为Python程序员准备的C++知识
目标
- 了解C++的编译过程。
- 了解C++的内置数据类型、输入/输出、决策语句和循环语句这些主要组成部分的语法和语义。
- 了解C++的数组的语法和用法。
- 了解C++的函数和参数传递机制的细节。
- 了解C++的变量的作用域和它的生命周期。
8.1 概要
本书前面部分的章节重点介绍了如何使用Python语言来开发算法和数据结构。Python具有相对简单的语法,以及强大的内置数据结构和函数库,所以它是一个非常适合于初学者的优秀语言。目前看来,Python在行业内的使用量正在持续增长。然而,即使Python已经是最常用的语言之一,计算机科学家也应该知道若干种其他不同的计算机语言。不同的编程语言提供了不同的功能,这就让任何一个单一的编程语言都不会是所有问题的最好选择。不同的编程语言具有不同的能力,而这将会鼓励你不断地去思考解决问题的更多方法,因此学习新的编程语言有助于扩展你解决问题的能力。
Python语言的数据结构和许多内置函数隐藏了程序的许多底层实现细节。正如我们之前讨论的那样,使用Python的时候,你不必像在使用某些语言的时候那样,担心内存释放相关的操作。很明显,当人们在开发更高级别的语言,并为这些语言编写解释器和运行时环境的时候,需要了解实现它们所需要的所有底层细节。应该明白的一点是,Python一般来说并不是处理大量数据或者需要大量计算的应用程序最好的语言。这是因为,它使用了额外的内存来存储每个对象的引用计数以及这个对象的数据类型。而且,它的解释器在执行的时候,还必须要把这个Python的执行语句从字节码转换成机器代码。
在这一章和接下来的4章里,我们将会介绍C++编程语言的一个很大的组成部分。C++对Python程序员来说,是非常优秀的补充语言,这是因为它是一种相对来说级别较低的语言。它需要你了解许多底层实现的细节,其中就包括了内存管理。C++可以更有效地使用计算机的内存和CPU。能够同时使用Python和C++编程,你就能够在解决给定问题的时候选择更恰当的语言。在实际工作中,当算法的速度和内存使用很重要的时候,Python程序通常都会去直接使用已经编译好的C或C++代码。
8.2 C++的历史和背景
C语言是在20世纪70年代早期开发出的一个跨平台系统语言。在20世纪60年代的时候,当一台计算机被制造出来之后,每台机器都会装上使用汇编语言编写的新的操作系统。于是,AT&T贝尔实验室的布莱恩·柯林汉(Brian Kernigan)和丹尼斯·里奇(Dennis Ritchie)决定开发一种用于系统代码的高级跨平台语言。他们和肯·汤普逊(Ken Thompson)一起用C语言开发了UNIX操作系统,而且,他们可以轻松地把这个操作系统移植到新的计算机硬件上。直到现在,C语言仍然被广泛地用在对于速度至关重要的应用里,比如说像操作系统和科学计算这些地方。事实上,Python的解释器就是用C语言编写的。
在20世纪70年代末和80年代初的时候,计算机科学家们开始意识到:面向对象设计以及面向对象的编程将能够允许他们编写出更易于维护以及可重用的代码。当时有若干个已经存在了的面向对象语言,但C语言在里面是最受欢迎的。在20世纪80年代早期,AT&T的比雅尼·斯特劳斯特鲁普(Bjarne Stroustrup)决定开发一种对C程序员来说相对容易学习的新的面向对象的语言。他为C语言添加了显式的面向对象编程的支持,并称这个新语言为C++。除了会使用独有的新关键字之外,C++基本上是向后兼容C语言的,这也就使得C语言的程序员可以很容易地使用C++。完整的C++语言比C语言更庞大、更复杂,许多程序员在编写C++代码的时候只会使用C++的一部分功能。
C和C++是比Python更低级的语言。C语言不提供内置的列表和字典类型。C++语言则使用了被称为标准模板库的类和方法集来支持一些更高级别的数据结构。相比Python而言,C和C++显得更简洁,而且它们使用了更多的特殊字符(比如,&&相当于Python的and,||相当于or)。新版本的C++除了特殊符号之外,也开始允许使用and和or了。
这本书里主要使用的是C++语言,然而,在这一章里包含的大部分内容也同样适用于C语言。后面章节里的一些话题也同样适用于C语言,但在通常来说,我们不会明确地去指出什么部分适合于C语言。简单来说,任何涉及类的部分,都不会适用于C语言。
当你读到前面的段落的时候,你肯定会问为什么你需要学习C++语言,用它来编写代码看起来会更难一些。在你发现编写C++代码更困难的同时,你还会发现在执行相同操作的情况下,C++源代码几乎总是比Python源代码更长。但是,Python并不是适用于所有应用程序的最好的语言。使用C或C++这类编译语言所编写的代码,通常来说执行速度会比Python代码快一个数量级。而且,这些代码所使用的内存也会比解释相应的Python代码要少。直到现在,在许多应用程序领域,你仍然会希望能够最大限度地提高执行速度,并且有效地利用内存,从而让你的代码可以处理大量数据。比如说,你肯定不希望用Python来编写操作系统,或者像是Web服务器以及数据库服务器这样的服务器。最后,学习C++还可以帮助你更好地理解Python解释器里的细节。
C和C++源代码将会被编译成机器语言代码,而Python使用的则是混合过程,在这个混合过程里,源代码将会被编译成字节码,然后通过解释这些字节码来执行。两种方法都各有优缺点。编译代码的执行速度比解释代码快得多,但是不如解释代码灵活。我们将在后面的章节里讨论它们之间的一些差异。编译C++代码过程可以用图8.1所示的图形来表示。我们将使用下面这个简单的C++程序来描述编译过程的工作原理:
// hello.cpp #includeusing namespace std; int main() { cout << "hello world\n"; return 0; }
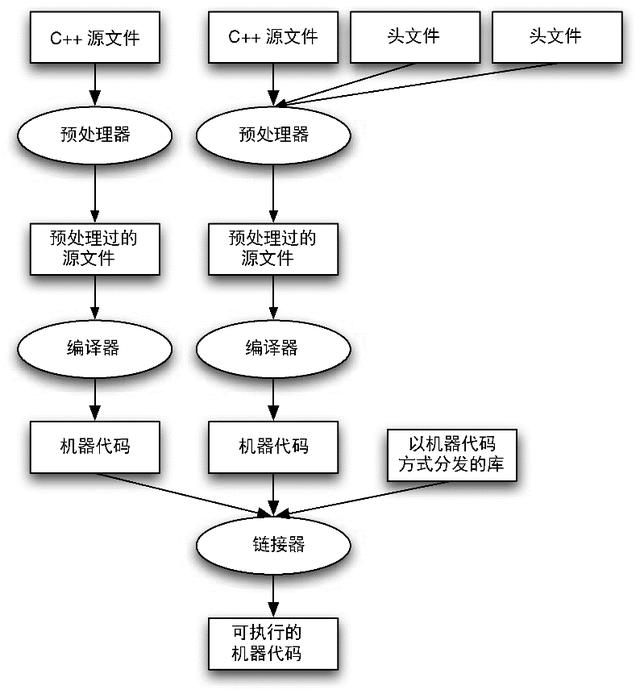
图8.1 C++代码的编译和链接过程
如果告诉你cout是用来产生输出的,你可能就已经能够猜到这个程序和print "hello world"这样的Python程序做的是同一件事了。预处理器(通常被称为C预处理器,C preprocessor)获取到源代码之后,会处理所有以井号(#)开头的行。示例程序中的#include预处理程序指令会告诉预处理器将iostream文件里的所有代码复制到我们的源文件里。这和我们把这个文件里的内容复制粘贴到#include语句所在的程序里的效果是一样的。iostream文件被称为头文件(header file)。每个C++源文件可以包含任意数量的头文件。我们将会在这一章的后面以及之后的章节里更详细地讨论头文件的细节。现在,你需要知道的是,头文件包含了一些关于在其他文件里编写的源代码的信息。
预处理器的输出结果仍然是C++源代码,然后它们会被送到C++编译器。编译器的工作是将C++源代码转换为特定芯片和特定操作系统的机器语言代码(计算机CPU可以执行的0和1)。编译器执行的第一步是检查代码里是否存在任何语法错误。这是因为存在语法错误就意味着程序是不正确的,会导致编译器将无法确定你的代码的意思,从而不能完成整个过程。如果你的代码有语法错误的话,编译器就会停下来,并且向你显示一条错误消息,这条消息会指向它无法理解的那部分内容。这也就意味着,在修复所有的语法错误之前,你是没办法尝试运行这个程序的。当源代码语法都正确之后,编译器将会生成与C++源文件中的代码相对应的机器语言代码。这种机器语言代码通常也被称为目标代码(object code)。
就像我们会把Python程序拆分成多个文件一样,除最简单的C++程序以外的所有程序通常都会被分成多个源文件。和图8.1里所展示的一样,每个源文件都是会被独立编译的。一个源文件可以调用另一个源文件里定义的函数。这也是使用头文件的主要原因:通过包含在另一个文件中定义的函数的有关信息,编译器才可以知道你是不是正确地调用了这个函数。链接器(linker)的工作是:把各个机器代码的目标文件组合成一个可执行程序,并且确保每个被调用的函数都存在于其中的一个目标文件里。大多数操作系统也支持机器代码库,这个库里包含常用的类以及函数的目标/机器代码。在C++里,输入和输出语句是iostream头文件所声明的库中的一部分。在最后,就像图8.1里一样,链接器还会把程序里使用的库里的代码复制到最终的可执行代码里去。
由于生成的可执行程序是机器语言,因此它只能在支持这个机器语言和操作系统的计算机上被执行。比如,为运行Windows操作系统的英特尔芯片所编译的程序,一般来说可以在任何与英特尔芯片兼容的计算机(同一代或更新版本的英特尔芯片)以及相同版本或者更新版本的Windows操作系统上运行。但是,在使用英特尔芯片的计算机上为Linux操作系统编译的程序,通常都不能在Windows系统上运行,反之亦然。对于简单的C/C++程序来说,可以对另一个操作系统或计算机芯片重新编译,从而达到移植(porting)程序的效果。移植程序是指让程序能够在不同的芯片或者操作系统上执行的过程。将代码移植到另一个操作系统真正的困难在于,不同的操作系统有不同的功能库来支持输入/输出以及图形用户界面(Graphical User Interfaces,GUI)。许多操作系统都提供了额外的代码库。使用了任何这些特定某个操作系统的代码库的程序,通常来说都很难移植到其他操作系统。在这种情况下,移植程序将需要把这些库也移植到其他操作系统上,或者重写这部分代码来避免使用这个代码库。
Python代码与机器是无关的,它可以在任何包含Python解释器的机器上被执行。这就意味着,Python解释器本身就必须要为这个计算机以及操作系统进行单独的移植和编译。如果你的程序使用了特定于某个操作系统的额外的Python模块(例如仅存在于某个操作系统上的GUI工具包),那么你的Python代码将不能被移植到其他操作系统上。如果你只使用了Python的标准模块,那么Python程序将能够在不需要对代码进行任何修改的情况下,在任何包含解释器的机器以及操作系统上运行。当然,就像Python解释器可以在许多不同的系统上编译来支持它们一样,许多额外的模块也是可以被移植到其他操作系统的,很明显,这就需要更多的工作来完成了。
执行Python代码的过程与编译和链接C++代码的过程有很大不同。图8.2用图像表示了这个过程。可以看到,你只能直接执行一个Python文件。但是,你可以通过导入其他Python文件来有效地组合多个源文件的代码。Python源代码首先会被编译成与机器无关的指令集,它们被称为字节码。当你运行Python程序或者导入Python模块的时候,都会自动发生这个过程。你可能已经发现了,在你的计算机里有一些以.pyc为扩展名的文件,这些就是导入Python模块的时候所创建的字节码文件。一个字节码指令对应的是函数调用,或者是添加两个操作数之类的代码。
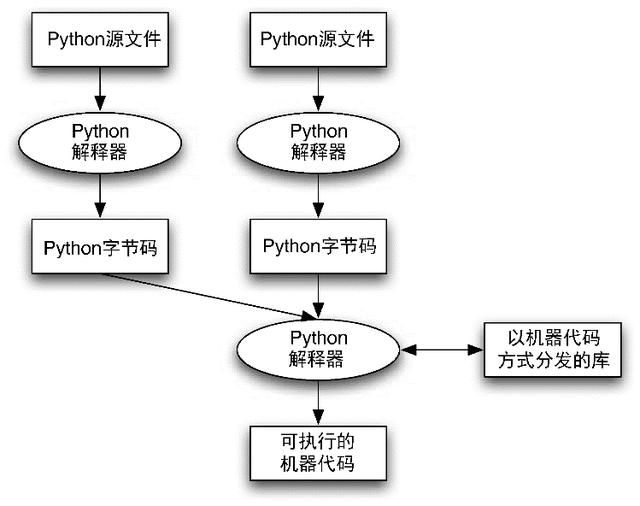
图8.2 Python编译和解释的混合过程
在编译成字节码之后,Python解释器就会开始处理与程序里的第一个语句所对应的字节码。每次处理字节码语句的时候,这段代码都会被转换为机器语言,进而被执行。就是在这个过程里,解释器解释了每一个字节码语句,并且在每次执行字节码的时候都把它转换为机器语言,这也就是为什么Python代码的执行效率比编译过的C++代码要慢。然而,字节码可以比纯粹的Python源代码更快地被转换为机器语言。这也就是为什么Python会一次性地先把所有的源代码都转换为字节码,而不是在执行每一个Python语句的同时将它转换为机器语言。
在之后,就像图里所展示的那样,你的Python代码可以调用在机器代码库里已经编译好了的C或C++代码。这也就能够让你在自己的程序里混合使用Python、C和C++ 3种代码。编写可以被Python解释器调用的C或C++代码需要遵循一些特别的约定,我们不会在书里详细介绍这一部分内容。对于任何你希望在Python里调用的C或C++代码,都必须要在对应版本的操作系统以及相应的芯片上进行编译。
当在Python里编写显式的循环调用时,Python和C/C++之间的执行的速度差异将会变得非常明显。因此,对于大型迭代来说,最好是调用内置的Python方法或函数,而不是直接编写这个循环来执行相应的操作(如果存在的话)。这是因为Python里内置的方法或函数都是通过编译了的C代码来实现的。比如说,你应该已经注意到了,1.3.1小节里我们手动编写的线性搜索功能和使用index方法的性能差别。总之,权衡应该使用Python还是C/C++的主要因素是:执行速度和代码量以及开发时间之间的关系。
Python和C++的基本语句是类似的。因此,对于Python程序员来说,学习阅读C++代码相对会比较容易。然而,学习编写C++代码会比较困难,这是因为编写相应的代码需要你去学习C++的具体语法细节。但是,Python程序员学习C++还是会比没有编程经验的人更容易。毕竟,已经了解了一种编程语言的程序员也就已经理解了一些基础知识,像是决策语句、循环、函数这类的常用概念。许多编程语言,包括C、C++、Python、Java、C#以及Perl,它们都使用了相似的语句和语法来让这门语言能够和其他语言一样易于学习。我们通常会认为Python是初学者的理想语言,因为它的语法够简单;C++是一种很好的第二语言,因为它类似于Python,但又同时能够让大家获得Python解释器所隐藏的底层编程细节的相关知识。
这一章和接下来的几章里所介绍的许多C++的概念一般来说也同样会适用于C语言,但并不是全部的概念都相通。具体来说,输入/输出机制在C和C++里是不同的,这是因为C语言并不完全地支持类。这本书不会涉及在C语言里的输入/输出或者是C语言里的类的简化版本——结构。书里的这些关于C++的章节并不是要让你了解C++语言的所有细节,而是要让一个Python程序员可以快速地开始使用C++语言,并且帮助你了解显式的内存管理的细节。要成为C++专家,我们建议你去阅读如比雅尼·斯特劳斯特鲁普撰写的C++的参考书这样的相关书籍。由于C++是一种相当复杂的语言,因此在编写完整的C++程序之前必须要掌握许多相关知识。我们将在学习过Python的基础之上开始介绍这些概念。
8.3 注释、代码块、变量名和关键字
C++支持两种类型的注释。和Python里的#注释标记相对应的是两个正斜杠(//)。一行里从两个正斜杠开始到行尾的任何字符都将被视为注释,从而被编译器所忽略。同时,C++编译器还支持多行注释,这种注释以/*开头,以*/结尾:
// this is a one-line C++ comment /* this is a multi-line C++ comment */
Python使用缩进来表示代码块。而在C++里,使用大括号对({})来标记代码块的开头和结尾。在C++中,缩进除了让代码更易于阅读之外,不会有任何效果。因此,为了易读性,程序员们通常还是会遵循和Python相同的缩进规则。空白(空格、制表符和换行符)除非是在字符串里,否则对C++代码不会产生影响。而由于空格、制表符和换行符在C++中没有任何作用,因此,每个C++语句都必须以分号作为结束。于是,对于熟悉Python的程序员来说,在语句结束的地方忘记了分号是非常常见的一个错误。更麻烦的事情是,当你忘记分号的时候,许多C++编译器都会显示下一行代码存在问题。因此,在跟踪编译错误的时候,通常需要查看编译器指示存在错误的代码行的上面一行或多行代码。
合法C++变量名的规则与Python的规则是相同的:变量名必须以字母或下划线开头;在首字母或下划线之后,后续的字符可以是字母、数字或者是下划线;除此之外,变量名也不能是C++的关键字。图8.3列出了C++所有的关键字。[1]但是在本书里,将不会涵盖所有C++的关键字的详细信息。

图8.3 C++的关键字
8.4 数据类型和变量声明
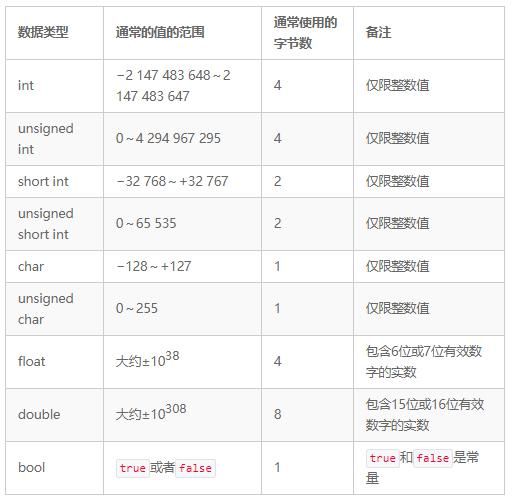
和Python不同的是,C++要求所有变量在使用前都必须要被显式地声明。C++支持int、char、float、double以及bool这些内置的数据类型。在使用指定的数据类型声明变量之后,变量就只能保存这个类型的数据值了。int类型对应于Python中的整数类型,并且也支持相同的操作,包括模数运算符(%)。但是,与Python不同的是,Python里的整数会根据需要自动地转换为长整数,而C++的int类型在值太大而无法存储的时候会静默地溢出。C++的int类型必须至少使用16位内存,也就是说它合法的值大约在−32 000~+32 000范围内。然而,大多数系统使用的内存都至少是32位,也就是说它可以存储的合法数字在−20亿~+20亿这个范围之内。char类型则会被用来存储单个字符。在内部,它存储的是字符的ASCII值,因此char变量可以存储介于−128~+127的值。
C++的int类型还支持修饰符short和long。在大多数32位系统里,short int是16位,int是32位,而long int也是32位。它们的区别是:long int类型保证至少使用32位内存,而int仅仅保证至少使用16位内存。int和char类型也都支持unsigned修饰符,这个修饰符被用来表示变量只支持非负数,从而允许更大的值。32位unsigned int大约可以支持0~40亿的数字,而不是−20亿~+20亿之间的值。unsigned char则可以存储0~255的值。
float和double数据类型对应的是被数学家们称为实数的类型,但是在计算机里,它们并不是被完整地存储的。这是因为,在内部它们只能使用0和1的位来表示这个实数,因此,它们其实更适合被称为浮点数(floating point number)。float类型使用32位内存来存储数字,并且提供6位或7位有效十进制数字。double类型使用64位内存来存储数字,并且提供15位或16位有效十进制数字。在Python里,它使用的是C语言的double类型来实现的浮点数。这是因为,现代计算机都具有足够大的内存,并且现在大多数浮点运算都是在硬件中实现的,所以在几乎所有情况下都应该使用double类型而不是float类型。表8.1总结了C++数据类型的一些细节。
在C++里,变量可以在代码块的任何一个地方被定义;之后,从这个地方开始,一直到这个代码块的末尾,都能访问到它们。出于对代码格式以及可读性的考虑,许多C++程序员会在代码块的顶部声明这部分代码将会需要的所有变量。声明变量是通过指定类型,然后在类型之后跟着变量名来完成的。在声明变量的同时也可以用逗号分隔变量名,这样就可以在一行上声明多个相同类型的变量了。下面的代码片段展示了一个包含变量声明的简单程序。根据我们之前的内容可以知道,cout被用来生成输出,因此,利用Python的相关知识,你应该能够猜到这个C++程序最终会输出的内容:
// output.cpp #includeusing namespace std; int main() { int i, j; double x, y; i = 2; j = i + i; x = 3.5; y = x + x; cout << j << "\n" << y << "\n"; return 0; }
你可能会想,为什么C++要求你声明变量,而Python并不需要你这样做。要知道,C++代码会被直接编译为机器语言,而机器语言的指令是基于特定的数据类型的。比如,所有的CPU都有用来添加两个整数的指令,而且大多数现代CPU甚至还有添加两个浮点数的指令。一些老式的CPU没有直接的浮点指令,但是可以通过使用多个整数指令在软件里实现浮点计算,而这样的操作会使浮点运算慢不少。在这个例子里,编译器需要知道数据类型来为j = i + i这个添加两个整数的语句生成机器指令;也需要知道数据类型来为y = x + x这个添加两个浮点数的语句生成机器指令。因此,指示了数据类型的变量声明,将能够允许编译器编译出正确的机器指令。
而Python解释器则会把这两个相对应的Python添加语句,比如add i, i和add x, x,转换为相同的字节代码。也就是说,相同的字节代码会被用来表示这两种不同情况下的add语句。然后,当Python解释器执行这部分字节代码的时候,它才会去确定这两个操作数的数据类型,从而在第一种情况下生成整数add指令,在第二种情况下生成浮点add指令。如果两个操作数是字符串,那么它将生成连接两个字符串的机器指令。于是乎,由于Python在真正执行这个语句之前不会创建机器指令,因此在编写代码的时候,它不需要像C++编译器那样需要先知道数据的类型。这样,在Python里,即使相应的变量的数据类型在语句多次执行之间发生了变化,代码也可以正常工作。下面这个看起来挺蠢的Python程序就表示了这个例子。在第一次循环的时候,语句x + x添加了两个整数,而在第二次循环里它被用来连接两个字符串。在C++里,如果不为每种不同的数据类型使用单独的变量的话,这段代码是不可能正常工作的:
for i in range(2):
if i == 0:
x = 1
else:
x = 'hi'
print x + x
这类问题的术语是动态类型(dynamic typing)和静态类型(static typing)。Python使用了动态类型,这也就意味着变量或名称的数据类型是可以更改的。相应地,C++使用的是静态类型,也就是说特定变量的数据类型在编译时是固定的,是不能更改的。Python和C++在处理变量方面的另一个显著区别是:C++的变量在函数被调用的时候就被分配好了内存,并且在执行函数的时候,这个变量会继续使用相同的内存位置。然而,纯理论来说,在Python里使用术语变量是不正确的,而应该使用术语名称。Python的名称是指存储在内存中的某个对象。在执行Python函数的过程中,名称所引用的内存位置是可以改变的。我们在4.2节里曾经讨论过这个话题。在下面这个简单的程序里,名称x引用了两个不同地址里的两个不同对象:
x = 3 x = 4
Python的名称在它被使用之前是不会分配相应的内存地址的,而且,在每次把新对象分配给它的时候,这个内存地址都会更改。然而,C++的变量将会一直使用一个特定的被分配的内存位置,并且在执行期间一直都不会被改变。因此,相同的内存位置会被用来存储3以及之后的4。我们将在第8.7节和第10章里更详细地研究这个问题。
C++还支持常量和编译时的检查,来保证程序不会尝试更改某个值。例如定义一个常量const double PI = 3.141592654;。在程序里定义了这个常量之后,如果还包含另一个为这个常量赋值的语句(例如,PI = 5)的话,那么就会发生语法错误,程序将无法编译。许多程序员都使用全大写字母的名字来表示常量。
C++不像Python那样提供了许多内置的像列表、元组和字典这样的高级数据结构。C++支持可以被用来构建类似数据结构的数组(在8.11节里介绍)。正如你所期望的那样,因为C++是一种面向对象的编程语言,所以它提供了类来让你去封装数据成员和相应的函数。因此你可以去构建用来操作相应数据的列表、元组以及字典类。我们将在9.1节讲解C++类。
8.5 Include语句、命名空间以及输入/输出
Python里使用import语句来访问另一个文件里编写的代码。在C++里,将会使用#include语句来把在不同文件里定义的类和函数声明复制到当前文件里,从而让编译器可以检查这些函数或者类有没有被正确地使用。包含这些声明的文件称为头文件(header file)。头文件除了包含类和函数声明之外,还可以包含一些其他的元素,但我们现在不用去关心这部分内容。关于函数原型的细节部分将会在8.12节里讨论,它的基本思想是:函数原型指定了参数的数量、每个参数的数据类型以及函数的返回类型。函数原型能够让编译器创建一个列表来包含所有存在的函数和类。因此,当你尝试调用文件里没有被定义过的函数的时候,编译器就可以判断在其他地方是不是已经声明了具有这个名称的函数,以及你是否使用了恰当的参数来调用这个函数。同样的概念也同样适用于类的定义,从而让编译器可以确定你是否正确地使用了一个类(也就是,存在一个具有这个名称的类,并且这个类里包含了你使用的这个方法)。头文件里通常不会包含函数以及类方法的代码,它只会包含相应的声明。一般来说,会有一个单独的实现文件来包含函数的定义(即函数体)。但是这个方面也有一些特例,我们将会在稍后的章节讨论这些特殊情况。函数和类的实际机器代码将会由链接器组合在一起,从而创建可执行代码(如图8.1所示)。我们将在这一章的后面介绍一些关于编译以及链接的其他详细信息。
与Python模块创建的命名空间一样,C++也支持类似的命名空间(namespace)技术。每个Python文件都是它自己的模块,这样也就直接地拥有了自己的命名空间。C++并不强制要求使用命名空间,但是很多内置的C++类和函数都是在命名空间里定义的。我们将在选读小节8.17.2里介绍如何编写自己的命名空间的相关细节。在本章的这部分内容里,我们将只介绍应该如何使用现有命名空间的基础知识。最常用的命名空间是标准命名空间,它的缩写为std,而且,这个命名空间是C++编程语言的定义的一部分。由于在std命名空间里声明了许多C++内置的函数和类,因此我们需要先知道如何使用命名空间,才能去编写C++程序。
C++使用函数库来处理输入/输出相关的操作,这就需要包含一个文件来访问这个函数库。访问这个函数库最简单的方法是将下面这段代码放在文件的顶部:
#includeusing namespace std;
正如我们前面提到过的那样,#include语句能够让C++编译器快速地把iostream头文件里的内容复制到你的文件里去,然后编译整个文件。这个头文件里定义了各种输入/输出相关的函数和类,这些函数和类都位于命名空间std里。C++输出语句使用的是iostream文件里定义的ostream类的cout实例。using namespace std这条语句将会告诉编译器,接下来的代码将允许直接访问std命名空间里定义的所有元素。这就像是Python里的包含语句from math import *一样,它将允许访问math模块里定义的所有元素。如果没有using语句的话,就只能使用std::cout这样的全称来引用它。另一个方案是:在包含语句之后使用using std::cout语句。这将能够让我们在使用cout实例的时候不用去指定std::前缀,但对于std命名空间里的其他任何成员,都不会允许我们直接访问。这在Python里也就类似于from math import sqrt这样的语句,它将能够让我们访问math模块里定义的sqrt函数,但不能访问math模块里定义的除它以外的其他任何元素。C++和Python的命名空间(每个Python文件是一个单独的命名空间)之间的主要区别在于:在C++里,即使不使用using语句,都始终可以使用全名(namespace::item)来访问C++命名空间里定义的元素;而对于Python命名空间来说,必须使用import语句来允许使用命名空间里的元素。
C++的cout实例与Python里的print语句的工作方式是类似的,它们都可以输出变量、表达式以及常量。Python使用逗号来分隔一个语句里输出的多个元素;而在C++里,则会使用符号<<来分隔在一个语句里输出的多个元素。同时,C++不会像Python那样在每个以逗号分隔的元素之间自动地插入空格,而且C++也不会像Python的print语句那样自动输出换行符。和Python类似的是,任何不在引号内的元素都会被执行。但是,必须使用双引号来表示C++的字符串。在C++里,单引号仅被用来表示单个字符(即内置的字符数据类型)。
所有的C++程序都必须要有一个名为main的函数(主函数),同时,这个main函数还必须要能够返回一个int值。在执行程序的时候,这个函数将会被调用。
把到目前为止所学到的概念汇总到一起,你就应该能够理解"hello world"代码示例里的大部分语法了:
// hello.cpp #includeusing namespace std; int main() { cout << "hello world\n"; return 0; }
和Python一样,C++也使用反斜杠来作为转义字符。上面的程序里使用了\n,从而能够在输出hello world之后输出一个换行符,这样新的输出将会换行。C++还允许使用在std命名空间里声明的endl(如果没有使用using namespace std这一行的话,就必须要用全程std::endl)来表示换行符。因此,上面的cout语句也可以写成cout << "hello world" < 与cout实例类似的,C++还有一个在istream类里的cin实例,它也是标准命名空间的一部分,用于输入。符号>>用来分隔多个输入的值。cin语句使用空格来分隔多个值,并跳过任何空白(空格、制表符或空行)来查找下一个数字、字符、字符串等。下面的程序和执行输出示例表示了你在第一门编程课程里学习过的程序以及它的执行结果。在这里,我们使用符号␣来表示源代码和输出的空格,这是因为cout并不会像Python的print语句那样自动输出空格以及换行: 如果我们将celsius变量声明为int类型,那么用户就只能输入整数值。这样做的话,会让这个程序不那么通用。因此,在声明变量的时候,你应该问一问自己,这个变量可能值是什么。如果它可能是浮点值的话,那么就应该使用double类型;但如果它只会是整数的话,就应该使用int类型。 当使用cin来输入多个值的时候,用户可以输入任意数量的空白来分隔各个值。用户可以通过输入一个或多个空格或者制表符来分隔两个值,或者是在输入每个数字后按回车键(Return)来输入数据。与Python类似的,在按下回车键之前程序不会去处理输入操作。下面是一个完整的代码示例,它展示了如何使用cin语句来输入两个值。我们将把这个程序基于特定输入的输出留作练习: 在C++里使用cin输入值会跳过空白这个现象,在使用它输入字符的时候会有一些麻烦。在读取数字的时候跳过空白肯定是应该的,但是,由于输入的值也是char数据类型,因此在使用cin读取char数据类型的时候,用户无法将自己输入的空白存储在char类型的内存空间里。比如说,如果用户在执行下面这个程序的时候输入的是x␣y␣z的话,程序的输出将会是xyz,而不是你所猜想的x␣y: 我们已经介绍了足够的背景知识了,因此你已经可以开始自己编写简单的C++程序了。我们在这里将会简单地讨论一下应该如何在你的计算机上编译程序。目前,3个最常用的操作系统分别是Microsoft的Windows、UNIX/Linux以及Mac OS X。这些操作系统都提供了相应的应用程序来编辑和编译程序。微软销售的是一个当前叫作Visual Studio的开发环境的完整版本。同时,它还提供了一个免费但有限的版本——Visual Studio Express。如果你使用的是Microsoft Windows,那么,你可以从Microsoft的网站上下载这个软件。尽管它没有完整版本里的所有功能,但对于这本书里的所有C++的示例和练习,它应该够用了。Apple向所有人都免费提供了名为Xcode的完整开发环境。它可能已经预先安装在了你的Mac计算机上,如果没有的话,你也可以从Apple的网站下载(在撰写这本书的时候是需要注册的,但是是免费的)。UNIX有许多不同的操作系统。我们不会在这本书里介绍UNIX的历史,但你需要知道不同的公司会销售略有不同的UNIX版本。事实上,Apple的Mac OS X就是建立在UNIX操作系统之上的。Linux操作系统是UNIX系统的免费克隆版本。在这本书里,我们将会使用术语UNIX来代表包括Linux在内的所有UNIX系统。 Visual Studio和Xcode的图形开发环境会随着时间的推移而发生变化,因此我们不会在这本书里详细介绍如何使用这些应用程序来编写和编译C++代码。因为是图形开发环境,因此你自己就可以很容易地弄清楚,或者在别人的指导下弄清楚应该怎么使用它们。在大多数的UNIX系统上,GNU g++编译器会被用来编译C++程序。当然,也有适用于各种UNIX系统的商业级的C++编译器。严格来说,Mac的Xcode也只是g++编译器的图形化前端,因此,你可以在Mac上直接通过终端来使用g++。由于g++的命令行用法在几年内都没有改变,所以我们将会介绍一下g++在UNIX系统上编译C++程序的基本用法。 C++程序的文件扩展名通常使用.cpp、.C以及.cc。在这本书的各个例子里,我们将使用.cpp扩展名,这是因为它被3个常用操作系统上的编译器所使用。对于不使用任何其他库、被称作program.cpp的单个文件来说,如果你的程序在语法上都是正确的话,命令g++ program.cpp -o program将会使用C++源文件program.cpp来创建一个名为program的可执行文件。你可能还记得在这一章开头跟编译相关的话题里所提到的多个步骤:预处理、编译以及链接。我们指定的g++命令执行了所有步骤。 根据UNIX系统上的make版本,指令make program也可能会产生相同的结果。但要记住,program.cpp文件里必须要包含一个main函数,这是program文件开始执行的地方。要执行这个程序的话,可以键入./program然后按回车键。在可执行程序名称前面加上./是用来确保操作系统在当前目录中执行这个程序最安全的方法。当然,根据你的UNIX账户的设置,你可能也可以只输入program来执行这个程序,但我们还是建议你养成输入./program的习惯,因为不论配置是怎样的,这个指令都是有效的。 和Python类似,我们最好把大的应用程序拆分为被良好组织的许多较小的源文件。就像我们在这一章的开头提过的那样,C++里的每个文件都会被单独编译,从而为这个文件中的C++代码生成相应的机器语言代码。那么,在使用g++的时候,每个以.cpp扩展名结尾的源文件都可以通过使用g++命令的-c标志来编译出一个扩展名为.o的目标文件。这个命令对应着预处理和编译这两个步骤。如果你不使用-c标志的话,g++的命令将会去尝试执行预处理、编译和链接3个步骤。然而,在你有多个源文件的时候,链接这个步骤是你不想执行的。 图8.4所示为如何编译两个源文件。这个例子里,main函数是在test_sort.cpp文件中。最后一行的指令是执行链接步骤,它将会检查test_sort.o文件是否包含一个叫作main的函数,以及所有文件调用的每个函数在这些以.o 为后缀名的文件里是否都只出现了一次。在这个例子里,我们还在g++命令里添加了-g标志,因此它的输出将会包含符号名称。这就让调试器能够提供有关变量和函数的实际名称的相关信息,而不仅仅是存储它们的内存地址。 图8.4 编译两个源文件 和大多数重复性的任务一样,这个过程也可以被自动化。UNIX操作系统提供了make命令,这个命令可以被用来重新编译自上次创建相应目标文件以来被修改的源文件,并且链接所有的目标文件。make命令将会查看名为Makefile或makefile的文件,这个文件被用来描述应该如何从源文件中创建可执行文件。图8.5所示为用于图8.4中的排序例子的Makefile文件的内容。 图8.5 test_sort的makefile 这本书里不会涵盖makefile的所有细节,但这个文件的基本思路是:带冒号的行里,在冒号的前面有一个文件的名称,冒号后面的若干个文件名则被用来表示这个文件所依赖的文件(也就是说,如果冒号后的文件被修改了,那么就需要重新生成冒号前的文件)。带冒号的行的下面一行用来指定如何生成上一行冒号之前的那个文件,并且这一行必须用制表符作为开头(就是说,你不能用空格来对这一行进行缩进)。当你输入了make并按回车键之后,它就会构建makefile里列出的第一个元素(在这个例子里,它会构建可执行的test_sort文件)。你还可以通过在make命令里后接另一个名称来告诉它应该在构建之后输出其他名称(也就是,你可以输入make linear_sort.o并执行它,它就会创建一个名为linear_sort.o的文件)。通常来说,clean指令会删除所有添加的目标文件和可执行文件,因此你可以通过键入make clean命令来删除所有对象,然后使用所有的源文件重建整个可执行文件。你可以在大多数介绍UNIX的书籍或者是网络上找到有关makefile的更多详细信息。但是,如果你使用的不是UNIX系统的话,集成开发环境(Integrated Development Environment,IDE)一般都会有用来自动编译程序的构建系统。 表达式在C++里和Python里是类似的,但是,C++不支持任意数据类型的赋值,而且也用了不同的布尔运算符。C++赋值语句的语法和Python是一样的,只是C++并不支持元组赋值语法;C++表达式右侧的数据类型必须与分配给它的在左侧的变量数据类型相互兼容。C++语言的赋值运算符的左侧只能有一个变量。要在C++里完成像Python语句x, y = y, x这样的功能,就必须要使用一个临时变量。下面这段C++代码展示了这一点: 这个程序的输出是: 在这个示例里,你可以看到所有变量都必须要事先声明,当然在声明语句里,也可以同时为变量分配一个初始值。C++也像Python一样支持x = y = z这样的赋值语句。它代表了y被z的值给赋值,然后y的值又赋值给了x。 如果忘记了在表达式里使用变量之前赋值的话,通常会产生一些奇怪的结果。下面这个程序在编译以及执行的时候都没有任何错误,但会产生不确定的结果。比如,在某一次执行的时候,它可能会输出134514708,而另一次执行则可能输出-3456782。 通常来说,在函数内部声明的本地变量被称为自动变量(automatic variable)。函数在开始的时候,会为自动变量分配一个内存位置,但不会对这个变量使用任何的值进行初始化。因此,在为它们分配一个值之前,它们将一直保留函数启动时这个内存位置里的任何值。这也就是为什么在每次运行上面那个例子里的程序的时候,你都可能会得到不同的结果。这种在C++里会发生的编程错误在Python里是没有的。在Python里,如果第一行代码就是y = x的话,那么将会抛出NameError异常,这是因为名称x并不存在。 前面有提到过,C++里支持的运算符和Python支持的运算符除了一些较小的语法差异[例如,表示逻辑与(and)的&&,表示逻辑或(or)的||,以及表示逻辑否(not)的!],基本上是相同的。运算符的优先级规则也是相同的,但是C++支持一些Python里没有的其他运算符。比如,C++提供的两个加号运算符是增量和减量运算符,这些运算符有前缀和后缀两个版本。它们可被用来让整数变量的值加1或者减1:加1的增量运算符是++运算符;相对应的,减量运算符是--运算符。这些运算符可以和赋值语句一起混用,也可以不和赋值语句一起混用。下面这个例子展示了增量运算符、减量运算符的工作方式是完全相同的,只是它们的作用一个是增1另一个是减1而已。看这段代码的时候要注意的一点是,前缀版本和后缀版本的增(减)量操作符的差异在与赋值语句一起混用的时候非常关键。所以,许多C++程序员为了让代码更清晰,会避免把增量和减量运算符和赋值语句一起使用: Python里的所有名称实际上都是对相应内存位置的引用。而每个C++的变量都指向了保存实际值的内存位置。将一个变量赋值给另一个变量的时候,在Python里的这两个变量都会引用相同的内存位置;然而在C++里,赋值运算符会把数据从赋值语句的右侧变量的内存位置复制到左侧变量的内存位置。还好,在只使用不可变类型的时候,C++和Python之间的这种差异并不太明显。与Python引用相对应的功能在C++里就是指针变量。你可以把引用理解为一个不带指针符号的指针。在第10章的内容里,我们将会介绍关于自动变量、引用以及指针的内存使用和分配的详细信息。 和Python一样,C++支持相同的基本条件语句——if语句。虽然有一些语法差异,但是整个语句的语义还是相同的。比如,在Python里的elif,在C++里使用的是两个单词else if。此外,C++还要求用括号把布尔表达式括起来,而Python不需要这样做。我们提到过,大括号对{}被用来标记代码块,因此,它也被用来指示当if语句的布尔表达式为真的时候,应该执行哪些代码。但是,C++里有一个特例,如果if语句为真的时候只执行一条语句的话,那么可以不用大括号。但是,如果在后面又去添加了第二条语句的话,就可能会导致混淆,从而产生错误。因此,许多程序员会通过总是使用大括号来避免这个问题。下面这个例子展示了这个问题: 这个程序的输出是: 在这个例子里,缩进是具有误导性的,代码行cout << "than y\n";在布尔表达式为假的时候,也会被执行。要知道,在C++里,缩进并不重要。要正确编写上面这个程序的话,就需要像下面这样使用大括号了: 这个程序的输出是: 在这段代码里,左大括号的位置并不是统一的。一些程序员喜欢把它放在与if语句相同的行,而其他一些程序员则喜欢把它放在下面一行。但是,几乎所有人都同意:右大括号应该在独立的一行上,并且应该与if语句或者{(如果左大括号在单独的一行上的话)相互对齐。许多程序员即使会把if语句以及其他的一些C++语句开头的左大括号放在与语句相同的行上,他们也会像我们例子里的main函数的左大括号一样,把函数开始的那个左大括号放在单独一行上。大多数公司都会选择其中一种方案,之后就会要求他们的程序员遵循这个代码风格,从而保证一致性和易读性。下面这个例子和上面的例子是一样的,只不过它的左大括号都在单独的一行上: 我们提到过C++里的缩进并不重要,但C++程序员通常还是会遵循与Python程序员相同的缩进规则,从而实现更好的可读性。虽然Python 允许任意数量的缩进来表示新的代码块,但大多数Python程序员都会使用4个空格来作为每一级的缩进。然而在C++程序里,并没有一个标准,程序员们会使用两个、3个、4个或者8个空格来作为缩进的级别,当然8个空格通常会用输入制表符键来表示。这本书里的示例都会使用两个空格作为缩进的级别,这是因为,我们认为大括号已经提供了额外的视觉提示来表示代码块。而且,更少的空格也意味着嵌套的代码块即使有更长的代码也不会超过80列(大多数程序员将代码行的长度限制在80列)。 如果在C++里没有遵循与Python相同的缩进规则的话,那么对于嵌套的if/else语句的语义来说,缩进可能反而会产生一些误导。在Python里,缩进清晰地表明了elif或else语句与if语句之间的匹配关系。在C++里,匹配if和else语句的规则基本上和Python是相同的。你只需要记住大括号标记了代码块,而且即使没有大括号,if或else语句之后的单个语句也可以是它自身的代码块。我们可以这样来描述这个规则:else语句将会和它上方最接近的那个处于同一级的大括号的if语句相互配对。下面这个例子只是一个代码片段,因为它不包含main函数和一个完整程序所有必需的语句,所以它并不是一个完整的程序,因此它也不会通过编译。但是,它在没有使用额外代码的情况下展示了一个编程理念。思考下面代码里的else语句与哪一个if语句相匹配: 第一个else语句与它上面两行的if (y < z)语句相匹配。可以看到,这条语句是这个else语句的同一级大括号的上方最接近的if语句。基于同样的理由,第二个else语句与它上面4行的if (x < y)语句相匹配。这个else语句和它上面两行的if (y < z)语句处于不同的括号级别。这个例子展示了要始终使用大括号的另一个原因:它能够让我们更容易去匹配else和if语句。 以下这个例子展示了嵌套的if语句以及else if语句。基于你对Python的了解以及前面提供的相关知识,这段代码的语义应该是很清晰的(并且,这个程序的执行与它的输出是匹配的)。唯一要注意的是,在C++里,必须用else if,而不能像Python那样写elif: 上面的这个例子使用了嵌套的if语句,它也可以被写成一个if语句后跟4个不嵌套的else if语句。我们在这里选择使用嵌套的这个版本来展示else if语句以及嵌套语句。 Python使用关键字and、or以及not布尔运算符。而在C++里,使用符号&&、||和!分别代表and、or和not。在C++里,等价于Python语句if (x < 3) and not (y > 4)的代码是if ((x < 3) && !(y > 4))。最新的C++编译器也开始在&&、||和!之外支持and、or以及not了。 与Python不同的是,C++允许在if语句和循环语句里的判断表达式中使用赋值语句。这就意味着,即使你并不想要在那个地方进行赋值,C++编译器也不会将if (x = 0)作为错误来处理。这个if语句有一个副作用会把x赋值为零,然后这个结果会被当作是这个布尔表达式。赋值语句的结果就是所赋的值,因此,这个语句就等同于:x = 0; if (0)。这也就是为什么赋值语句可以连接起来使用(就像x = y = 0这样)。因此,语句if (x = 0)的判断将会导致x被赋值为零,并且这个布尔表达式永远都会被评估为false。和Python一样,C++会把任何非零的值视为true,而将零视为false。例如,语句if (x = 10)会把10分配给x,并且这个判断将会评估为true。这种错误会非常难以调试。当使用常量作为判断的时候,一些程序员会写成if (0 == x)。用这种方式书写条件判断,如果忘了一个等号的话就会导致错误。但是,在你打算写if (x == y),而写成了if (x = y)这样的语句的时候,这个错误也会不可避免地产生。 同样,C++也支持switch条件判断语句,但在这一节里,我们不打算介绍它。因为任何可以用switch语句编写的逻辑也可以被写成if/else if语句。我们将会在选读的8.17.1小节里详细讨论switch语句。 在Python里,许多数据类型的转换都是隐式的。下面的Python代码例子里,在执行b + c的时候,从b这里拿到的数字3将会被隐式地转换为浮点值3.0,这是因为操作数c是一个浮点值。但是,名称b的值还是会继续保留为整数3,只是在计算的时候会被替换。在语句d = float(b)里,存储在b里的3将会被显式地转换为3.0并作为浮点数存储在d中。同样,b里的值仍然是整数3。在语句e = int(c)里,c的值(5.5)将被显式地转换为5,并且作为整数存储在e里。当一个浮点数被转换为整数的时候,它的小数部分会被截断而不是被四舍五入: C++也支持在表达式里进行显式的转换,以及各种隐式的类型转换。下面这个C++的例子对应着上面的Python示例。如果在d的赋值语句里不用显式转换,而是直接写为d = b;的话,大多数编译器都不会产生错误,但会产生一个警告,这个警告会指出这一行里包含了隐式的类型转换。当一个值从浮点类型转换为整数类型的时候,C++会使用和Python相同的规则——小数部分会被截断: 用括号来指定变量或者表达式的数据类型,虽然Python和C++都支持用这个语法来进行类型转换,但新的编译器所支持的新版本的C++代码有另一种不同的语法。下面这个例子里展示了使用关键字static_cast来进行数据类型转换的语法: C++支持3种循环语句:for、while以及do while。while循环和Python里的while语句基本上是相同的。因为while循环的布尔表达式是在循环体执行之前先检查条件,因此被归类为前测循环(pretest loop)。它在Python和C++之间的语法差异与if语句的差异是类似的。在C++里,while语句里的布尔表达式必须要放在括号里,而且,C++使用的布尔运算符是&&、||和!(前面提过,新的编译器也支持and、or以及not)。还有,大括号{}也代替缩进被用来表示代码块。和C++的if语句一样,如果循环体只有一行代码的话,那么大括号就可以省略,但多数程序员仍然会使用大括号来把这一行代码包括在里面。下面这个例子是一个包含C++的while语句的代码片段。这一节里的所有循环示例都会输出从0到9的10个数字: C++还支持一个在Python里没有的do while语句。与while循环不同,do while语句里的代码总是被执行至少一次。和前测循环的语法不同,循环的条件检测在循环体执行之后才会进行,因此do while循环被分类为后测循环(posttest loop)。它的语法是: 如果循环体里只有一行代码的话,do while语句也是不需要用大括号来标记循环体的开头和结尾的。但是,如果循环体里有多行代码的话,就必须要加上大括号了。这个语句的语义是先执行循环体,然后检测布尔表达式。如果条件为真,那么会再去执行一次循环体,之后再去检测布尔表达式,以此往复。对于上面的那个例子,如果用do while语句做同样的功能的话,可以写成: C++里的for循环语句和Python里的for语句有很大的不同。Python里的for语句是对一系列元素进行迭代,但是在C++里,for语句是一个更通用的循环语句。实际上,你可以把它理解为一个类似于while的循环。通过观察下面这个同样输出0~9的10个数字的for语句的例子,你就可以更好地理解C++的for语句了。图8.6所示为这个代码的流程图: 图8.6 C++的for语句的流程图示例 在for语句的括号里有被两个分号分隔开的3个语句。第一个语句i = 0;在for语句中通常都被用来当作初始化语句,而且它也只会被for语句执行一次。在执行完初始化语句之后,将会开始执行第二个语句,这个语句会被当作布尔表达式。如果它的结果为真的话,就去执行循环体,在之后就会去执行第三个语句。第三个语句通常也被称为增量操作(increment action)或者是更新操作(update action)。在我们的例子里,这个增量语句可以使用后缀版本i++,也可以使用前缀版本++i。在这本书里,我们将会像C++的标准模板库里的一样使用前缀版本。在执行了增量操作之后,第二个语句将会被再次执行。如果结果还是真,那么就会再一次执行循环体里的代码,接着再执行一次增量语句,然后检查布尔表达式,如此往复。 就像刚才我们提到过的那样,任何for循环都可以被重写为while循环。如果你还没有看出for循环里的各个语句位置与while循环里的语句之间的对应关系的话,你可以再看看那个流程图,以及比较while循环和for循环的两个代码片段。C++的for语句可以更复杂一些,比如说,可以包含用逗号来分隔的多个初始化语句,以及多个增量语句。在这本书里,我们将不会去展示这些用法。一些程序员认为,如果面对的是很复杂的情况的话,应该使用while语句来处理。 C++的for循环还支持在语句里直接声明循环的迭代变量。如果这样做了,那么这个变量就只能在循环体内部被访问。在循环之外,这个变量将不再存在。下面这个例子展示了这一点: 类似地,如果你在for循环里定义的循环迭代变量和之前已经声明的变量同名的话,那么先前声明的那个变量在循环体内是不可以被访问的,在循环之后才能被访问,而且会保留在循环开始执行之前的那个值。正是因为可能导致混淆,所以我们不建议你使用在for语句里声明变量的这种语法。这个问题是被称为作用域(scope)和生命周期(lifetime)的话题的一部分,我们将会在8.15节里介绍关于C++的变量的作用域和生命周期的详细信息。 和C++里的if、while和do while语句一样,如果循环体只包含一行代码的话,for循环也不需要大括号,但很多程序员仍然会一直使用大括号来包括循环体。和Python一样,C++也支持终止循环的语句——break。就像在Python里我们建议的那样,只有在增加break语句会让循环的可读性提高的时候,才应该使用break语句。 Python里包含允许对一组数据进行索引访问的列表以及元组。Python列表还支持排序、查找元素和许多其他有用的算法等方法。相对而言,C++的数组虽然也支持索引操作,但是它更底层一些,并且也不像Python列表那样具有很好的灵活性。比如说,C++的数组里必须包含相同类型的元素,而且它也不支持切片以及使用负数索引来访问数组末尾的元素。 C++的数组用方括号进行声明,并且使用方括号来进行访问。和Python一样,数组的第一个元素的索引是0,最后一个元素的索引会比数组的尺寸小一个数字。在下面的这个代码片段里声明了一个数组,并且为数组里的每个元素都赋了一个值。这个数组在声明的时候就设置成了等于10的固定大小,里面的元素将会通过索引0~9进行访问,而且这个数组只能存储整数: 最新的C和C++编译器支持用一个变量来指定数组的大小,这种数组被称为可变长自动数组(variable length automatic array,这是20世纪90年代后期,被称为C99的C语言的更新的一部分)。在程序运行之后才去指定数组大小的另一种实现方案是:使用指针和动态内存。这部分内容将在10.3节里介绍。下面这个代码片段展示了可变长自动数组: 与Python不同的是,C++的数组不会对任何索引进行范围检查。也就是说,如果程序试图在超出数组边界的地方进行访问的话,可能会得到无法确定的结果,从而导致程序崩溃,当然也可能会让程序看起来还在正常工作。我们将在第10章里详细地讨论这些关于内存方面的错误。在许多操作系统里,当C++程序崩溃的时候,它是不会像Python那样显示出堆栈跟踪(程序崩溃时所处在的代码行,以及程序执行到那个地方所执行的调用函数的序列)的。大多数的UNIX系统将会创建一个core文件,这个文件里会包含有关执行和崩溃位置的相关信息。在UNIX系统上,gdb调试程序可以通过后面这个命令,显示出存储在core文件里的堆栈跟踪信息。这个命令就是gdb C++也支持像这样的语法:int a[5] = {0, 0, 0, 0, 0};,在声明语句里直接初始化数组。C++并不支持直接对数组变量进行赋值。要实现数组变量的赋值的话,就只能去对数组的每一个元素进行赋值,就像下面这个代码片段里做的一样: C++还支持多维数组,只要系统支持相应的内存空间,这个多维数组的维数并没有任何限制。声明多维数组的语法和声明一维数组的语法是类似的,只不过每一个维度将会使用一对额外的方括号。下面的这个代码片段声明了一个总共包含120个元素的三维数组,并且每个元素都被初始化为了零: 在C++里也可以像C语言那样,用字符(char数据类型)数组来表示字符串。但是,在用C++编程的时候,通常都会使用我们将会在9.2节里介绍的内置的C++字符串(string)类。使用原始的字符数组来表示字符串的时候,字符串的尾部字节将会用零来表示字符串的结尾,因此,这个数组的大小必须要大于你将要存储的最大字符数。这个零字节由一个字符'\0'来表示。在这里要注意的是,单引号被用来表示单个字符(属于char数据类型),而双引号则被用来表示字符串。由于一些C++代码库的函数使用的不是C++的字符串类,而是C语言风格的字符串(字符数组),因此我们将简单介绍一下C语言风格字符串的基础知识。下面这个例子展示了一个使用C语言风格的字符串,它允许你输入你的姓名,然后向你说"Hello"。但是,这个例子非常糟糕,这是因为,在这个例子里,有一个可以被利用的缓冲区溢出漏洞。 如果输入的是Dave的话,程序会把字符D、a、v、e以及\0分别存储在数组的第0~4位。当代码输出变量c的时候,它会从这个数组的开头开始依次输出字符,直到它到达了代表着字符串结尾的\0。如果用户键入的字符超过19个的话,那么输入的数据将会超过数组的末尾,也就是说,它会允许用户将数据写入程序里没有分配给这个数据的内存之中。于是一些聪明的计算机破解程序在某些情况下,会利用这种情况去输入一段可执行代码,从而能够让它们窃取你可能会在程序里输入的密码或者是财务相关的信息这样的私人数据。这也就是我们推荐使用C++的字符串(string)类的另一个原因。正是基于这样的建议,这本书将不会再去介绍关于C语言风格的字符串的其他细节和操作函数。 函数在Python里被用来把代码拆分成较小的子问题,从而避免不断地重复编写相同的代码。在C++里使用函数具有类似的目的,但是在C++里需要考虑有关函数的问题会比在Python里要多一些。就像我们已经看到的那样,所有C++的可执行语句都必须在函数内被执行,并且每个C++可执行程序都必须要包含一个名为main的函数。我们将会使用一些你不会在Python里使用到的术语来讨论C++里的函数。 与Python不同,除了非局部变量、类的定义以及变量或函数的声明之外,所有的C++代码都只能出现在函数的内部。为了能够理解这是为什么,我们就需要先去理解声明(declaration)和定义(definition)之间的区别。区分这两者的一种简单方法是:定义会让内存分配存储空间,而声明只会告诉编译器某个名称的存在及其含义(某种类型的变量、类或是具有参数的函数)。变量、类和函数可以被多次声明,但只能被定义一次。因此,通常所说的变量声明(variable declaration),其实严格上来说是变量定义(variable definition)。即使在函数的开头列出各个变量以及它的类型,也应该被称为变量定义,虽然很多程序员都会把它叫作变量声明。定义也可以被当作声明,这是因为它也告诉了编译器一个名称的存在,但是声明并不是定义。 那么,既然我们已经说明了声明和定义之间的区别,现在让我们来看一个包含函数声明和函数定义的简单例子: 所有的C++函数都必须有一个返回类型(对于main函数,会返回一个int类型)。函数声明里就表示了返回类型、名称以及名称之后的括号里的参数。函数声明以分号结尾,并不包含函数体。因此,函数声明也被称为函数原型(function prototype)。函数声明/原型将会告诉编译器关于这个函数足够多的信息,因此编译器会知道它的存在,并且可以确定在调用这个函数的时候,有没有正确地使用它。函数的定义包含了与声明里相同的信息,但是它没有结尾处的分号,而是使用大括号来包含函数的主体。在我们之前的例子里,我们没有像在刚刚这个例子里那样包含一个main函数的单独声明。在那些例子里,main函数的定义也被当作它的声明。一般来说,除非有其他代码调用这个函数,通常我们都不会去编写函数的单独声明。 除了在8.4节里列出的数据类型,以及将要在9.1节里介绍的用户自定义的数据类型之外,C++还支持void返回类型。void返回类型在函数不会有返回值的时候使用。在以void作为返回类型的函数里,return语句不是必需的,但是也可以包含它。如果一个非void的函数没有返回一个值的话,大多数C++编译器都会产生一个警告,而不会像Python那样,如果函数没有显式地返回一个值,就返回None。和Python类似,C++的函数也可以有多个return语句,而且只要执行了任何一个return语句,这个函数就不会继续执行其他代码,并且控制权会传回给在调用点之后的那个语句。和Python不同的是,C++的函数只能返回一个值。这并不是C++的一个重大缺陷,因为我们可以通过将多个值封装在一个类里,并返回这个类的实例来解决;或者也可以使用引用传递(在8.12.3小节里介绍)来解决需要多个返回值的问题。 通常来说,为了让你的代码能够正常编译,都应该编写函数原型。特别是,如果要在函数声明之前调用这个函数的话,大多数编译器都需要这个函数的函数原型。在调用一个没有被声明的函数的时候需要原型的原因是,编译器必须要确定使用了正确数量的参数去调用这个函数,并且这些参数的类型也是正确的。回想一下你之前学到的Python的相关知识,函数声明或者定义里的参数被称为形参(formal parameter),而调用这个函数时所使用的表达式或变量被称为实参(actual parameter)。下面这个例子展示了在函数声明或者定义之前调用这个函数会导致的问题: 对于这段代码,大多数编译器在c = f(a,b)这一行代码上标错,并提示f未被声明。在这个例子里,有两种方法可以解决这个问题。最简单的方法是在主函数的上面编写f函数,这样一来,函数f的定义也会被当作它的声明。另一种方法则是在主函数之上编写f函数的原型,就像下面这个例子里做的一样: 函数f的原型指出了它的返回类型是一个double(双精度浮点)值,并且它需要两个参数,每个参数都是一个double值。就像例子里的注释代码写的那样,你并不需要给形参提供名称,但如果你愿意加上名称也是可以的。大多数程序员都会指定形参的名称,这是因为参数的名称通常表示着参数所代表的内容。有一个非常重要且需要注意的点是:原型后需要加上分号,但是在定义函数的时候,右括号后面不需要加上分号。另外一点需要注意的是,数据类型的名称必须要放在每个形参的前面,在函数的原型或者实现里写成double f(double x, y)是不正确的。 程序员刚开始用C++写程序时的一个常见错误是:把形参声明成了局部变量,像下面这段代码片段展示的一样。这是不正确的,因为局部变量会阻止对形参的访问。你的C++编译器可能会生成一个警告,提示这个变量会影响参数。有些编译器可能会忽略这个警告,继续编译这个程序,而其他一些编译器则会认为这是一个错误,并且拒绝编译程序: 你可能已经发现了,你引用的头文件里包含的正是你的代码会用到的元素的声明。比如,iostream头文件里包含了cout和cin的声明。但是这些元素的定义并没有包含在这个头文件里。对于cout以及cin来说,它们的定义是在机器代码库里,链接器在创建可执行代码时会自动链接这些定义。我们将在8.13节里介绍如何编写自己的头文件。 C++里参数传递的默认机制是值传递(pass by value)。值传递将为每个参数生成一个单独的数据副本。由于使用了完全独立的副本,因此对函数的形参进行的任何更改都不会反映在实参里。这就允许你把形参视为一个附加的局部变量了,因为对它们所做的修改不会影响到程序的其他部分。和Python一样,形参和实参的名称是否一致并不重要。下面这个例子就说明了这一概念: 这个程序的输出是: C++还支持另一个参数传递的机制,被称为引用传递(pass by reference)。和值传递不同的是,它不会去复制一份数据副本,而是直接传递数据的引用(内存中的地址)。因此,对形参所做的任何改变都会反映在实参上。在Python里,如果把可变数据类型(列表、字典或是类的实例)传递给函数,然后再在函数内部进行修改的话,那么这些更改将会反映在实参里。但是,如果把一个新的实例分配给形参的话,这个改变将不会反映到实参上。对于C++里的引用传递来说,对形参的任何更改(包括分配一个新值)都会直接反映到实参上。要表示参数通过引用传递,只需要在形参(不是实参)前放置&符号就行了。而在实参前面放一个&符号将会有不同的效果(参见10.2节)。下面的例子和前面的例子类似,但是其中的一个参数是通过引用传递的,从而导致了不同的输出结果: 这个程序的输出是: 使用引用传递的任何形参所对应的实参都必须是一个变量,而不能是一个表达式。在这个例子里,我们不能用f(2,4);。生成数字2的副本,并且把它存储在形参a的位置是可以的,但问题在于,如果我们更改形参b的话,我们并没有相应的实参来进行修改(因为它只是一个常数)。 出于对效率的考虑,C++会自动通过引用传递数组,因此你不需要使用&来指定数组通过引用传递。这样,传递的时候就不会去复制整个数组,而是传递一个数组的起始内存地址的副本。因此,函数对数组所做的任何改变都将会反映在传递给函数的数组里。这其实和把Python里的可变类型(比如Python列表)传递给函数是一样的。你只能改变整个数组的内容,但是不能去更改数组使用的内存位置。我们通过后面第10章的学习,在探讨过了关于指针和动态内存相关的内容之后,这部分的细节以及结果将会更加清晰。 你并不需要在数组的形参里指定整个数组的大小,但是,整个函数仍然需要注意在使用的过程中不要超出数组尺寸。一种常见的解决办法是再传递一个指定数组尺寸的附加参数。下面的代码通过选择排序的实现来展示了这一方法。形参(int a[])后面的方括号表示一个不定大小的一维数组将会被传递给它。你也可以根据需要在这个地方指定一个大小尺寸,但整个值在这里会被忽略掉。第二个参数表示了整个数组的大小。由于数组不是值传递的,因此在selection_sort函数里对数组进行的修改也会影响到传递的实参。整个程序的输出(未示出)将会是按照顺序进行排列的数组: 多维数组也可以被传递给函数。但是,除了第一个维度之外的所有维度都必须要指定相应的大小。在C++里,多维数组按照行主序(row-major order)的顺序进行存储。比如说,对于声明为int b[2][3]的数组,它的值在内存中的存储顺序为:b[0][0]、b[0][1]、b[0][2]、b[1][0]、b[1][1]、b[1][2]。为了能够计算出数组中指定位置的内存地址,我们必须要能够知道除了第一个维度之外的所有维度。在上面这个例子里,b[i][j]的位置是从数组的开始处偏移i * 3 * 4 + j * 4个字节。要知道,我们曾经假设过整数会占用4个字节。所以,要移动到第i行,我们就必须要移动i * 3 * 4字节,然后还需要移到这一行里相应的点j,因此,我们必须再移过j * 4字节。后面这个函数原型将会接受一个后两个维度大小分别为10和20的三维数组:void f(int b[][10][20],int size);。正是因为不需要第一维的维度来计算元素在数组中的位置的内存地址,所以在形参的数组声明中不需要指定它,同时size参数将会被用来指示第一个维度的尺寸。因此,这个函数里的代码是能够知道作为实参传递的数组的大小的。 C++里支持把参数标记为常量(const),这意味着函数不能更改这个参数。这个功能对于让编译器去检查你的代码里是否意外地去尝试了修改这个参数时非常有用。如果你的代码真的修改了标记为const的参数,那么这个代码将无法通过编译,并且会生成错误来告诉你相应的原因。以下示例演示了语法: const标记也可以和通过引用进行传递的参数一起使用。乍一看,这可能非常矛盾,因为当我们想要修改这个参数的时候,才会使用引用传递。回想一下,按值传递会传递一个数据的副本。制作一个像int或double类型这样的不需要太多内存的副本不是什么问题,但是,如果需要复制一个包含成百上千字节的变量,需要花费大量的时间,并且还需要大量额外的内存。使用引用传递的话,会把变量的起始地址作为对现有数据的引用进行传递,而不会去复制整个数据。并且,无论整个数据的实际大小是多少,在32位的系统上,都只需要4字节。因此,如果要传递一个大型的数据结构,又不希望函数去改变它的话,就可以使用const标记来通过引用传递整个数据结构。下面这个例子里,假设我们已经定义了一个名为LargeType的类: 这也是Python把所有的数据都视为引用的一个原因。赋值、传递以及返回任何对象的时候,都只需要引用(可能还会有引用计数),而不用去复制像列表或者字典对象里潜在的大量数据。 和Python类似,C++也在函数里支持默认参数。默认参数允许使用比形参更少的实参来调用整个函数或方法。在函数/方法的声明里定义的默认值将会被用来代替缺少的实参。下面这个例子展示了默认参数的使用方法: 这个例子里有两个必须要始终指定的参数以及两个默认参数。因此,这个函数允许使用两个、3个或者4个参数来调用。就像在注释代码里描述的那样,当需要的时候,参数的默认值将会被使用。与Python一样,默认参数必须是最后的几个参数,只有这样编译器才可以根据顺序来匹配实参和形参。默认值只会在函数的声明里,而不是在函数的定义里被指定。除非函数的定义也同时是它的声明,那么在这种情况下你就需要像前面我们说的那样去设置它们。下面这个例子展示了当函数的声明和定义同时存在时,应该如何使用默认参数,我们将在8.13节里展示另一个和头文件相关的默认参数的例子: 在Python里,你可以使用* args传递任意数量的参数,但在C++里,这个情况非常复杂,超出了这本书的范围。 头文件的用处是声明各个函数、类(类相关的内容将在9.1节里介绍)以及非局部变量,从而能够让它们在其他的C++源文件里被使用。在我们之前的例子里包含了iostream头文件,现在让我们来看看应该如何编写自己的头文件。我们将用排序算法作为例子来展示它。我们将首先在头文件里声明两个不同的排序函数: 这段代码首先需要注意的是,我们添加了一些新的预处理器命令。之前我们曾经提到过,预处理器命令是以井号(#)开头的。在这个代码里的ifndef行将会去检查是否已经定义了符号__SORT__H。如果没有的话,那么在下一行就会定义符号__SORT__H,接下来就是我们的函数声明。如果已经定义了这个符号,那么在包含这个文件的时候,将不会复制代码行#ifndef到#endif之间的代码。使用这些预处理器命令是防止头文件被包含两次的标准方法。多次包含一个只含有声明的头文件并不会产生错误,但会降低编译速度,因为编译器需要处理更多行代码。并且,如果包含了多次含有定义的头文件(比如说类的头文件)的话,也会出现问题,因为一个名称只能有一个定义。 虽然在一个文件里并不会直接包含某个文件两次,但是头文件通常也可能包含着其他的头文件。因此,如果你的头文件包含了文件 sort.cpp文件通常会包含sort.h文件,尽管在这个例子里这两个函数都不会调用另一个,因而并不需要这么做。sort.cpp文件看起来就应该是: 如果一个文件想要调用我们这两个排序函数的话,就需要包含头文件sort.h并且与编译器生成的sort.o文件进行链接。要注意的是,我们并没有将merge函数放在头文件里,这是因为它只会被merge_sort函数调用。下面,让我们用一个简单的例子来使用上面的排序算法。你可以使用8.6节里列出的g++命令在UNIX系统上编译并链接这3个文件: 让我们来看看另一个头文件的示例,它能够让我们了解到在使用默认参数值的时候会经常犯的一个错误。让我们来编写几个函数进行温度转换,并且把它们放在一个单独的文件里,这样许多其他程序就都可以轻松地使用它们了。我们的头文件和实现文件将会像下面这样: 这个常见的错误是:把函数声明直接从头文件里复制并粘贴到实现文件里去。这样做会导致在实现文件里也指定了默认参数的值。在例子里,我们通过注释掉了不正确的代码行,并且添加了没有默认值的正确行来显示了这一点。如果在从头文件复制粘贴函数原型的时候忘记了在实现文件里删除默认值的话,C++编译器将给出一个出错消息。 由于这些函数的代码都很短,因此,如果进行函数调用的话,调用函数可能会比执行实际函数代码要花费更多的执行时间。C++提供了一种被称为内联函数(inline function)的机制,从而实现更高效的函数执行。内联函数通常会直接写在头文件里,并且它的写法与函数在实现文件中的编写是完全相同的。唯一的不同是,它会在函数定义之前放一个关键字inline。这样一来,它既是一个定义同时也是一个声明。对于我们的温度转换这个例子来说,使用内联函数的头文件会像下面这样: 当在头文件里编写了所有的内联函数之后,因为所有信息都包含在头文件之中,所以你就不再需要那个实现(conversion.cpp)文件了。当有多个文件都包含了conversion.h头文件的时候,inline关键字可以避免函数被创建多个定义。 而且,如果你的内联函数相对较短的话,编译器将生成这段函数体的机器代码,并且把这部分机器代码直接放在代码里,而不会去创建调用这个函数的相关代码。但是,如果你的函数比较长的话,编译器将会忽略掉你的内联指令,不仅如此,它还会创建一个普通的函数调用来调用这个函数。因为,如果有很多不同的地方都调用这个函数的话,复制这个比较长的函数的机器代码到各个地方,将会使得整个程序变得更大。一般来说,少于5行的函数都可以声明为内联函数。 最初的时候,C语言并不支持内联函数,因此,为了实现让短函数不去创建函数调用的相同结果,会使用预处理器宏来定义这些函数。C++里也支持宏(macro)命令,因为它也属于C语言,但是,我们还是建议你使用内联函数,因为它会强制执行类型检查,更加安全。下面这段代码为c_to_f定义了宏,并且使用了宏: #define预处理器命令被用来定义宏。预处理器将会执行搜索,然后替换括号里的元素。那么,基于这样的逻辑,你认为这段代码的输出应该是什么? 那两行使用宏的代码将会被预处理器扩展为: 基于这样的扩展,你应该可以知道为什么这个程序的输出是50 60了。而我们期望的输出,20摄氏度的正确转换应该是68华氏度。你可以通过在宏里添加更多的括号来解决这个问题,但是,宏仍有其他的潜在问题。因此,在编写C++代码时,你应该使用inline关键字而不是用宏来避免函数调用的相关开销。 在命名空间和头文件之间,还有一个重要问题。对于头文件来说,你不应该使用using namespace ...这样的代码来使用任何一个命名空间。如果你这样做的话,那么任何包含这个头文件的文件都会被using namespace语句所影响。因此,当源文件定义了一个在这个指定的命名空间里也定义过的名称,就会导致问题发生。所以,如果你需要在头文件里使用一个被定义在名称空间里的名称的话,请不要在头文件里包含using语句,而是始终使用namespace::name这样的语法来引用它。我们将在9.4节里看到一个关于这点的例子。 就像Python包含了许多很有用的功能模块那样,C++也提供了一个标准的函数库。我们已经看到过在C++语言里用来包含输入和输出代码库的iostream头文件。C++里提供的许多函数都是最初的C语言标准库的一部分,当然这些头文件也专门为C++进行了更新。C语言代码库的一些头文件被叫作stdio.h、stdlib.h以及math.h。要在C++程序里使用这些头文件的话,就需要删除扩展名.h,并且在开头添加字母c。因此,相应的名称就是cstdio、cstdlib以及cmath。例如,要使用C语言的math头文件里定义的sqrt函数的话,就需要在C++文件的顶部添加这样一行语句:#include 一个标准约定是,对于C++代码库的头文件,以及常见的位于标准目录里的代码库,使用小于号和大于号把它们的头文件的名称包括起来。你的C++编译器还提供了一种可以指定要去检索的其他目录的方法。一般来说,在大多数系统里,编译器会首先检索你指定的其他目录,然后检索包含头文件的一组标准目录。在这个检索过程中,第一个与名称匹配的头文件将会被使用。当头文件与正在编译的C++源文件位于同一目录的时候,你必须在头文件的名字两边使用双引号。对于使用双引号指定的头文件,编译器将会首先检索当前目录。如果编译器在当前目录中找不到头文件,那么编译器将检索用户指定的其他的包含目录以及标准目录。对于当前目录里的头文件,你不能使用小于号和大于号来表示它,因为这样的语法在默认情况下是不会去检索当前目录的。但是,你可以在包含的标准头文件两侧使用双引号,因为这样写会去检索当前目录以及标准目录。虽然可以在任何情况下都使用双引号,但是通常来说,C++程序员都会遵循对于标准头文件使用小于号和大于号这样的约定。 与内置了单元测试框架的Python不同的是,标准C++语言并不包括任何单元测试框架。好在你可以下载安装许多第三方的C++单元测试框架。大多数(甚至可能是全部的)这些框架都与Python的单元测试框架是类似的,这是因为,C++和Python的单元测试框架都是基于Java的单元测试框架的。在这里,我们将会讨论C++的断言(assert)语句,而不去覆盖更多的C++单元测试框架,因为断言语句也能允许你轻松编写单元测试。 Python的单元测试框架提供了许多方法来验证某些条件是否为真,并将“assert”作为其名称中的一部分(例如,assertEquals和assertRaises)。这些方法其实都是基于C++的断言(assert)语句(严格来说,是一个被预处理器扩展了的宏),而这个C++的断言(assert)语句采用的是布尔表达式。如果这个布尔表达式为真,那么程序会继续执行下去;但如果为假的话,那么程序就会立即退出,并标记出assert语句失败的代码行。C++的断言(assert)语句与Python的单元测试框架不同的是:Python单元测试框架在其中一个测试失败之后,还会继续运行其他测试,但是使用C++的assert语句则会导致程序在断言不成立的时候立即退出。也就是说,不会去执行失败的断言语句之后的任何测试。 在这里,我们将会修改8.13节里的test_sort.cpp文件来使用assert宏命令。assert宏将会接受一个表达式,并且对这个表达式的值进行判断。如果这个表达式的计算结果为真的话,那么就会继续执行;如果这个表达式的计算结果为假,程序就会立即退出,并且输出一条错误消息,来指出包含失败的那个断言的代码行: 要使用C++的assert宏的话,就必须要包含cassert头文件。Python的单元测试框架会指示出测试通过与否,但是C++里是不一样的,如果所有测试都通过的话,使用这个简单的方法来做的测试将不会产生任何输出。如果你需要输出,那么可以就像我们在上面这个例子里做的那样,在每个assert语句之后或者在一组assert语句之后放一条输出语句,表示相应的测试已经通过了。在输出的时候需要记住的是,输出会被操作系统先放在缓冲区,如果程序在操作系统将缓冲区的输出内容发送到屏幕之前就崩溃了,那么你可能就不会看见任何输出。所以,需要使用endl来输出一个新行,并且强制刷新缓冲区。因此,在测试代码的时候,始终需要在输出语句的末尾使用endl。 如果你要测试许多的函数或者类方法的话,你可能应该创建单独的测试函数来测试每一个方法,然后在main函数里调用这些测试函数。这就像使用Python单元测试框架那样,会调用所有以test这4个字符开头的方法。 本文截选自《数据结构和算法(Python和C++语言描述)》 本书使用Python和C++两种编程语言来介绍数据结构。全书内容共15章。书中首先介绍了抽象与分析、数据的抽象等数据结构的基本原理和知识,然后结合Python的特点介绍了容器类、链式结构和迭代器、堆栈和队列、递归、树;随后,简单介绍了C++语言的知识,并进一步讲解了C++类、C++的动态内存、C++的链式结构、C++模板、堆、平衡树和散列表、图等内容;最后对算法技术进行了总结。每章最后给出了一些练习题和编程练习,帮助读者复习巩固所学的知识。 本书适合作为高等院校计算机相关专业数据结构课程的教材和参考书,也适合对数据结构感兴趣的读者学习参考。 //␣ctof.cpp
#include␣
// input1.cpp
#include
// input2.cpp
#include
8.6 编译


8.7 表达式和运算符优先级
// swap.cpp
#include
3 5
5 3
// uninit.cpp
#include
// increment.cpp
#include
8.8 条件语句
// if1.cpp
#include
than y
the end
// if2.cpp
#include
the end
// if3.cpp
#include
if (x < y)
if (y < z)
cout << "a";
else
cout << "b";
if (x < y) {
if (y < z)
cout << "a";
}
else
cout << "b";
// grades.cpp
#include
8.9 数据类型转换
b = 3
c = 2.5
c = b + c
d = float(b)
e = int(c)
int b, e;
double c, d;
b = 3;
c = 2.5;
c = b + c; // c holds 5.5
d = double(b); // d holds 3.0
e = int(c); // e holds 5; this could also be written as e = (int) c;
int b, e;
double c, d;
b = 3;
c = 2.5;
c = b + c; // c holds 5.5
d = static_cast
8.10 循环语句
int i = 0;
while (i < 10) {
cout << i << endl;
i += 1;
}
do {
// loop body
} while (
int i = 0;
do {
cout << i << endl;
i += 1;
} while (i < 10);
int i;
for (i = 0; i < 10; ++i) {
cout << i << endl;
}

for (int i = 0; i < 10; ++i) {
cout << i << endl;
}
// you cannot access the variable i here
8.11 数组
8.11.1 一维数组
int i, a[10];
for (i = 0; i < 10; ++i) {
a[i] = i;
}
int i, n;
cout << "Enter size: ";
cin >> n;
int a[n];
for (i = 0; i < n; ++i) {
a[i] = i;
}
int i, a[5], b[5];
a[0] = 0; a[1] = 1; a[2] = 2; a[3] = 3; a[4] = 4;
// b = a; cannot be used
for (i = 0; i < 5; ++i) {
b[i] = a[i];
}
8.11.2 多维数组
double a[4][10][3];
int i, j, k;
for (i=0; i<4; ++i) {
for (j=0; j<10; ++j) {
for (k=0; k<3; ++k) {
a[i][j][k] = 0.0;
}
}
}
8.11.3 字符数组
// buffer.cpp
#include
8.12 函数的细节
8.12.1 声明、定义以及原型
#include
// this example will not compile
int main()
{
double a=2.5, b=3.0, c;
// the compiler has not yet seen the f function
// so it cannot determine if f is called correctly
c = f(a, b);
}
double f(double x, double y)
{
return x * x + 2 * x * y;
}
double f(double x, double y);
// you do not need to list the formal parameter names in the prototype
// this example also shows you that you can declare a function multiple
// times even though you generally do not do this
double f(double, double);
int main()
{
double a=2.5, b=3.0, c;
// the prototype allows the compiler to determine
// that f is called correctly
c = f(a, b);
}
double f(double x, double y)
{
return x * x + 2 * x * y;
}
#include
8.12.2 值传递
// value.cpp
#include
1 2
4 7
1 2
8.12.3 引用传递
// reference.cpp
#include
1 2
4 7
1 7
8.12.4 将数组作为参数传递
// selection.cpp
#include
8.12.5 常量参数
void f(const int a, int b)
{
a = 2; // this will generate a compiler error
b = 2; // this is fine
}
void f(const LargeType&big)
{
// any changes to parameter big will generate a compiler error
}
8.12.6 默认参数
void f(int a, int b, int c = 2, int d = 3)
{
// do something with the parameters
}
int main()
{
f(0, 1); // equivalent to f(0, 1, 2, 3);
f(4, 5, 6); // equivalent to f(4, 5, 6, 3);
f(4, 5, 6, 7); // no default values used
}
double f(double x=0, double y=0);
double f(double x, double y)
{
return x * x + 2 * x * y;
}
int main()
{
double x=2.5, y=3.0, z;
z = f(x, y);
}
8.13 头文件和内联函数
// sort.h
#ifndef __SORT__H
#define __SORT__H
void selection_sort(int a[], int size);
void merge_sort(int a[], int size);
#endif
// sort.cpp
#include "sort.h"
void selection_sort(int a[], int size)
{
// code for selection_sort function
}
void merge(int a[], int low, int mid, int high)
{
// code for merge function
}
void merge_sort(int a[], int size)
{
// code for merge_sort function
}
// test_sort.cpp
#include
// conversions.h
#ifndef __CONVERSIONS_H
#define __CONVERSIONS_H
double f_to_c(double f=0.0);
double c_to_f(double c=0.0);
#endif
// conversions.cpp
#include "conversions.h"
// the next line is commented out since it is incorrect
// double f_to_c(double f=0.0)
double f_to_c(double f)
{
return (f - 32.0) * (5.0 / 9.0);
}
double c_to_f(double c)
{
return (9.0 / 5.0) * c + 32.0;
}
// conversions2.h
#ifndef __CONVERSIONS_H
#define __CONVERSIONS_H
inline double f_to_c(double f=0.0)
{
return (f - 32.0) * (5.0 / 9.0);
}
inline double c_to_f(double c=0.0)
{
return (9.0 / 5.0) * c + 32.0;
}
#endif
// macro.cpp
#include
cout << (9.0 / 5.0) * x + 32.0 << " ";
cout << (9.0 / 5.0) * x + 10 + 32.0 << endl;
8.14 断言与测试
// test_sort2.cpp
#include
