将机器学习从实践转移到生产
随着对神经网络和深度学习的兴趣日益浓厚,个人和
公司声称在其日常工作流程和产品中不断增加人工智能的采用率。
再加上AI研究的迅捷速度,新一轮的流行浪潮显示了解决其中一些难题的巨大希望。
就是说,我觉得这个领域在欣赏这些发展与随后部署它们以解决“现实世界”任务之间陷入了鸿沟。
已经出现了许多框架,教程和指南,以使机器学习民主化,但是它们规定的步骤通常与需要解决的模糊问题不吻合。
这篇文章是一个问题的集合(有一些(甚至是错误的)
答案)在将机器学习应用于
生产。
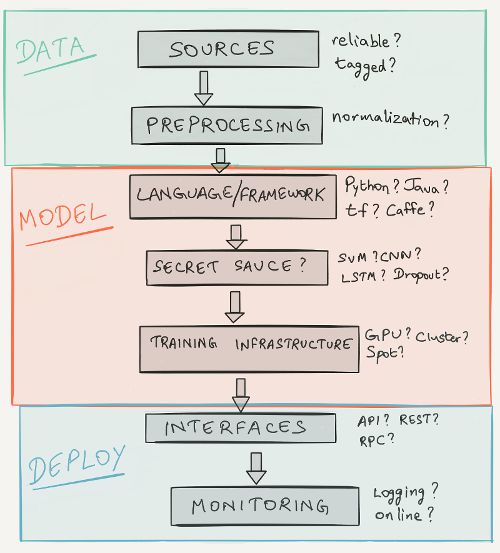
垃圾进垃圾出
我有可靠的数据源吗? 我从哪里获取数据集?
在开始时,大多数教程通常都包含定义明确的数据集。
无论是MNIST还是Wikipedia语料库,或者是
在UCI机器学习存储库中 ,这些数据集通常不能代表您要解决的问题。
对于您的特定用例,可能甚至不存在适当的数据集,并且
建立数据集可能需要比您预期更长的时间。
例如,在Semantics3,我们解决了许多电子商务特定的问题,从产品分类到产品匹配再到搜索
相关性 。 对于这些问题中的每一个,我们必须仔细研究并花点时间
大量努力来生成高保真产品数据集。
在许多情况下,即使您拥有所需的数据,也可能需要大量(且昂贵 )的体力劳动来对数据进行分类,注释和标记以进行培训。
将数据转换为输入
需要哪些预处理步骤? 在与算法一起使用之前,如何规范数据?
这是通常独立于实际模型的又一个步骤,在大多数教程中都被掩盖了。 当探索深度神经网络时,这种遗漏显得更加明显,在深度神经网络中,将数据转换为可用的“输入”至关重要。
尽管存在一些用于图像的标准技术,例如裁切,缩放,零中心和白化,但是最终决定权仍然取决于每个任务所需的归一化级别。
使用文本时,该字段变得更加混乱。 大写
重要? 我应该使用令牌生成器吗? 单词嵌入呢? 我的词汇量和维度应多大? 我应该使用预先训练的向量,还是从头开始或分层?
没有在所有情况下都适用的正确答案,但与可用选项保持同步通常是成功的一半。 spaCy的创建者最近发表的一篇文章详细介绍了一种有趣的策略,用于标准化文本的深度学习。
现在开始吧?
我使用哪种语言/框架? Python,R,Java,C ++? Caffe,Torch,Theano,Tensorflow,DL4J?
这可能是最自以为是的问题。 我是
仅出于完整性考虑,在此处包括本节,很高兴为您指出可用于做出此决定的 各种 其他 资源 。
虽然每个人的评估标准可能不同,但我的
只是简化了自定义,原型制作和测试。 在这方面,我更倾向于从scikit-learn开始,并在我的深度学习项目中使用Keras 。
其他问题,例如我应该使用哪种技术? 我应该使用深
或浅层模型,CNN / RNN / LSTM呢? 同样,有很多资源可以帮助您做出决策,这也许是最多的
人们谈论“使用”机器学习时讨论的方面。
训练模式
如何训练我的模型? 我应该购买GPU,自定义硬件还是ec2(现货)实例? 我可以并行化它们以提高速度吗?
随着模型复杂性的不断提高,以及对处理的需求不断增加
功率,这是生产过程中不可避免的问题。
十亿参数的网络可能会保证其出色的性能
TB级的数据集,但是大多数人都无法承受训练仍在进行中数周的等待。
即使使用更简单的模型,跨实例构建,训练,整理和拆除任务所需的基础架构和工具也可能令人生畏。
将时间花在计划基础架构 ,标准化设置和尽早定义工作流程上可以为您构建的每个其他模型节省宝贵的时间。
没有系统是孤岛
我需要进行批量或实时预测吗? 嵌入式模型或接口? RPC还是REST?
除非它与您的生产系统的其余部分连接,否则您的99%验证准确性模型没有太大用处。 这里的决定
至少部分由您的用例驱动。
将简单的权重直接打包到您的应用程序中的模型可能会令人满意地执行,而更复杂的模型可能需要与集中式重型服务器进行通信。
在我们的案例中,我们的大多数生产系统都批量离线执行任务,而少数生产系统则通过基于HTTP的JSON-RPC进行实时预测。
知道这些问题的答案也可能会限制
构建模型时应考虑的架构。 建立一个复杂的模型,只是为了以后知道它不能部署在您的内部
移动应用程序是一场灾难,可以轻松避免。
监控表现
如何跟踪我的预测? 是否将结果记录到数据库? 网上学习呢?
在构建,训练并将模型部署到生产中之后,任务是
除非您已经安装了监视系统,否则仍然无法完成。 确保模型成功的关键因素是能够测量和量化其性能。 在这个领域有许多问题值得回答。
我的模型如何影响整体系统性能? 我要哪个号码
测量? 该模型是否正确处理了所有可能的输入和方案?
过去使用过Postgres,我更喜欢使用它来监视我的模型。 事实证明,定期保存生产统计信息(数据样本,预测结果,异常值)对于在部署过程中执行分析(和错误事后验算)非常有用。
要考虑的另一个重要方面是在线学习要求
您的模型。 您的模型应该动态学习新功能吗? 当气垫板成为现实时,产品分类程序应该将其放置在“ 车辆 , 玩具”中还是将其保留为未分类状态 ? 同样,这些是在构建系统时值得辩论的重要问题。
包起来
这篇文章提出的问题多于答案,但这确实是重点。 随着新技术,小区和层以及网络体系结构的许多进步,错过森林比以往更容易。
从业人员需要对端到端部署进行更多讨论,以推动该领域的发展并使真正的大众化机器学习民主化。
最初发布在 engineering.semantics3.com上 。
From: https://hackernoon.com/moving-machine-learning-from-practice-to-production-a476451161e5