Spark权威指南(中文版)----第25章 预处理和特征工程
Spark The Definitive Guide(Spark权威指南) 中文版。本书详细介绍了Spark2.x版本的各个模块,目前市面上最好的Spark2.x学习书籍!!!
扫码关注公众号:登峰大数据,阅读中文Spark权威指南(完整版),系统学习Spark大数据框架!
如果您觉得作者翻译的内容有帮助,请分享给更多人。您的分享,是作者翻译的动力

任何称职的数据科学家都知道,高级分析中最大的挑战之一(和时间消耗)是预处理。这并不是因为它是特别复杂的编程,而是因为它需要对正在处理的数据有深入的了解,并且需要理解模型需要什么,才能成功地利用这些数据。本章将详细介绍如何使用Spark执行预处理和特征工程。我们将介绍您需要满足的核心需求,以便根据数据的结构来训练MLlib模型。然后,我们将讨论Spark为执行这类工作提供的不同工具。
25.1.根据用例格式化模型
要为Spark的不同高级分析工具预处理数据,您必须考虑您的最终目标。下面的列表介绍了MLlib中每个高级分析任务对输入数据结构的要求:
在大多数分类和回归算法的情况下,您希望将数据放入Double类型的列来表示标签,并将数据放入Vector类型的列(密集或稀疏)来表示特征。
-
对于推荐算法,您希望将数据放入用户列、项目列(比如电影或书籍)和评级列中。
-
在无监督学习的情况下,需要一列Vector类型(密集或稀疏)来表示特征。
-
在图计算的情况下,您将需要顶点的DataFrame和边的DataFrame。
以这些格式获取数据的最佳方法是通过transformers(转换器)。转换器是接受一个DataFrame作为参数并返回一个新的DataFrame作为响应的函数。本章将重点介绍与特定用例相关的transformers,而不是试图列举所有可能的transformers。
注意
Spark内置了许多transformers作为org.apache.spark.ml.feature包的一部分。Python中相应的包是pyspark.ml.feature。新的transformers不断出现在Spark MLlib中,因此不可能在本书中包含一个明确的列表。最新的信息可以在Spark文档站点上找到。
在我们继续之前,我们将阅读几个不同的样本数据集,每一个都有不同的属性,我们将在本章操作:

除了这些真实的销售数据,我们还将使用几个简单的合成数据集。FakeIntDF、simpleDF和scaleDF都只有很少的行。这将使您能够专注于我们正在执行的精确数据操作,而不是任何特定数据集的各种不一致性。因为我们要访问销售数据很多次,我们要缓存它这样我们就能从内存中有效地读取它而不是每次需要时从磁盘中读取它。为了更好地理解数据集中的内容,我们还检查前几行数据:

注意
需要注意的是,我们在这里过滤了空值。此时,MLlib并不总是能很好地处理空值。这是导致问题和错误的常见原因,也是调试时的重要第一步。每个Spark版本都进行了改进,以改进对空值的算法处理。
25.2.Transformers
我们在前一章讨论了transformers,但是在这里有必要再次回顾它们。Transformers是以某种方式转换原始数据的函数。这可能是创建一个新的交互变量(来自其他两个变量),对一个列进行规范化,或者简单地将它转换为一个Double以输入到模型中。Transformers主要用于预处理或特征生成。
Spark的transformer只包含转换方法。这是因为它不会根据输入数据进行更改。图25-1是一个简单的说明。左边是一个输入DataFrame,其中包含要操作的列。右边是输入DataFrame,其中有一个表示输出转换的新列。

Tokenizer是transformer的一个例子。它标记一个字符串,在一个给定的字符上分裂,并且没有从我们的数据中学到什么;它只是应用一个函数。我们将在本章后面更深入地讨论Tokenizer,但这里有一个小代码片段,展示了Tokenizer是如何构建来接受输入列的,它如何转换数据,然后从该转换输出的 :

25.3.用于预处理的Estimators
预处理的另一个工具是estimators评估器。当您希望执行的转换必须使用有关输入列的数据或信息初始化时(通常通过传递输入列本身派生),estimators是必要的。例如,如果您想将列中的值缩放为均值为零和单位方差,则需要对整个数据执行一次遍历,以便计算用于将数据标准化为均值为零和单位方差的值。实际上,estimator可以是根据特定输入数据配置的transformer。简单地说,您可以盲目地应用转换(“常规”转换器类型),也可以基于数据执行转换(estimator类型)。图25-2简单地说明了一个适合于特定输入数据集的estimator,生成一个transformer,然后将其应用于输入数据集,以附加一个新的列(转换后的数据)。

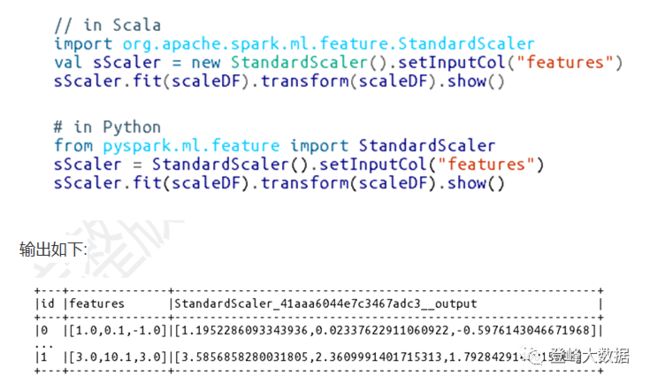
此类estimator的一个例子是StandardScaler,它根据列中的值范围对输入列进行缩放,使每个维度的均值为零,方差为1。因此,它必须首先执行数据传递来创建transformer。下面是显示整个过程和输出的示例代码片段:

我们将在本章的后面使用estimators评估器和transformers转换器,并对这些特定的estimators评估器进行更多的介绍(并在Python中添加示例)。
25.3.1.Transformer的属性设置
所有transformers都要求至少指定inputCol和outputCol,它们分别表示输入和输出的列名。用setInputCol和setOutputCol设置这些。有一些缺省值(您可以在文档中找到),但是为了清晰起见,最好亲自手动指定它们。除了输入列和输出列之外,所有transformers都有不同的参数,您可以对其进行调优(在本章中提到参数时,必须使用set()方法对其进行设置)。在Python中,我们还有另一种方法来使用对象构造函数的关键字参数设置这些值。为了保持一致性,我们在下一章的例子中排除了这些。Estimators要求您将transformer匹配到特定的数据集,然后对生成的对象调用transform。
注意
Spark MLlib将关于它在每个DataFrame中使用的列的元数据存储为列本身的属性。这允许它正确地存储(并注释)Double列实际上可能表示一系列分类变量,而不是连续值。但是,在打印schema或DataFrame时,不会显示元数据。
25.4.高级Transformers
高级转换,如我们在前一章中看到的RFormula,允许您在一个转换中简洁地指定多个转换。这些操作在“高级”上运行,允许您避免逐个进行数据操作或转换。一般来说,您应该尽量使用最高级别的转换器,以便将错误风险降到最低,并帮助您关注业务问题,而不是实现的较小细节。虽然这不总是可能的,但这是一个很好的目标。
25.4.1.RFormula
当您有“常规”格式的数据时,RFormula是最容易使用的transfomer。Spark从R语言中借鉴了这个transformer,使以声明方式为数据指定一组转换变得简单。使用这个transformer,值可以是数值型的,也可以是分类的,您不需要从字符串中提取值或以任何方式操作它们。RFormula将通过执行所谓的one-hot encoding自动处理分类输入(指定为字符串)。简而言之,one-hot编码将一组值转换为一组二进制列,指定数据点是否具有每个特定的值(我们将在本章后面更深入地讨论one-hot编码)。使用RFormula,数值列将被强制转换为Double,但不会使用one-hot编码。如果标签列的类型是String,那么它将首先使用StringIndexer转换为Double。
警告
自动将数字列强制转换为Double,而不进行one-hot encoding具有一些重要的含义。如果您有数值型的分类变量,它们将被强制转换为Double,隐式地指定一个顺序。重要的是确保输入类型与预期的转换相对应。如果类别变量实际上没有顺序关系,则应该将它们转换为String。您还可以手动索引列(参见“处理分类特征”)。
RFormula允许您使用声明式语法指定转换。一旦理解了语法,使用起来就很简单。目前,RFormula支持有限的R操作符子集,这些操作符在实践中非常适用于简单的转换。基本操作如下:
~
target目标和terms特征分隔符
+
连接terms。”+0”的意思是移除截距(这意味着我们拟合的直线的y轴截距为0)
-
删除terms。”-1”的意思是移除截距(这意味着我们拟合的直线的y轴截距是0,这和+ 0是一样的)
:
交互(数值相乘,或二值化分类值)
.
除目标/因变量外的所有列
RFormula输出的标签和特征集合(用于监督机器学习)使用默认的label列和features列来标记。本章后面介绍的模型默认情况下需要这些列名,因此很容易将转换后的DataFrame传递到用于训练的模型中。如果此时你不是完全理解,不要担心——一旦我们在后面的章节中真正开始使用模型,它就会变得清晰起来。
让我们在一个例子中使用RFormula。在本例中,我们希望使用所有可用变量(.),然后指定value1和color之间的交互,value2和color之间的交互作为要生成的附加特性:

25.4.2.SQL Transformer
SQLTransformer允许您像使用MLlib转换一样利用Spark的大量sql相关操作库。可以在SQL中使用的任何SELECT语句都是有效的转换。惟一需要更改的是,不使用表名,而只使用关键字THIS。如果您想将一些DataFrame操作作为预处理步骤,或者在超参数调优期间尝试不同的SQL表达式来获得特性,那么您可能需要使用SQLTransformer。还要注意,此转换的输出将作为列附加到输出DataFrame中。
您可能想要使用SQLTransformer,以便在最原始的数据形式上表示所有的操作,以便可以将不同的操作变体版本化为transformer。这使您可以通过简单地交换transformers来构建和测试不同的管道。下面是使用SQLTransformer的一个基本例子:

下面是输出的一个示例:

有关这些转换的详细示例,请参阅第2部分。
25.4.3.VectorAssembler
VectorAssembler是一个工具,您几乎可以在生成的每个pipeline中使用它。它帮助您将所有特性连接到一个大向量中,然后您可以将其传递给一个estimator。它通常在机器学习管道的最后一步中使用,并接受Boolean, Double,或者 Vector作为输入。如果您要使用各种transformers转换器执行许多操作,并且需要收集所有这些结果,那么这将非常有用。
以下代码片段的输出将清楚地说明这是如何工作的:

25.5.处理连续特征
连续特征就是数轴上的值,从正无穷到负无穷。连续特性有两种常见的transformers。首先,您可以通过一个称为bucketing的过程将连续特性转换为分类特性,或者您可以根据几个不同的需求对特征进行伸缩和标准化。这些bucketing只适用于Double类型,所以请确保您已经将任何其他数值转换为Double:

25.5.1.Bucketing
bucketing 或者 binning最直接的方法是使用Bucketizer。这将把给定的连续特征分成指定的几个buckets。您可以指定如何通过Double数组或列表创建bucket。这很有用,因为您可能希望简化数据集中的特性,或者简化它们的表示,以便稍后进行解释。例如,假设您有一个列,它表示一个人的体重,您希望根据这个信息预测一些值。在某些情况下,创建“overweight(超重)”、“average(平均体重)”和“underweight(体重不足)”这三类buckets可能更简单。
要指定bucket,请设置它的边界。例如,将contDF上的split设置为5.0、10.0和250.0实际上会失败,因为我们没有覆盖所有可能的输入范围。在指定bucket points时,传递给split的值必须满足三个要求:
-
splits数组中的最小值必须小于DataFrame中的最小值。
-
splits数组中的最大值必须大于DataFrame中的最大值。
-
如果创建两个bucket,需要在split数组中指定至少三个值。
警告
由于我们通过split方法指定bucket边界,所以Bucketizer可能会让人感到困惑,因为这些并不是真正的split。
要覆盖所有可能的范围,scala.Double.NegativeInfinity可能是另一个分割选项,用scala.Double.PositiveInfinity涵盖所有可能的范围以外的内部split。在Python中,我们用以下方式指定它:float(“inf”)、float(“-inf”)。
为了处理null或NaN值,我们必须将handleInvalid参数指定为某个值。我们可以保留这些值(keep)、error或null,或者跳过这些行。下面是一个使用bucketing的例子:

除了基于硬编码值进行分割外,另一个选项是基于数据中的百分位数进行分割。这是使用QuantileDiscretizer完成的,它将把值存储到用户指定的buckets中,分割由近似的分位数值确定。例如,第90分位数是数据中90%的数据低于该值的点。通过使用setRelativeError为近似分位数计算设置相对误差,可以控制buckets的柔和分割程度。Spark允许您指定希望从数据中提取的buckets的数量,并相应地分割数据。下面是一个例子:

高级bucketing技术
这里描述的技术是bucketing数据最常见的方法,但是Spark中还有许多其他方法。从数据流的角度来看,所有这些流程都是相同的:从连续数据开始,并将它们放在buckets中,以便进行分类。差异的产生取决于计算这些buckets的算法。我们刚才看到的简单示例很容易集成和使用,但是在MLlib中也可以使用更高级的技术,比如局部敏感性哈希(LSH)。
25.5.2.缩放和规范化
我们了解了如何使用bucketing从连续变量中创建分组。另一个常见的任务是对连续数据进行伸缩和规范化。虽然并非总是必要的,但这样做通常是最佳实践。当您的数据包含基于不同比例的许多列时,您可能希望这样做。例如,假设我们有一个包含两列的DataFrame:weight重量(盎司)和height高度(英尺)。如果不进行缩放或标准化,算法对高度变化的敏感度就会降低,因为以英尺为单位的高度值要比以盎司为单位的重量值低得多。这是一个应该缩放数据的例子。
标准化的一个例子可能包括转换数据,使每个点的值都表示其与该列平均值的距离。用之前的例子,我们可能想知道一个人的身高离平均身高有多远。许多算法假设它们的输入数据是标准化的。
正如您所想象的,有许多算法可以应用于我们的数据来缩放或标准化它。这里没有必要一一列举它们,因为它们包含在许多其他文本和机器学习库中。如果您不熟悉这个概念的细节,请查阅前一章中提到的任何书籍。只要记住基本目标——我们希望我们的数据具有相同的scale,以便能够以一种合理的方式轻松地相互比较。在MLlib中,这总是在Vector类型的列上完成。MLlib将遍历给定列中的所有行(类型为Vector),然后将这些列中的每个维度视为自己的特定列。然后,它将在每个维度上分别应用缩放函数或归一化函数。
一个简单的例子可能是列中的以下向量:

当我们应用缩放(而不是归一化)函数时,“3”和“1”将根据这两个值进行调整,而“2”和“4”将根据彼此进行调整。这通常称为组件比较。
25.5.3.StandardScaler特征缩放
StandardScaler将一组特征标准化为均值为零,标准差为1。withStd标志将数据缩放到单位标准差,而withMean标志(默认为false)将在缩放数据之前将数据居中。
警告
对稀疏向量居中可能非常昂贵,因为它通常会将它们转换为密集向量,所以在对数据居中之前要小心。
下面是一个使用StandardScaler的例子:
25.5.4.MinMaxScaler
MinMaxScaler 转换由向量行组成的数据集,将每个特征调整到一个特定的范围(由setMin方法和setMax方法设置范围,通常是 [0,1] )。

25.5.5.MaxAbsScaler
MaxAbsScaler通过将每个值除以该特性中的最大绝对值来缩放数据。因此,所有值都在- 1和1之间。该转换器在处理过程中根本不移位或居中数据,因此不会破坏任何的稀疏性:

25.5.6.ElementwiseProduct元素智能乘积
ElementwiseProduct允许我们将向量中的每个值缩放一个任意值。例如,给定下面的向量和行“1,0.1,-1”,输出将是“10,1.5,-20”。“缩放向量的维数自然必须与相关列内向量的维数相匹配:

25.5.7.Normalizer
normalizer允许我们使用通过参数“p”设置的几个幂范数中的一个来缩放多维向量。例如,我们可以使用带p = 1的曼哈顿范数(或曼哈顿距离),带p = 2的欧氏范数,等等。曼哈顿距离是一种测量距离的方法,你只能沿着一条轴线(就像曼哈顿的街道)从一个点到另一个点。
下面是使用Normalizer的一个例子:

25.6.处理分类特征
分类特征最常见的任务是indexing索引。索引将列中的分类变量转换为可以插入机器学习算法的数值变量。虽然这在概念上很简单,但是要记住一些重要的注意点,这样Spark才能以稳定和可重复的方式完成此任务。
通常,为了一致性,我们建议在预处理时重新索引每个分类变量。这对于长期维护您的模型很有帮助,因为您的编码实践可能会随着时间而改变。
请在公众号中阅读本章剩下的内容。