实验笔记之——Channel Attention(RCAN的复现)
实验python train.py -opt options/train/train_sr.json
先激活虚拟环境source activate pytorch
tensorboard --logdir tb_logger/ --port 6008
浏览器打开http://172.20.36.203:6008/#scalars
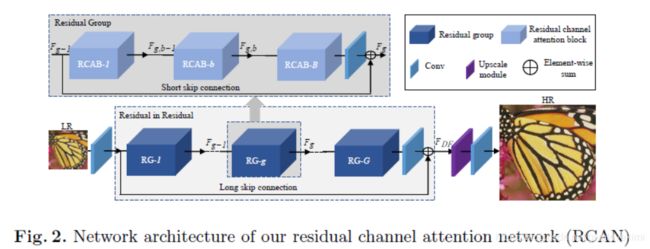
首先给出论文《Image Super-Resolution Using Very Deep Residual Channel Attention Networks》的复现代码
class RCAN_8F(nn.Module):
def __init__(self, in_nc=1, out_nc=1, nf=16, ng=5, nb=5, reduction=8, upscale=2, norm_type=None,
act_type='prelu', mode='NAC', res_scale=1.0):
super(RCAN_8F, self).__init__()
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
self.fea_conv = B.MF8IMGDB(in_nc, nf // 8)
CA_blocks = [B.ResidualGroupBlock(nf, nb, kernel_size=3, reduction=reduction, norm_type=norm_type, \
act_type=act_type, mode=mode, res_scale=res_scale) for _ in range(ng)]
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=None, mode=mode)
self.body_conv = B.ShortcutBlock(B.sequential(*CA_blocks, LR_conv))
self.res_module = B.Res_Module_ch16()
self.P_conv = B.conv_block(nf, 4, kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
self.subpixel_up = nn.PixelShuffle(upscale)
def forward(self, x, mask):
x = self.fea_conv(x)
x = self.body_conv(x)
x = self.res_module(x, mask)
x = self.P_conv(x)
x = self.subpixel_up(x)
return x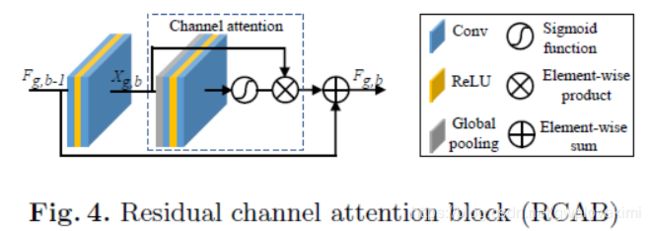
class ResidualGroupBlock(nn.Module):
## Residual Group (RG)
def __init__(self, nf, nb, kernel_size=3, reduction=16, stride=1, dilation=1, groups=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='CNA', res_scale=1):
super(ResidualGroupBlock, self).__init__()
group = [RCAB(nf, kernel_size, reduction, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode, res_scale) for _ in range(nb)]
conv = conv_block(nf, nf, kernel_size, stride, dilation, groups, bias, pad_type, \
norm_type, None, mode)
self.res = sequential(*group, conv)
self.res_scale = res_scale
def forward(self, x):
res = self.res(x).mul(self.res_scale)
return x + resclass RCAB(nn.Module):
## Residual Channel Attention Block (RCAB)
def __init__(self, nf, kernel_size=3, reduction=16, stride=1, dilation=1, groups=1, bias=True, \
pad_type='zero', norm_type=None, act_type='relu', mode='CNA', res_scale=1):
super(RCAB, self).__init__()
self.res = sequential(
conv_block(nf, nf, kernel_size, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode),
conv_block(nf, nf, kernel_size, stride, dilation, groups, bias, pad_type, \
norm_type, None, mode),
CALayer(nf, reduction, stride, dilation, groups, bias, pad_type, norm_type, act_type, mode)
)
self.res_scale = res_scale
def forward(self, x):
res = self.res(x).mul(self.res_scale)
return x + resclass CALayer(nn.Module):
# Channel Attention (CA) Layer
def __init__(self, channel, reduction=16, stride=1, dilation=1, groups=1, \
bias=True, pad_type='zero', norm_type=None, act_type='relu', mode='CNA'):
super(CALayer, self).__init__()
# feature channel downscale and upscale --> channel weight
self.attention = sequential(
nn.AdaptiveAvgPool2d(1),
conv_block(channel, channel // reduction, 1, stride, dilation, groups, bias, pad_type, \
norm_type, act_type, mode),
conv_block(channel // reduction, channel, 1, stride, dilation, groups, bias, pad_type, \
norm_type, None, mode),
nn.Sigmoid())
def forward(self, x):
return x * self.attention(x)setting

##############################################################################################
#RCAN
class RCAN(nn.Module):
def __init__(self, in_nc, out_nc, nf=64, ng=10, nb=20, reduction=16, upscale=4,alpha=0.75, norm_type='batch', act_type='relu', \
mode='NAC', res_scale=1, upsample_mode='upconv'):
super(RCAN, self).__init__()
n_upscale = int(math.log(upscale, 2))
if upscale == 3:
n_upscale = 1
self.fea_conv = B.conv_block(in_nc, nf, kernel_size=3, norm_type=None, act_type='relu', mode='CNA')
CA_blocks = [B.ResidualGroupBlock(nf, nb, kernel_size=3, reduction=reduction, norm_type=norm_type, \
act_type=act_type, mode=mode, res_scale=res_scale) for _ in range(ng)]
LR_conv = B.conv_block(nf, nf, kernel_size=3, norm_type=None, act_type=None, mode=mode)
self.body_conv = B.ShortcutBlock(B.sequential(*CA_blocks, LR_conv))
self.P_conv = B.conv_block(nf, in_nc*(upscale ** 2), kernel_size=3, norm_type=norm_type, act_type=None, mode=mode)
self.subpixel_up = nn.PixelShuffle(upscale)
def forward(self, x):
x = self.fea_conv(x)
x = self.body_conv(x)
x = self.P_conv(x)
x = self.subpixel_up(x)
return x实验结果:
