间 并且与 投影得到的 做分布拉近,理想状态下 。
网络 是个新颖的设计,它并没有严格的目的性也就是并没有强调和约束数据的潜在空间分布,而是由全局优化下自动学习数据的潜在空间。也正因为存在了数据的潜在空间的刻画,ALAE 才可以说是建立在自编码器下结构下的模型。
在测试阶段,由网络 和 构成了自编码器的编码器和解码器,构成 Encoder-Decoder 的结构,由 可以控制图像属性从而实现图像翻译任务。
损失设计上除了对抗损失,还有就是潜在空间分布下的拉近 ,这也是文章称为为对抗性潜在自动编码器(ALAE)的原因。ALAE 在设计上借鉴了 StyleGAN 的结构并称之为 StyleALAE,整体的架构如图 6 所示。

▲ 图6.StyleALAE网络架构
作者使用 MNIST 数据集训练 ALAE,并使用特征表示来执行分类、重建和分析解耦能力的任务,与已有的自编码器模型对比结果存在优势,ALAE 最让人印象深刻的就是 StyleALAE 在 FFHQ 上的生成效果,真是将自编码器做到了 GAN 的高精度生成。

▲ 图7.StyleALAE的生成效果
本文围绕着图像翻译展开,ALAE 当然适用于图像翻译任务,在人脸属性的转换上也做到了优越的转换效果。
▲ 图8.StyleALAE人脸属性变换
2.3 ConSinGAN

论文标题:Improved Techniques for Training Single-Image GANs
论文链接:https://arxiv.org/abs/2003.11512
代码链接:https://github.com/tohinz/ConSinGAN

近年有部分研究者将目光投入到单幅图像训练网络上,ICCV 2019 best paper SinGAN [15] 便是一个代表作,此处要介绍的 ConSinGAN 则是在 SinGAN 的基础上的升级版。
受限于数据样本和网络训练时长,单幅图像训练的模型存在着很大的应用意义。要介绍清 ConSinGAN 则必须要提一下 SinGAN,本质上 ConSinGAN 就是并行的 SinGAN,缩写中不同的 Con 就是指 Concurrent 的意思。
SinGAN 按照不同分辨率分阶段训练生成器和判别器,在串行的阶段训练上,当前生成器将前一个生成器生成的图像作为输入,在此基础上生成比当前还要高分辨率的图像,此时不同阶段的生成器都是单独训练的,这也意味着在训练当前生成器时,之前的生成器的权重都保持不变,这个过程由图 9 所示。

▲ 图9.SinGAN训练过程
ConSinGAN 指出每个分辨率下仅训练一个生成器而固定前面的生成器的参数,这仅仅将前一阶段生成器输出作为当前的输入,这一定程度上限制了不同阶段生成器之间的交互。
ConSInGAN 设计了对生成器进行端到端的训练,也就是说,在给定时间内可以训练多个生成器,每个生成器将前一个生成器生成的特征(而不是图像)作为输入。这种训练是对多个阶段下的生成器同时进行的,也称之为并行训练的方式,这个过程如图 10 所示。
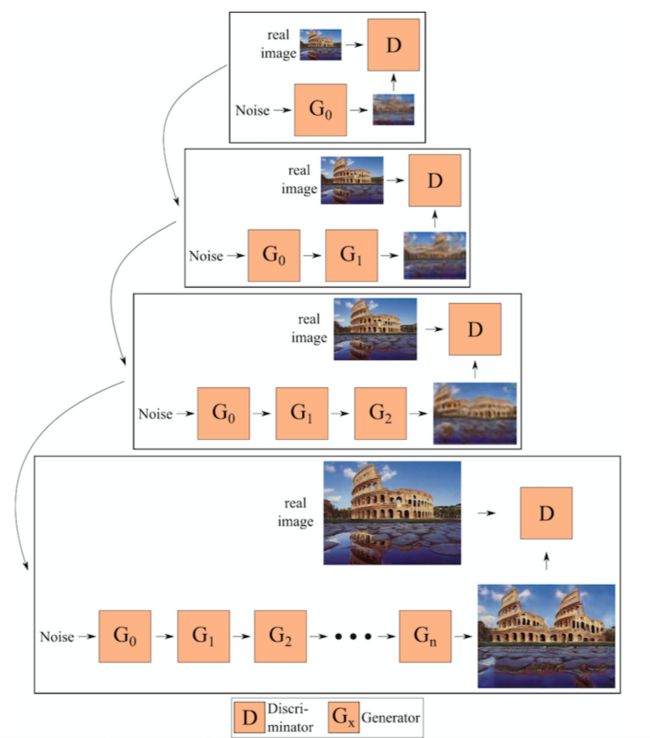
▲ 图10.ConSinGAN训练过程
然而训练多个分辨率下的生成器将会导致另一个问题,那就是过拟合,也就是最后得到的图像失去了多样性,为了解决这个问题,ConSinGAN 提出了 2 个应对方案。
在任意给定时间内,只训练一部分生成器
在训练一部分生成器时,还要对不同的生成器使用不同的学习率,对于低分辨率阶段的生成器使用较小的学习率
文章和源码中默认最多同时训练 3 个生成器,此时对前两阶段的生成器采用当前学习率的 和 ,这个过程图 11 进行展示。

▲ 图11.ConSinGAN训练不同生成器不同学习率
实验发现如果对早阶段的生成器采用较高的学习率,那么生成的图像质量会高些,但是差异性较弱。相反,如果对早阶段的生成器采用较小的学习率,那么生成图像的差异性会丰富一些。
在进行图像翻译任务时,ConSinGAN 进行了图像协调实验,主要与 SinGAN 进行对比,得到的对比结果如图 12 所示。

▲ 图12.ConSinGAN在图像协调下的转换结果
2.4 HiDT

论文标题:High-Resolution Daytime Translation Without Domain Labels
论文来源:CVPR 2020
论文链接:https://arxiv.org/abs/2003.08791

最后来分析下 High-Resolution Daytime Translation Without Domain Labels (HiDT),这篇文章虽然做的是高清自然场景时移变换,但是确实将图像翻译的训练逻辑和损失函数介绍的非常清晰的文章,HiDT 也是 CVPR 2020 oral 的一篇文章,在这里梳理一下 HiDT 对图像翻译的设计逻辑和损失函数的设计。

▲ 图13.HiDT网络优化过程
先交代下符号, 表示源域输入图像, 表示内容编码器相对应的 为内容编码, 表示风格编码器相对应的 为风格编码, 为生成器, 为目标域风格编码, 为风格编码的先验分布, 为在风格编码的先验分布下随机采样的风格编码。生成器 不光光输出的是转换后的图像,同时也输出相对应的风格掩码图 。
从上到下分析,随机风格采样 与内容编码 生成 ,此时 的风格取决于随机风格 ,掩码 则是受内容 的影响,对 继续进行内容和风格编码得到 ,将 馈送到生成器 得到重构的 ,为什么说是重构呢?
因为此时输入的风格是 自身的风格编码;中间一路就是对 进行编码后再重构得到 ;最下面一路则是先根据源域内容编码 与目标域风格编码 生成得到目标域图像和分割掩码 ,再由 编码得到的内容编码 与风格编码 得到最原始源域图像 ,由于 给出的损失为 ,这里推测风格编码 就是源域图像的风格表示。
上述分析,总结起来就是模型在优化阶段由三种模式,一是随机风格的转换和重构,二是原始图像的重构,三是目标域图像转换和循环一致的转换。
最后就是如何对模型进行损失优化,正由图 13 中所展示的,重构损失 ,风格掩码损失 ,内容编码损失 ,风格编码损失 ,风格编码下趋紧先验分布的损失 以及循环一致损失 ,由此衍生的 也是一样的含义,图 13 中省略了对抗损失 ,对抗损失主要是对转换后的 和 进行优化。
重构损失为 损失,即 ,类似的有 ,循环一致损失也是采用 损失 。对于分割掩码损失则是采取交叉熵损失:

则有:

由于风格编码的维度较低,此时可以通过均值和方差拉向正态分布,达到风格编码向先验分布靠近:
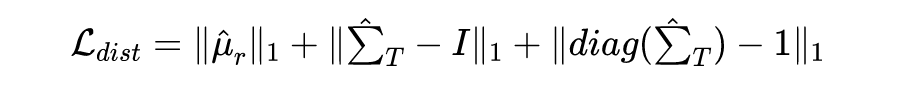
对于内容编码损失 和风格编码损失 ,则是通过 损失一致性优化,即:

总的损失可变式为:

其中 为超参数。HiDT 的模型优化算是对图像翻译下的损失进行了一个系统的介绍,同时也是我认为在不系统阅读代码下对图像翻译下的逻辑介绍最为清晰的一篇文章。

总结
近年来图像翻译的文章还有很多,本文仅仅是笔者选摘的有代表性的几篇文章,图像翻译已不再是简单的图像风格变换或是源域到目标域的转换,而是上升到多源域到多目标域图像的转换。
同时基于 GAN,基于自编码器,基于 pixelCNN 的模型也是十分丰富。从庞大的数据集进行训练,到可以由单幅图像的训练,对于训练的样本要求也在逐步降低。
总的来说,图像翻译向着更加系统和全面的方向有序进展,虽然模型做到了多源域到多目标域图像的转换,但是这个过程仍存在很多的限制,限制于数据集和各目标域间的标注,同时不同目标域间的差距仍不能做到很大,one for all 的理念仍是一个很值得研究和迈进的方向。
参考文献
[1] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
[2] Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.
[3] Liu M Y, Breuel T, Kautz J. Unsupervised image-to-image translation networks[C]//Advances in neural information processing systems. 2017: 700-708.
[4] Choi Y, Choi M, Kim M, et al. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8789-8797.
[5] Huang X, Liu M Y, Belongie S, et al. Multimodal unsupervised image-to-image translation[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 172-189.
[6] Lee H Y, Tseng H Y, Mao Q, et al. Drit++: Diverse image-to-image translation via disentangled representations[J]. International Journal of Computer Vision, 2020: 1-16.
[7] Kim J, Kim M, Kang H, et al. U-GAT-IT: unsupervised generative attentional networks with adaptive layer-instance normalization for image-to-image translation[J]. arXiv preprint arXiv:1907.10830, 2019.
[8] Park T, Liu M Y, Wang T C, et al. Semantic image synthesis with spatially-adaptive normalization[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 2337-2346.
[9] Karras T, Laine S, Aila T. A style-based generator architecture for generative adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 4401-4410.
[10] Karras T, Laine S, Aittala M, et al. Analyzing and improving the image quality of stylegan[J]. arXiv preprint arXiv:1912.04958, 2019.
[11] Choi Y, Uh Y, Yoo J, et al. StarGAN v2: Diverse Image Synthesis for Multiple Domains[J]. arXiv preprint arXiv:1912.01865, 2019.
[12] Pidhorskyi, Stanislav and Adjeroh, Donald A and Doretto, Gianfranco, et al. Adversarial Latent Autoencoders[J]. arXiv preprint arXiv:2004.04467, 2020.
[13] Anokhin I, Solovev P, Korzhenkov D, et al. High-Resolution Daytime Translation Without Domain Labels[J]. arXiv preprint arXiv:2003.08791, 2020.
[14] Hinz T, Fisher M, Wang O, et al. Improved Techniques for Training Single-Image GANs[J]. arXiv preprint arXiv:2003.11512, 2020.
[15] Rott Shaham T, Dekel T, Michaeli T. SinGAN: Learning a Generative Model from a Single Natural Image[J]. arXiv preprint arXiv:1905.01164, 2019.

点击以下标题查看更多往期内容:
CVPR 2020 | 自适应聚合网络:更高效的立体匹配
CVPR 2020最新热点:物体位姿估计
格“物”致知:多模态预训练再次入门
对比学习(Contrastive Learning)相关进展梳理
CVPR 2020 Oral | 无域标签下高清场景时移变换
CVPR 2020 | 商汤TSD目标检测算法解读

#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
